Accessing Public Datasets in BigQuery
Prerequisites
Open the Cloud Console.
Open Menu > Big Query > SQL Workspace
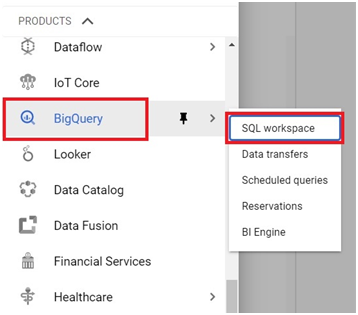
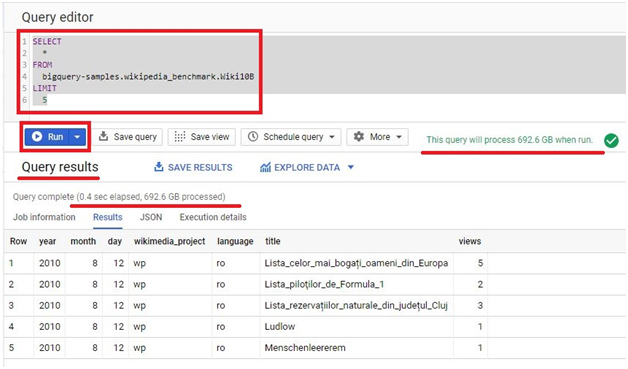
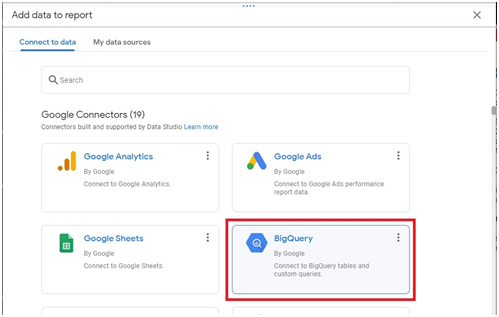
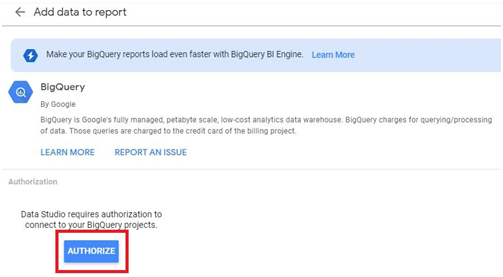
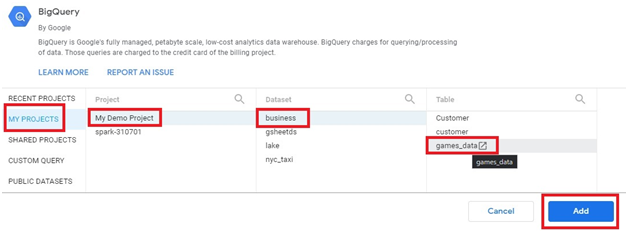
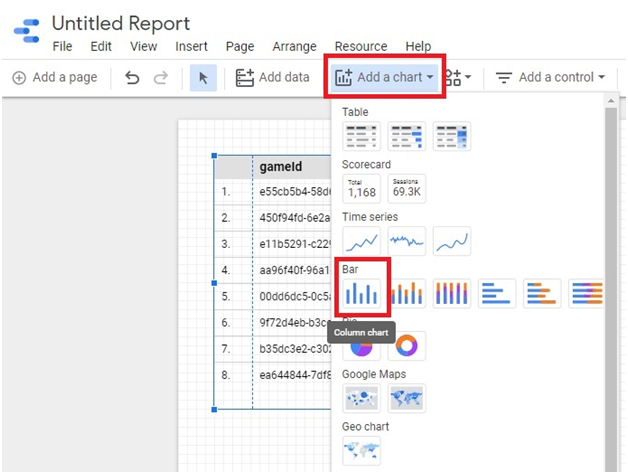
Click on Add Data > Explore Public Data sets.
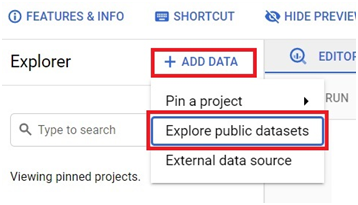
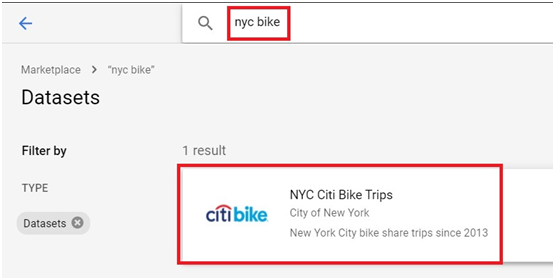
Type NYC bike.
It will show New York citi bike trips data. Click it.
Click on View dataset.
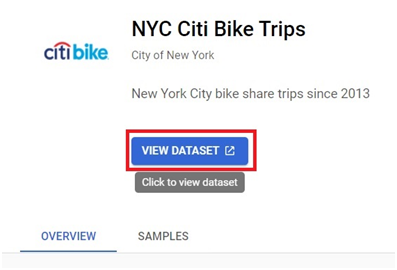
The dataset will be added.
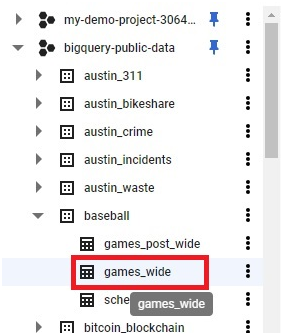
Expand the added data set
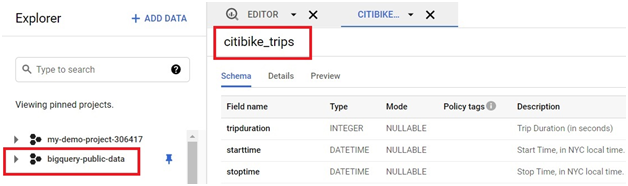
Goto new_york_citibike > citibike_trips
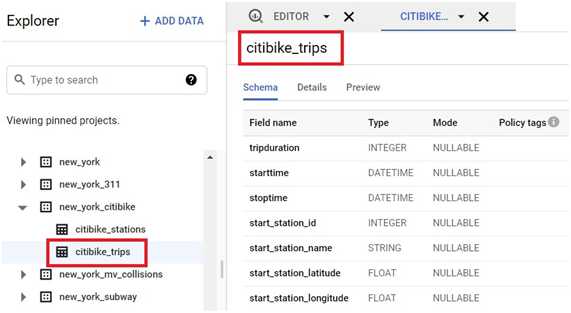
Click on Schema. It will show the schema of table.
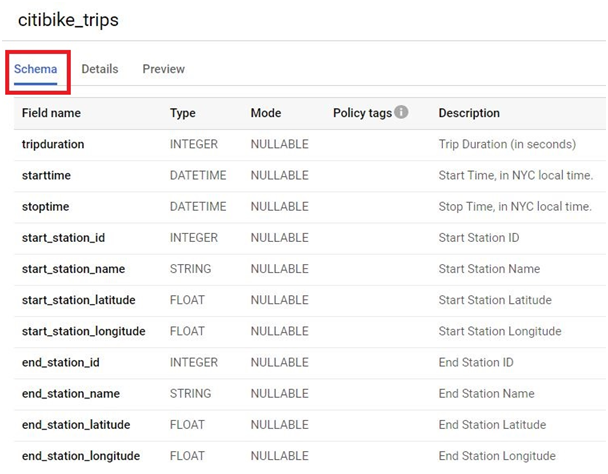
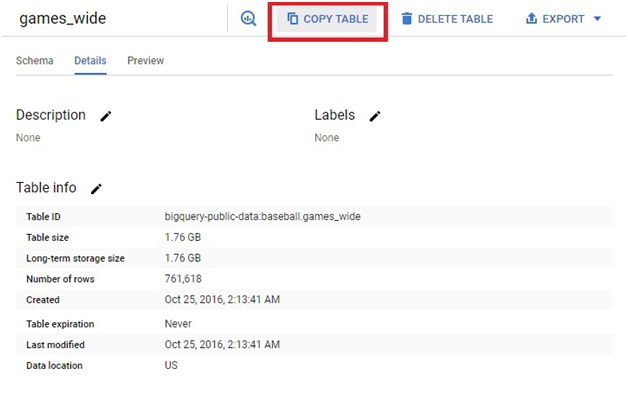
Click on Details. It will show the details of the Table.
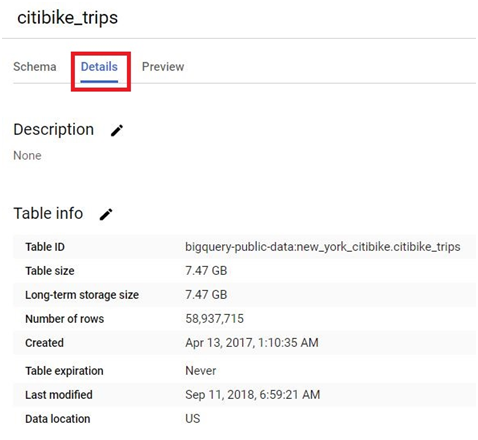
Click on Preview. It will show the table.
Click on Compose new Query.
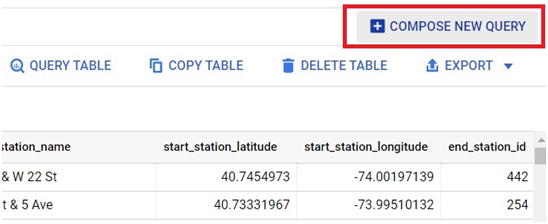
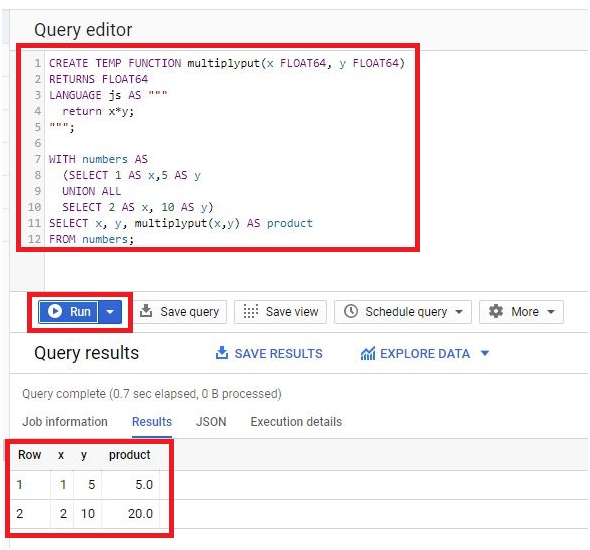
Paste the below code in query editor.
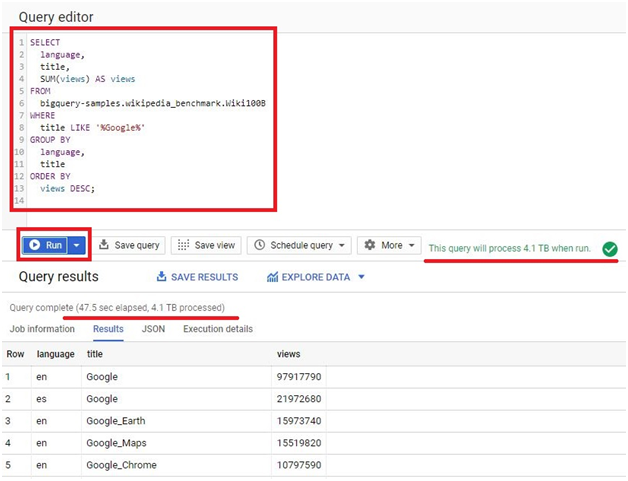
SELECT
MIN(start_station_name) AS start_station_name,
MIN(end_station_name) AS end_station_name,
COUNT(tripduration) AS num_trips
FROM
bigquery-public-data.new_york_citibike.citibike_trips
WHERE
start_station_id != end_station_id
GROUP BY
start_station_id,
end_station_id
ORDER BY
num_trips DESC
LIMIT
10
Click RUN
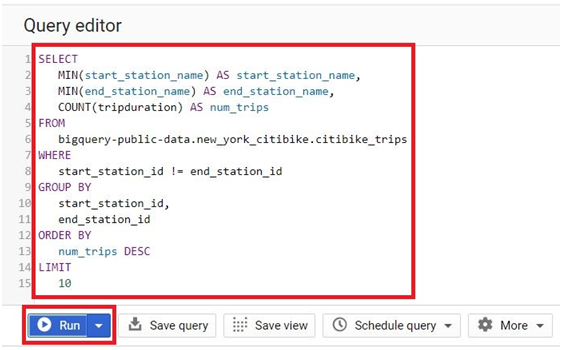
It will show the Results of query.
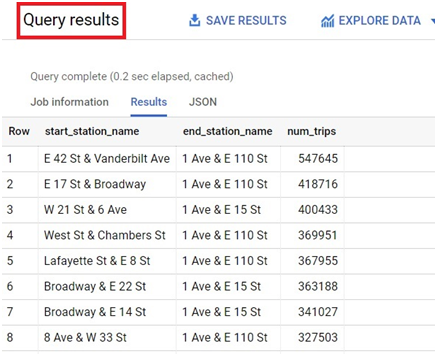
Click on Query history. It will show the query history.
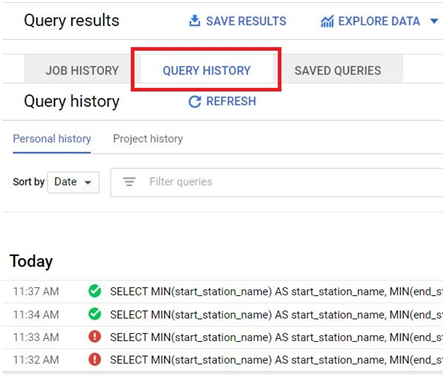
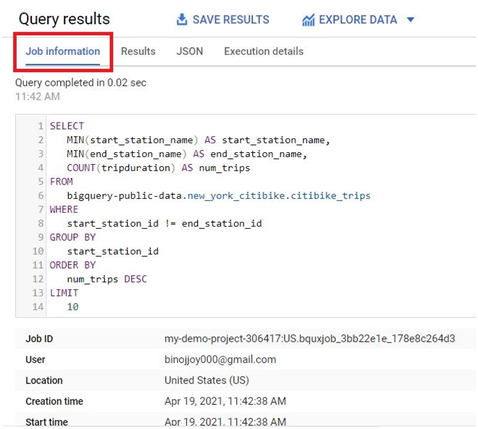
Click on Job Information.
It will show the job description.
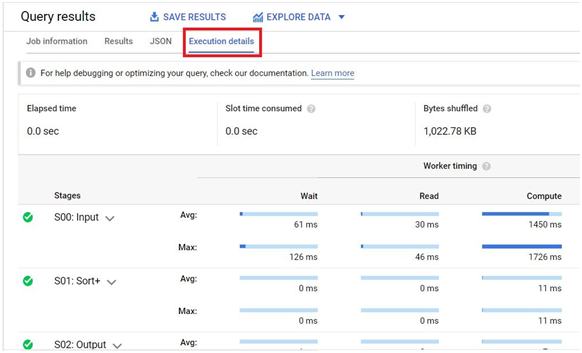
Click on Execution Details. It will Show the execution details
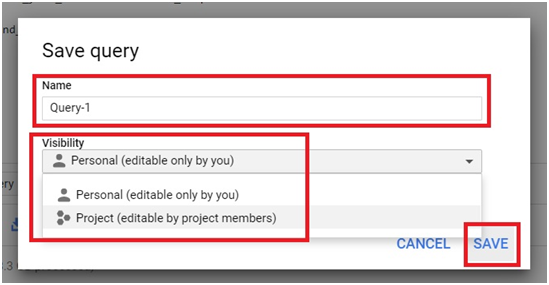
To save Query,
Click on Save Query button.

Give the query name.
Choose the visibility mode. Click Save.
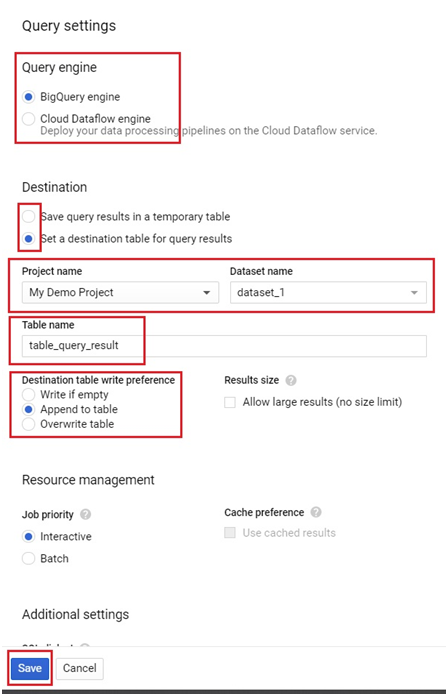
To see the Query settings, Click on More > Query Settings.
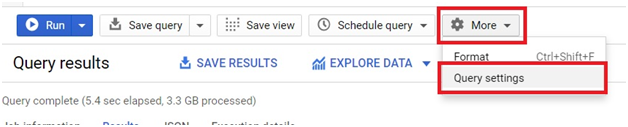
In Query settings, you can choose the engine for query.
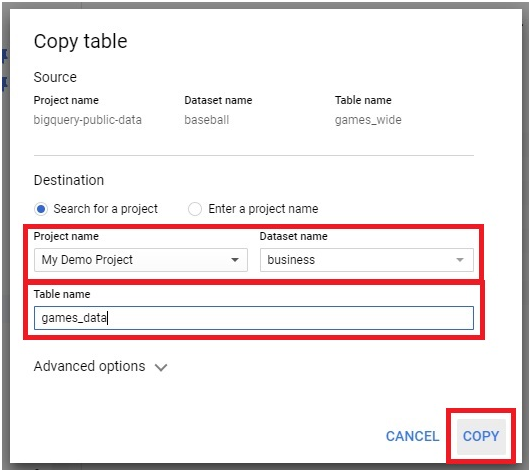
You can change the destination for your query result. Instead of temporary table, you can choose a table in the project itself.
Select the destination table for query dataset.
Choose the project and dataset.
Give the table name and write preference.
Click Save.
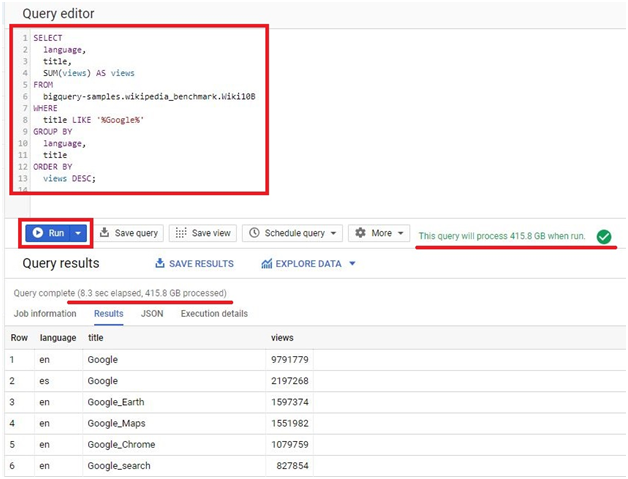
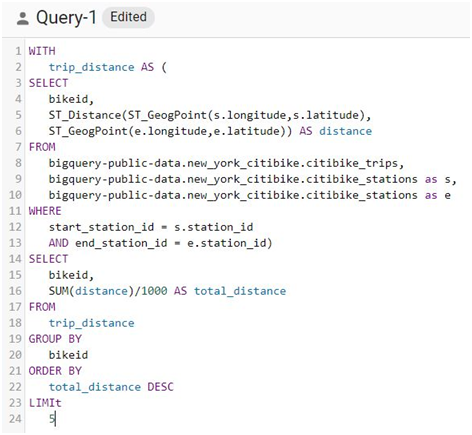
Write the below query.
WITH
trip_distance AS (
SELECT
bikeid,
ST_Distance(ST_GeogPoint(s.longitude,s.latitude),
ST_GeogPoint(e.longitude,e.latitude)) AS distance
FROM
bigquery-public-data.new_york_citibike.citibike_trips,
bigquery-public-data.new_york_citibike.citibike_stations as s,
bigquery-public-data.new_york_citibike.citibike_stations as e
WHERE
start_station_id = s.station_id
AND end_station_id = e.station_id)
SELECT
bikeid,
SUM(distance)/1000 AS total_distance
FROM
trip_distance
GROUP BY
bikeid
ORDER BY
total_distance DESC
LIMIt
5
Click Run.
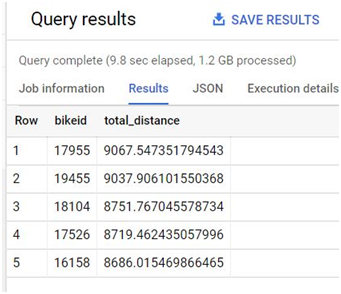
The result of query will be displayed in query results. It will be saved into new table named table_query_result
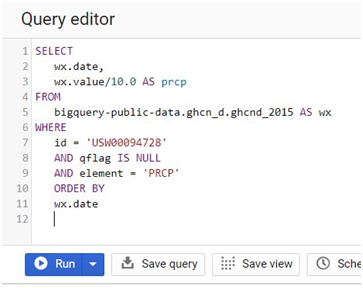
SELECT
wx.date,
wx.value/10.0 AS prcp
FROM
bigquery-public-data.ghcn_d.ghcnd_2015 AS wx
WHERE
id = ‘USW00094728’
AND qflag IS NULL
AND element = ‘PRCP’
ORDER BY
wx.date
Click Run.
The query results will be displayed.