Cassandra Architecture
Architecture of Apache Cassandra
Cassandra is designed to handle big data. Cassandra’s main objective is to store data over multiple nodes without single point of failure.
Just because the hardware failure can occur at any time. Any node can be destroyed. In case of any failure data stored in another node can be used.
Hence, Cassandra is designed with its distributed architecture.
Cassandra stores data over different nodes with a peer to peer distributed fashion architecture.
All the nodes exchange information with each other using a protocol known as Gossip.
Gossip is a protocol in Cassandra by which nodes can communicate with each other.
Components of Cassandra:
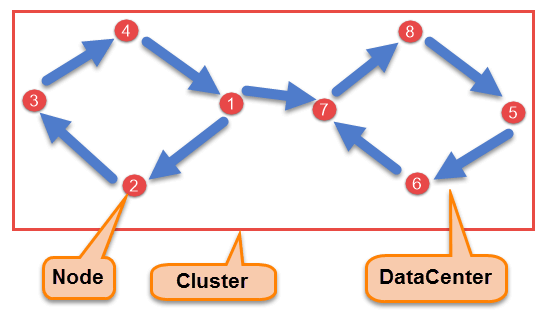
- Node: Node is the place where data is stored.
- Data Center: A collection of nodes are known as data center. Many nodes are categorized as a data center.
- Cluster: The cluster is a collection of many data centers.
- Commit Log: Every write operation is written to Commit Log. Commit log is used for crash recovery.
- Mem-table: After data written in Commit log, data is written in Mem-table. Data is written in Mem-table temporarily.
- SSTable: When Mem-table reaches a certain threshold, data is flushed to an SSTable disk file.
Data Replication
As hardware failure may occur or links may get down at any time during data process, a solution is needed to provide a backup when a problem occurs. Hence, data is replicated for assuring no single point of failure.
Cassandra places replicas of data on different nodes based on these two factors.
- Where to place next replica is determined by the Replication Strategy.
- While the total number of replicas placed over different nodes is identified by the Replication Factor.
One Replication factor means that there is only a single copy of data while three replication factor means that there are three copies of the data on three different nodes.
For ensuring there is no single point of failure, replication factor must be three.
There are two kinds of replication strategies in Cassandra
- SimpleStrategy:
SimpleStrategy is used when you are having just one data center. SimpleStrategy places the first replica on a node selected by the petitioner.
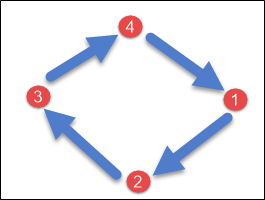
After that, remaining replicas are placed in clockwise direction in the Node ring.
-
NetworkTopologyStrategy:
- NetworkTopologyStrategy is used when you are having more than two data centers.
- In NetworkTopologyStrategy, replicas are set for every data center separately.
- NetworkTopologyStrategy places replicas in the clockwise direction in ring until reaches the 1st node in another rack.
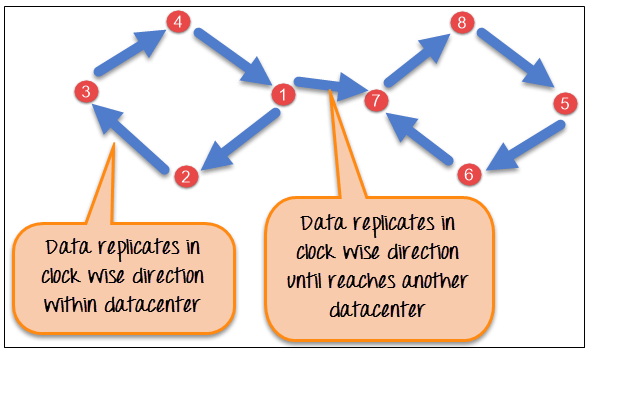
- This strategy tries to place replicas over different racks in the same data center.
- This is due to the reason that sometimes failure or problem can occur in the rack.
- Then replicas on other nodes can provide data.






