Introduction to Hadoop MapReduce
MapReduce Tutorial – Apache Hadoop
Introduction to Hadoop MapReduce, Welcome to the world of Hadoop MapReduce Tutorials. In these Tutorials, one can explore Introduction to Hadoop MapReduce and Hadoop MapReduce data flow Process. Learn More advanced Tutorials on how a MapReduce works by taking an example from India’s Leading Hadoop Training institute which Provides advanced Hadoop Course for those tech enthusiasts who wanted to explore the technology from scratch to advanced level like a Pro.
We Prwatech the Pioneers of Hadoop Training offering advanced certification course and Introduction to Hadoop MapReduce to those who are keen to explore the technology under the World-class Training Environment.
What is MapReduce?
MapReduce is a programming framework that allows users to perform parallel and distributed processing of large data sets in a distributed environment. MapReduce is divided into two basic tasks:
- Mapper
- Reducer
Mapper and Reducer both work in sequence. First the job is being passed through mapper part and then it’s being passed on to Reducer for further execution.
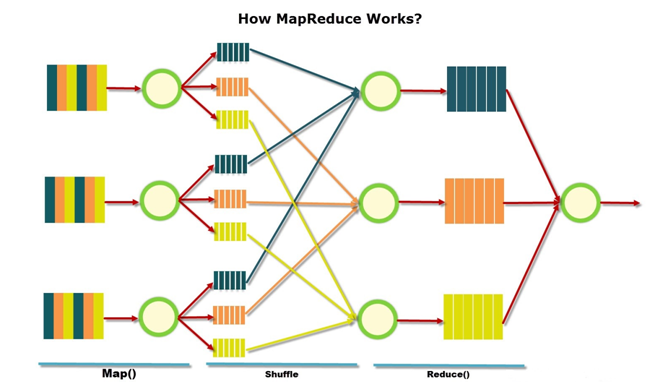
How MapReduce Works?
The MapReduce algorithm contains two important tasks, namely Map and Reduce.
The Map task takes a set of data and converts it into another set of data, where individual elements are broken down into tuples (key-value pairs).
The Reduce task takes the output from the Map as an input and combines those data tuples (key-value pairs) into a smaller set of tuples.
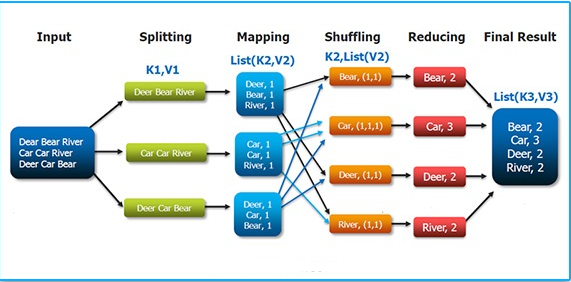
INPUT AND OUTPUT:
MapReduce takes input in the form of Keys and value.
Input and Output types of a MapReduce job:
(input) <k1, v1> -> map -> <k2, v2> -> shuffle and sorting -> <k2, v2> -> reduce -> <k3, v3> (output)
Mapper
The Mapper maps input key/value pairs to a set of intermediate key/value pairs. Mapper works in three phases:
Phase I: Input: Input is provided to mapper by user for processing of data set.
#Phase II: Splitting: In this phase splitting of input data is do on the basis of key-value.
Phase III: Mapping: All these data are then arrang in the particular format on the basis of their key and value. And then these keys and value is pass on to Reducer for further processing.
Reducer
Reducer reduces a set of intermediate values which share a key to a smaller set of values.
Phase I: Shuffling and Sorting: After data set process through mapper stage the process data set is pass on to shuffling phase. In this phase the data set is shuffle and sort according to the keys and values.
Phase II: Reducing: After the data sets are sort on the basic of their key-value, the values with same key are sort together and reduce into single form on the basis of similar key value.
Phase III: Final result: After reducing the data set the final output is been present to user according to their requirement.
Record reader: The basic function of Record Reader is to convert the input file into key and value pair (k,v).
k: offset value : Address : It is a unique value to call the content
v: content of record






