Hadoop HBase configuration
Hadoop HBase configuration, Welcome to the world of Hadoop Hbase Tutorials. In these Tutorials, one can explore how Hadoop Hbase Zookeeper configuration can be done. Learn More advanced Tutorials on HBase configuration in Hadoop from India’s Leading Big Data Training institute which Provides Advanced Hadoop Course for those tech Enthusiasts who wanted to explore the technology from scratch to advanced level like a Pro.
We the Prwatech The Pioneers of Big Data Training Offering Advanced Certification Course and Hadoop HBase configuration to those who are keen to explore the Technology under the World-class Training Environment.
Step by step process of HBase configuration in Hadoop

⇒Description: Below configuration changes are done in Table ’emp’ with columnar families as ‘Official detail’ and Personal Detail’.
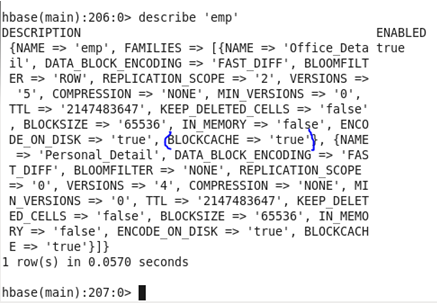
♦ Replication_Scope: Used to set the replication factor of data 0 to “disable” and 1 to “Enable”.
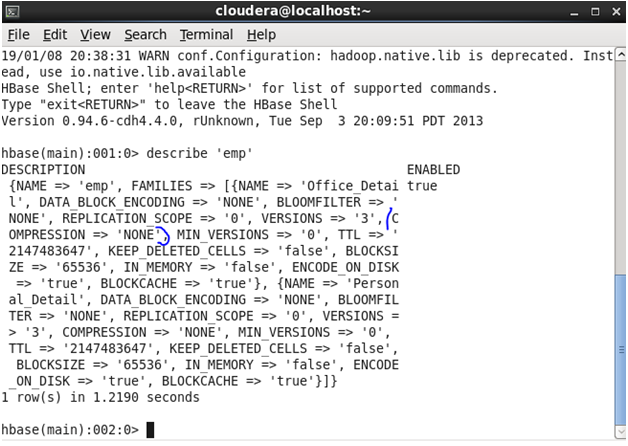
Before update: Initially, the Replication scope was set as ‘0’

Command: In HBase shell write following command.
<hbase> disable ‘emp’
<hbase> alter ‘emp’,{NAME=>’Official detail’,BLOCK_SCOPE=>1}
<hbase> enable ‘emp’
(Note: In my case, I have made changes in ‘Official_detail’ columnar family and instead of table name use your own table name which you have created )
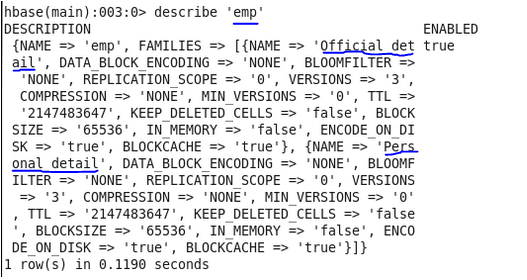
After Update
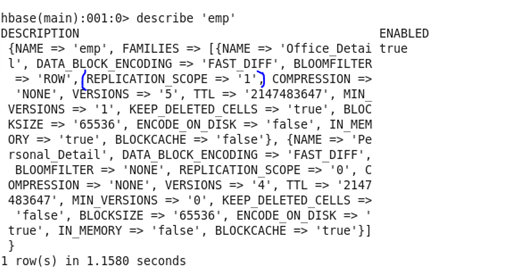
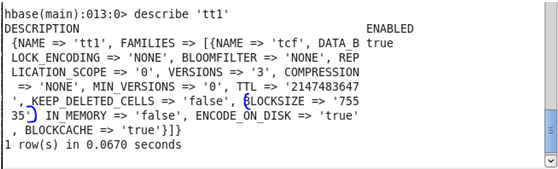
♦ BLOCKSIZE: It allows the user to describe there own block size according to requirement.
Before Update: Initially, the block size was set as 65536.
Command: In HBase shell write following command.
<hbase> disable ‘emp’
<hbase> alter ‘emp’,{NAME=>’cf’,BLOCKSIZE=>’75535’}
<hbase> enable ‘emp’
(Note: In my case, I have made changes in ‘Official_detail’ columnar family and instead of tablename use your own tablename which you have created )
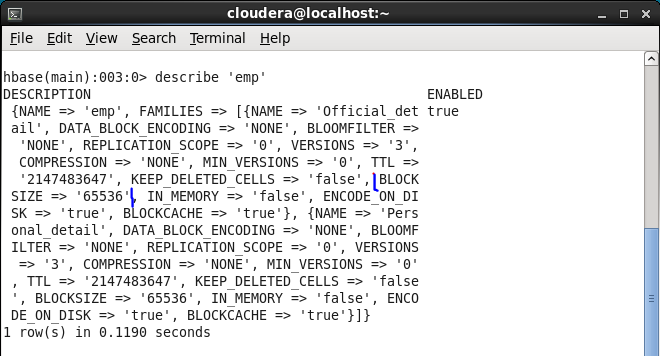
After Update
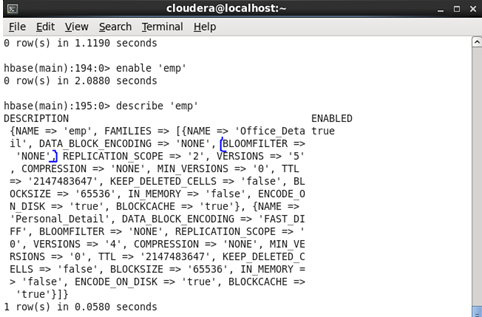
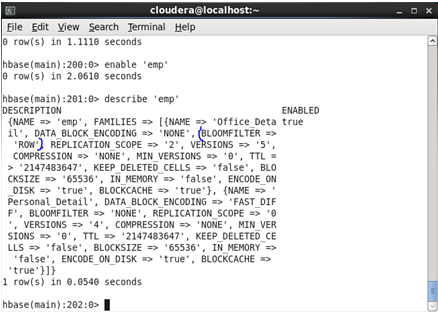
♦ BlOOMFILTER: It is an efficient way to test whether a StoreFile contains a specific row or row-col cell. Basically use to improve the performance of Hbase. It can be enabled or disabled according to the user. We can use three commands to set BLoomfilter —- NONE, ROW, ROWCOL.
Before Update: Initially, the Bloomfilter was set as ‘None’
Command: In HBase shell write following command.
<hbase> disable ‘emp’
<hbase> alter ‘emp’,{NAME=>’Official_Detail’,BLOOMFILTER=>’ROW’}
<hbase> enable ‘emp’
(Note: In my case, I have made changes in ‘Official_detail’ columnar family and instead of tablename use your own tablename which you have created )
After Update
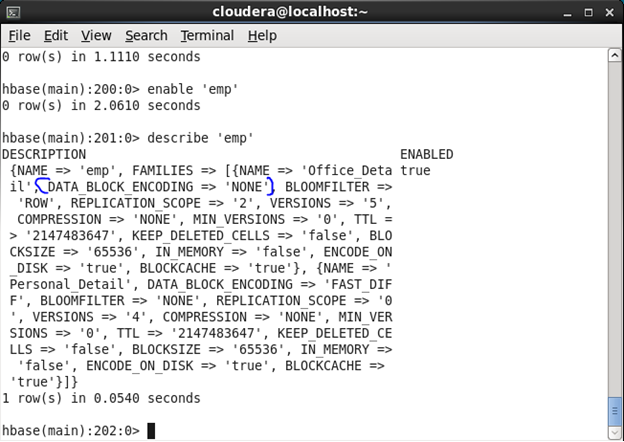
♦ DATA_BLOCK_ENCODING: HBase stores each cell individually, with its key and value. When a row has many cells, much space would be consumed by writing the same key many times, possibly. Therefore, encoding can save much space which has a great positive impact on large rows. There are two types of encoding – “FAST_DIFF” and “PREFIX”.
Before Update: Initially, the Data block encoding was set as ‘None’
Command: In HBase shell write following command.
<hbase> disable ‘emp’
<hbase> alter ‘emp’,{NAME=>’Official_Detail’,DATA_BLOCK_ENCODING =>’FAST DIFF’}
<hbase> enable ‘emp’
(Note: In my case, I have made changes in ‘Official_detail’ columnar family and instead of tablename use your own tablename which you have created )
After Update
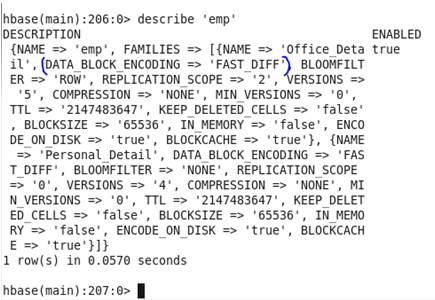
♦ VERSION: Cells in Hbase is a combination of the row, Column Family, and column qualifier, and contains a value and a timestamp, which represents the values’ versions. A timestamp is written alongside each value and the identifier for a given version of the value.
Before Update: Initially, the version was set as ‘3’
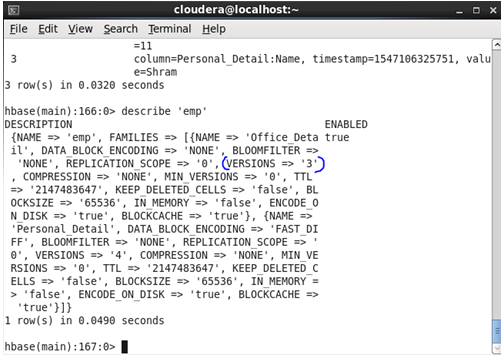
Command: In HBase shell write following command.
<hbase> disable ‘emp’
<hbase> alter ‘emp’,{NAME=>’Official_Detail’,VERSIONS=>5}
<hbase> enable ‘emp’
(Note: In my case, I have made changes in ‘Oficial_detail’ columnar family and instead of tablename use your own tablename which you have created )
After Update
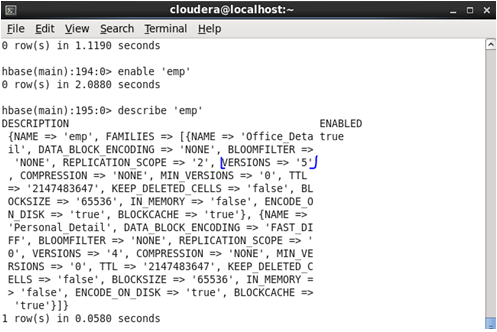
In the above case, HBase can store up to 3 versions only but after the update, it can store 5 versions now.
♦ Compression: Compression reduces the size of large, opaque byte arrays in cells, and can significantly reduce the storage space needed to store uncompressed data. By using Snappy Tool we can make changes in the compression setting.
♦ TTL(Time To Live) – It is a feature of Hbase that allows the user to delete the row in the table automatically. This feature reduces a lot of time required to maintain rows if you are handling sensitive data.
Before Update: Initially, the TTL was set as ‘2147483647’
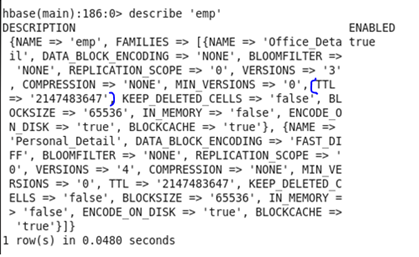
Command: In HBase shell write following command.
<hbase> disable ‘emp’
<hbase> alter ‘emp’,{NAME=>’Official_Detail’,TTL=>45567788}
<hbase> enable ‘emp’
(Note: In my case, I have made changes in ‘Oficial_detail’ columnar family and instead of tablename use your own tablename which you have created )
After Update
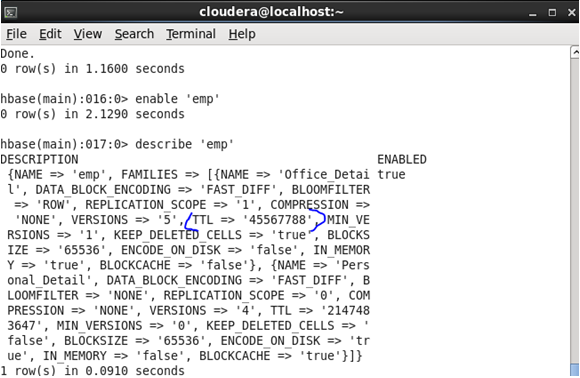
In the above case, TTL is mentioned in seconds.
♦ KEEP_DELETED_CELLS : ColumnFamilies can optionally keep deleted cells. That means deleted cells can still be retrieved with getting and Scan operations, as long these operations have a time range specified that ends before the timestamps of any deleted that would affect the cells. We can either enable it (‘true’) or disable it (‘false’).
Before Update: Initially, the Keep Deleted cells was set as ‘false’
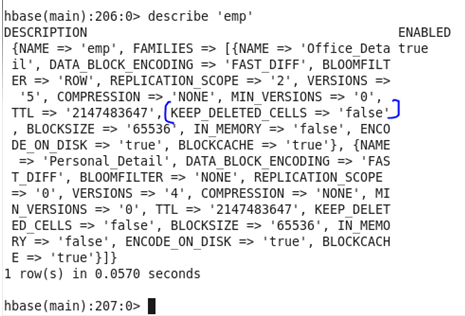
Command: In HBase shell write following command.
<hbase> disable ‘emp’
<hbase> alter ‘emp’,{NAME=>’Official_Detail’,KEEP_DELETED_CELLS =>’true’}
<hbase> enable ‘emp’
(Note: In my case, I have made changes in ‘Oficial_detail’ columnar family and instead of tablename use your own tablename which you have created )
After Update
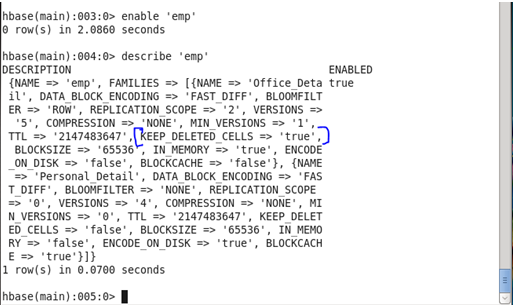
♦ IN-MEMORY: It is just a priority in the block cache.
Before Update: Initially, the In-memory was set as ‘false’
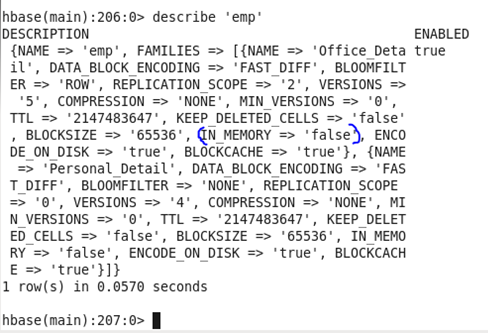
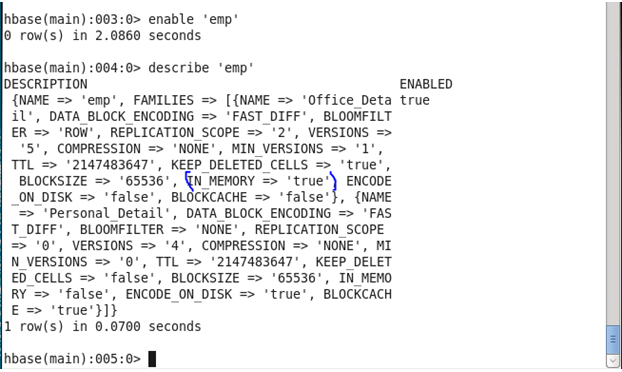
Command: In HBase shell write following command.
<hbase> disable ‘emp’
<hbase> alter ‘emp’,{NAME=>’Official_Detail’,IN_MEMORY =>’true’}
<hbase> enable ‘emp’
(Note: In my case, I have made changes in ‘Official_detail’ columnar family and instead of tablename use your own tablename which you have created )
After Update
♦ ENCODED_ON_DISK : It refers to the ability to encode KeyValues or Cells on-the-fly as blocks are written or read, exploiting duplicate information between consecutive Cells.
Before Update: Initially, the Encode on disk was set as ‘false’
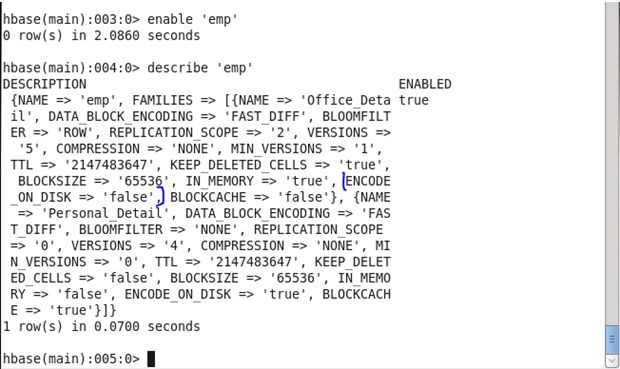
Command: In HBase shell write following command.
<hbase> disable ‘emp’
<hbase> alter ‘emp’,{NAME=>’Official_Detail’,ENCODED_ON_DISK =>’true’}
<hbase> enable ‘emp’
(Note: In my case, I have made changes in ‘Official_detail’ columnar family and instead of tablename use your own tablename which you have created )
After Update
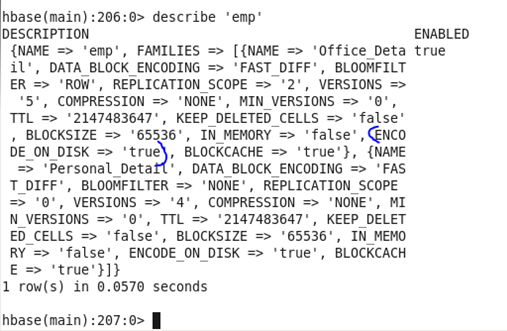
♦ BLOCKCACHE : HBase supports block cache improves read performance. When performing a scan, if block cache is enabled and there is room remaining, data blocks reads from storefiles on HDFS are cached in region servers’ Java Heap so that next time, accessing data in the same block can be served by the cached book. Block cache helps in reducing disk I/O for retrieving data.
Before Update: Initially, the Blockcache was set as ‘false’
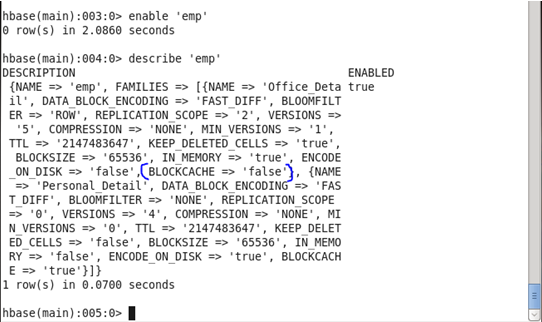
Command: In HBase shell write following command.
<hbase> disable ‘emp’
<hbase> alter ‘emp’,{NAME=>’Official_Detail’,BLOCKCACHE=>’true’}
<hbase> enable ‘emp’
(Note: In my case, I have made changes in ‘Official_detail’ columnar family and instead of tablename use your own tablename which you have created )
After Update