Hadoop HBase
Hadoop HBase Tutorial
Hadoop HBase Introduction
Welcome to the world of Advanced Hadoop Tutorials, in This Hadoop HBase Tutorial one can easily learn introduction to HBase schema design and apache Hadoop HBase examples
Hadoop HBase is an open-source distributed, column-based database used to store the data in tabular form. It is built on top of Hadoop. It is a distributed data store that can scale horizontally to 1,000s of commodity servers and petabytes of indexed storage.
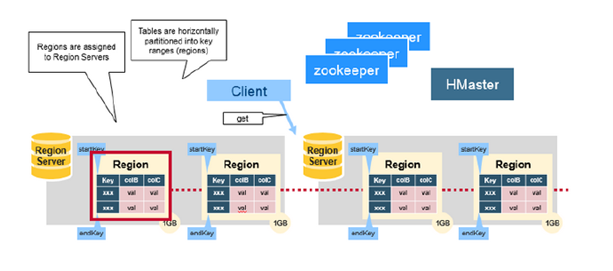
Tables are automatically partitioned horizontally by Hbase into regions. A region is denoted by the table it belongs to, its first row, inclusive and last row, exclusive.
Initially, a table comprises of a single region, but the size of the region grows after it crosses a configurable size threshold, it splits at a row boundary into new regions of approximately equal size. As the table grows the number of its regions grows, Regions are the units that get distributed over on the HBase cluster.
Region servers also manage the region splits informing the Hbase masters about the new daughter regions for it to manage the offlining of the parent region.
Hadoop HBase Tutorial
Implementation of Hadoop Hbase
HBase master node is orchestrating a cluster of one or more region server slaves. It is responsible for bootstrapping a virgin install, for assigning regions to registered region servers and for recovering region server failures. region server slave nodes are listed in the HBase conf/region servers file. Cluster site-specific configuration is made in the HBase conf/hbase-site.xml and conf/HBase-env.sh files.
Benefits of Hadoop HBase
1.HBase provides distributed storage to the user.
2.HBase provides high scalability
3. Hbase provides high availability
4.High performance
Drawbacks of Hadoop HBase
1. We can’t use join operators in HBase
2. Scans and queries can select a subset of available columns, perhaps by using a wildcard.
3.Limited atomicity and transaction support.
4. HBase supports multiple batched mutations of single rows only.
5. Data is unstructured and untyped.
6. Hbase can’t be access or manipulated via SQL
Why use Hbase
1. HBase is an open-source distribute database.
2. It has a good community and promise for the future.
3. It is develop on top of Hadoop and has good integration for the Hadoop platform if you are using Hadoop already.
4. It has a Cascading connector.
Why use HBase over RDBMS
1.No real index is requires in HBase
2. HBase supports automatic partitioning
3. HBase can scale linearly and automatically as new nodes are being added into it.
4. HBase supports commodity hardware. It means that we can add local hardware for increasing the memory for data storage.
5. HBase is highly fault tolerant.
6. HBase supports batch processing. It can run multiple processes at once.
Are you the one who is Hunger to become the certified Pro Hadoop Developer? Or the one who is keen to Take the advanced Certification Course from India’s Leading Big Data Training institute? then Ask your world-class Hadoop Trainer of the best Big Data Platform who can help you to learn the technology from Level 0 to Advanced like a Pro.
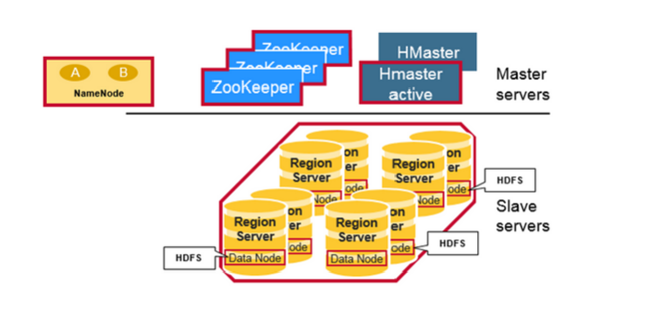
Basic components of Hadoop HBase
1.HMaster: This component of HBase is responsible for Region assignment, DDL (create, delete tables) operations.
2.Region servers: It serves data for reading and writes operation. To access data clients communicate with HBase Region Servers directly.
3.Zookeeper: It maintains the state of the cluster and provides server failure notification.
Hadoop Hbase Commands
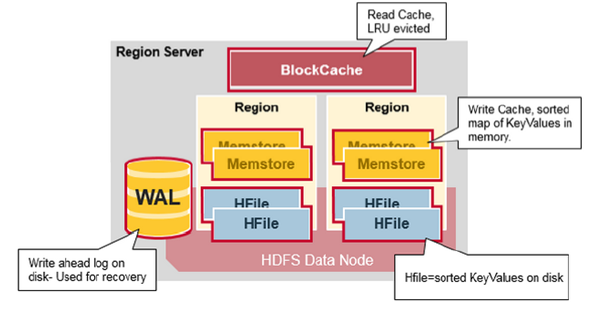
Region Server Components
1.WAL: It stands for Write Ahead Log which is a file on a distributed file system. The WAL is used to store new data that hasn’t yet been stored for permanent storage. It is used in case of failure as recovery.
2.BlockCache: It is the read cache that stores frequently read data in memory.
3.MemStore: It is the write cache. It stores new data that has not yet been write to disk.
4.H files: It stores the rows as sorted Key-values on disk
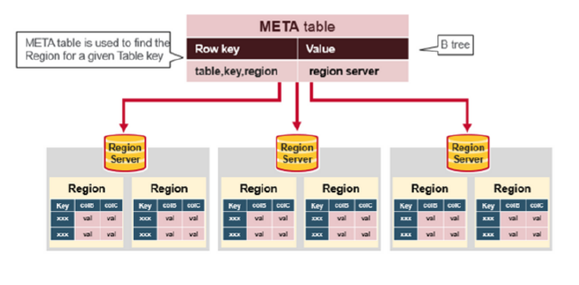
The .META Table
This META table is an HBase table that keeps a list of all regions in the system.
1.Key: table,region start key(stu001),region id
2. Values: RegionServer
prwatech, stu001,region_id
Hadoop HBase Read:
This is what happens the first time a client reads or writes to
HBase:
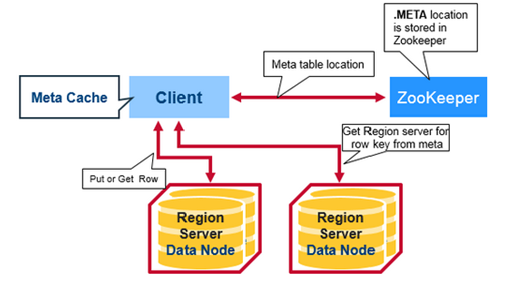
get ‘prwatech’, ‘stu001’ ==> Client interacts Region Server
- The client gets the Region server that hosts the META table from Zookeeper. The client will query the.META server to get the region server corresponding to the row key it wants to access. The client caches this information along with the.META table location.
- It will get the Row from the corresponding Region Server. For future reads, the client uses the cache to retrieve the.META location and previously read row keys. Over time, it does not need to query the.META table, unless there is a miss because a region has moved; then it will re-query and update the cache.
Hadoop HBase Write
When the client issues a Put request
- Write the data to the write-ahead log (WAL), Edits are to the end of the WAL file that is store on disk.
- Then it is place in the MemStore and the put request acknowledgment returns to the client.
Hadoop HBase Region Flush
When the MemStore accumulates enough data, the entire sort set is write to a new HFile in HDFS. This is a sequential write. It is very fast, as it avoids moving the disk drive head. There is one MemStore per CF per region; when one is full, they all flush. It also saves the last
written sequence number so the system knows what was persist so far.
Hadoop HBase Read Merge
HBase will automatically pick some smaller HFiles and rewrite them into fewer bigger H files. This process is call minor compaction. Minor compaction reduces the number of storage files by rewriting smaller files into fewer but larger ones, performing a merge sort.
Thanks for Reading us, Get the Advanced Hadoop Certification by Taking Course under the World-class Trainers of Top Rated Big Data Training institute.






