Hadoop Hbase Test Case

Hadoop HBase test case
Hadoop HBase test case, Welcome to the world of advanced Tutorials on Hadoop Hbase. Are you looking forward to the Hadoop HBase test case Platform? Or looking for some help on the HBase client test case? Then you’ve landed on the Right Path which providing advanced tutorial Based concepts on the Hadoop Hbase. In this tutorial, one can easily explore apache Hadoop Hbase test cases with step by step explanation.
If you are the one who wanted to become an expert in Hadoop technology? Or the one who wanted to explore the technology like a Pro under the certified experts with world-class classroom training environment, then asks your Hadoop Training institute experts who offer Advanced advanced Hadoop training. Follow the below-mentioned Hadoop HBase test case tutorial and enhance your skills to become a professional Hadoop Developer.
Description: Creating an HBase table using below mentioned columnar family to store student information and creating student database.Using the hue tool for more detailed and structured data manipulation.
For Student Record :

Creating Table
We create table ‘Prwatech’ with column_family as Weekend_Joining, Weekdays_Joining, Weekend_demo, Weekdays_demo, Weekend_new, Weekdays_new
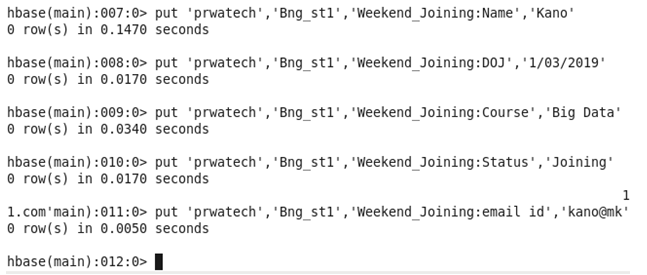
Inserting Values
In below-given case, we insert the value of two-row named as ‘Bng_st1’ and ‘Pune_st1’ in the column as Name, DOJ, Course, Status, and email id
Scan
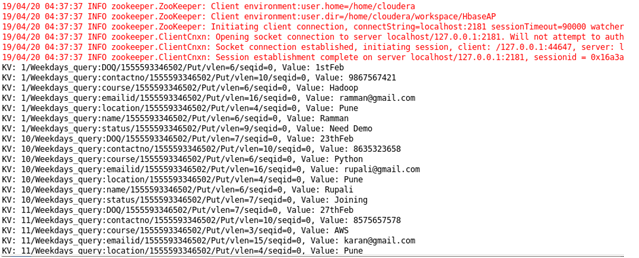
Case 1: To scan the record of a particular row
Case 2: To scan a particular record in the column of a row

Case 3: To scan the record of two or more than two records in a column of a row
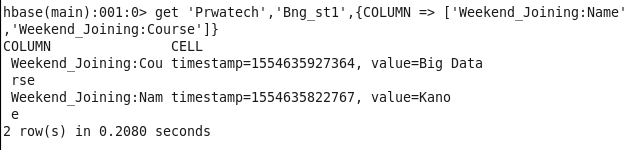
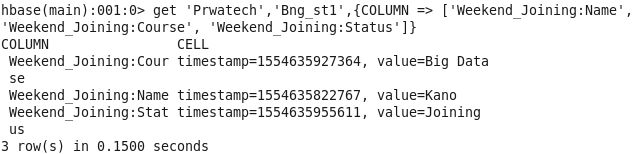
Case 4: Scanning the record or other rows with column

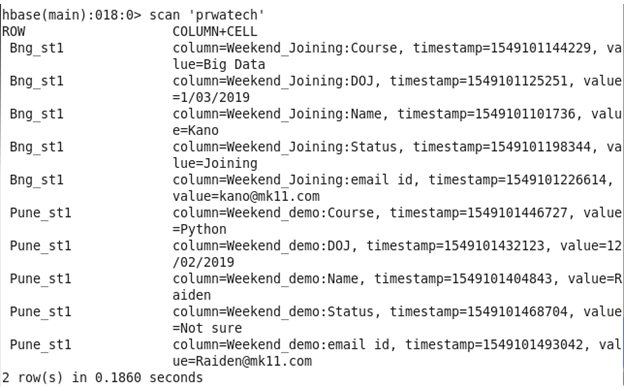
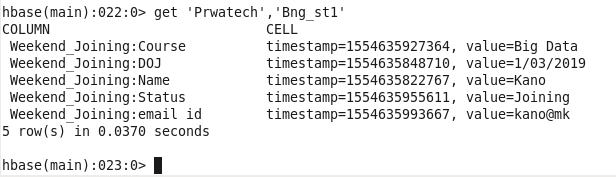
Display Table
All the data inserted are shown in tabular form in columnar form.
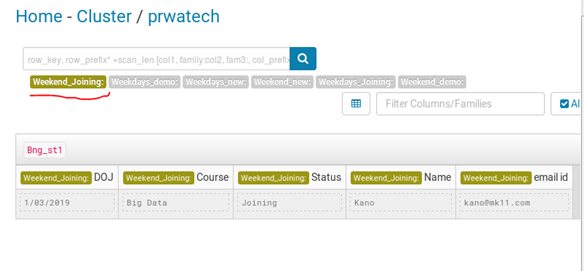
Data Manipulation
Using the hue tool we can represent our table in a more organized form.
Using the hue tool we can also update the values of the table.
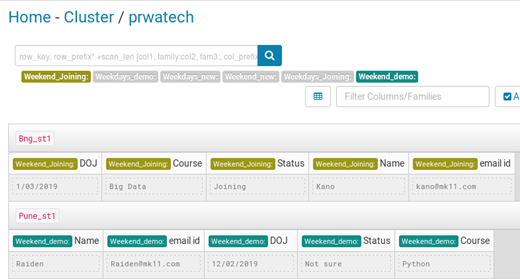
As shown below we have inserted the value for two columnar families:
Weekend_Joining and Weekend_demo.
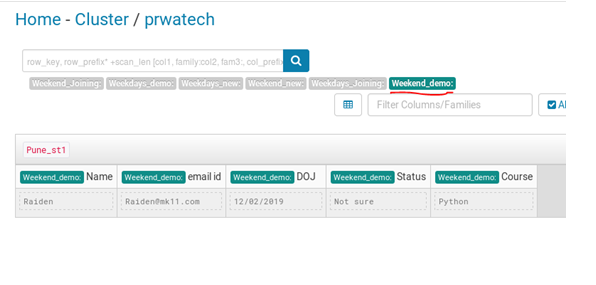
Finally, all data inserted into the table is displayed below :
For Query
Creating Table
Similar to the above case we create a table ‘Query’
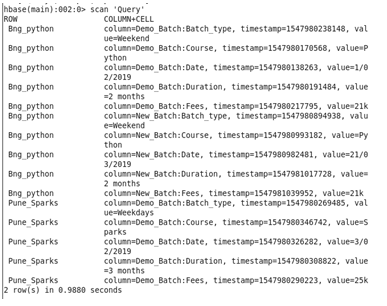
In hue it will look something like this
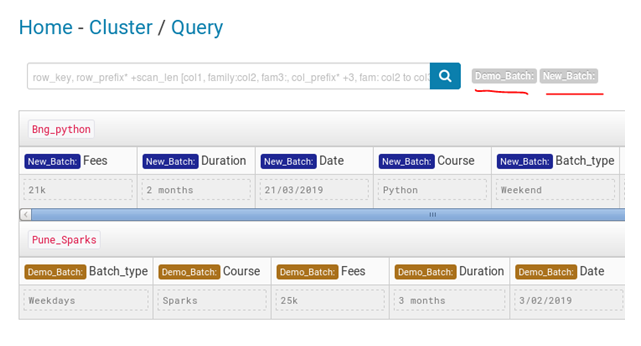
Hadoop Hbase test case 2
Description: The basic objective of this project is to create a database for IPL player and their stats using HBase in such a way that we can easily extract data for a particular player on the basis of the column in a particular columnar family. Using this technique we can easily sort and extract data from our database using a particular column as reference.
Prerequisites :
♦ Cloudera v5
♦ Eclipse on cloudera
♦ HBase daemons running
Create an HBase table for student query in such a way that it includes following columnar family
Batsman
Bowlers
All-rounders
And add the following column in each column family as per query
- Player id
- Jersey number
- Name
- DOB
- Handed
- Matches played
- Strike Rate
- Total Runs
- Country
Some of the use case to extract data are mentioned below:
- Players info from a particular country
- Players info with particular Jersey Number
- Run scored by a player between particular player id
- Players info which is left-handed
- Players from a particular country which are left-handed
- Players from a particular country with their strike rate
- Total match played for particular jersey number
- Info of player using DOB
- Total run of the player using Player ID
- Runs scored by Right-Handed players
Hadoop HBase Test case Solution
Create Ipl stats Database
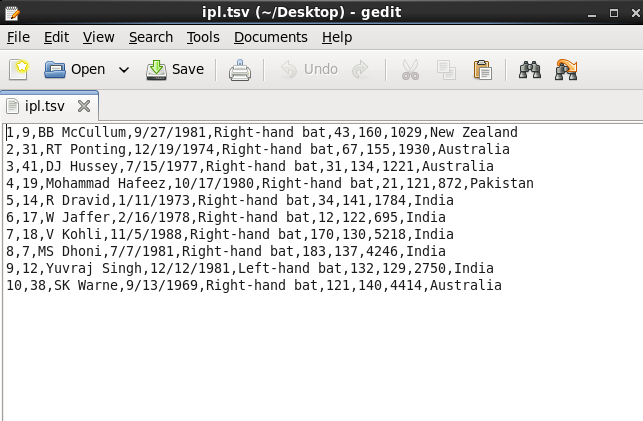
Data Source
https://drive.google.com/file/d/1rFQzqbS6CEqrM0TMrDMQBEP4sRm1yoCc/view?usp=sharing
Move the above database in HDFS

Create a table with following the columnar family in HBase

Move bulk data from HDFS into HBase

Data after loading into HBase
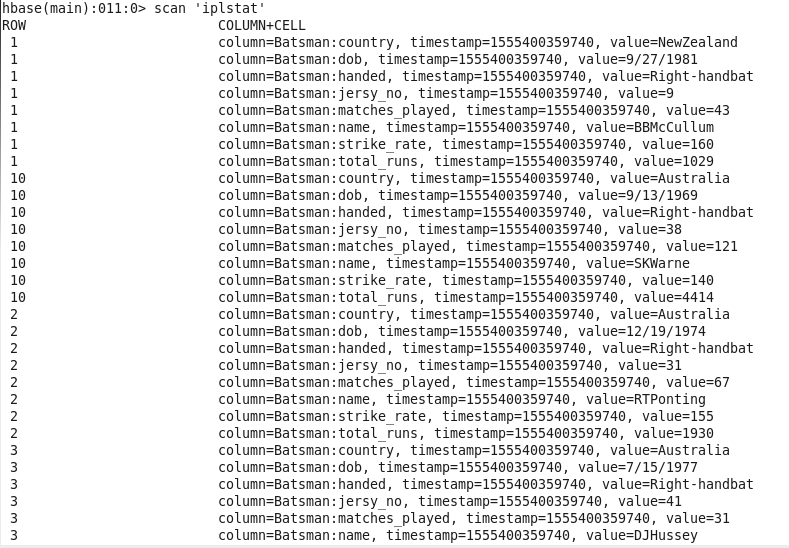
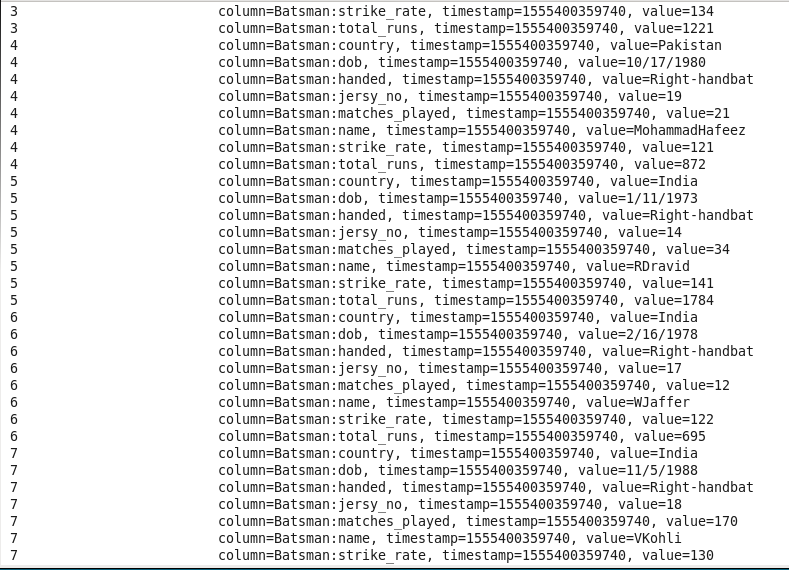
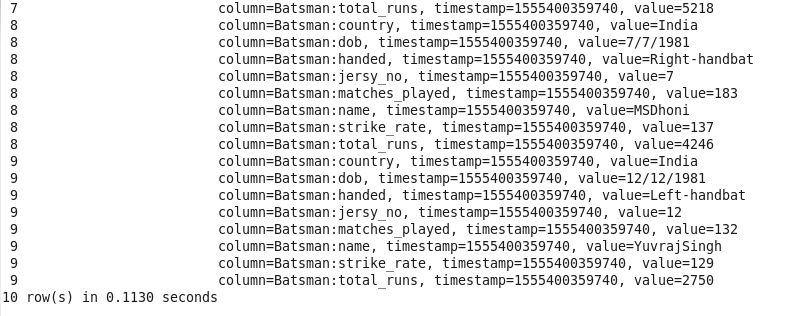
Hbase Test Case Examples
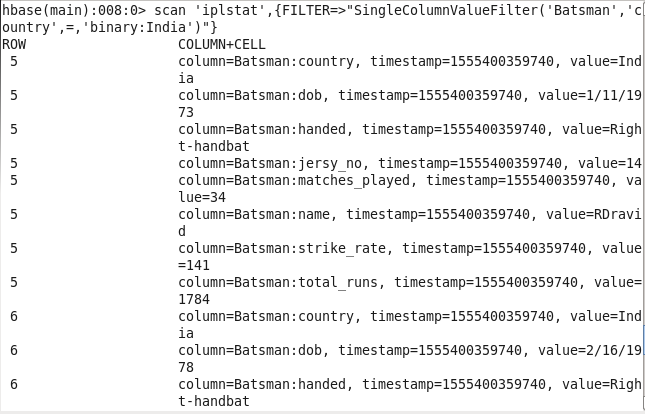
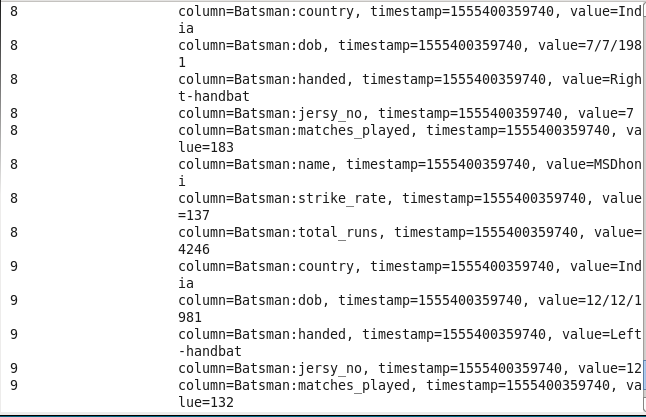
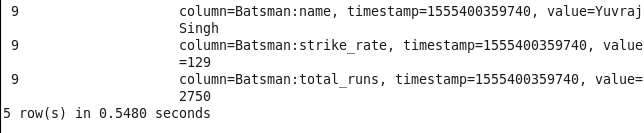
1: Player’s info from the particular country: Sorting players on the basis of their respective country.
Command : scan ‘iplstat’,{FILTER=>”SingleColumnValueFilter(‘Batsman’,’country’,=,’binary:India’)”}

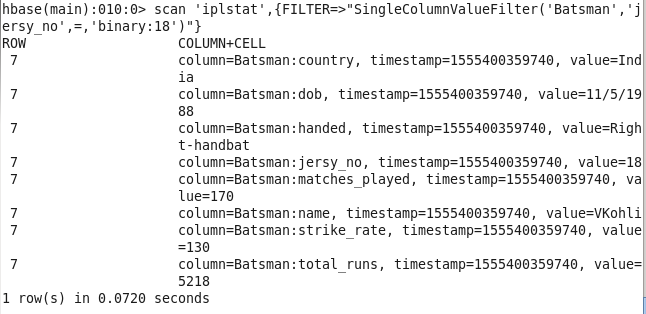
2: Players info with particular Jersey Number: Finding info about Players on the basis of their jersey Number
Command : scan ‘iplstat’,{FILTER=>”SingleColumnValueFilter(‘Batsman’,’jersy_no’,=,’binary:18′)”}
3: Run scored by a player between particular player id: Sorting players on the basis of run scored using player id
Command : scan ‘iplstat’,{COLUMN=>’Batsman:total_runs’,LIMIT=>9,STARTROW=>’7′}

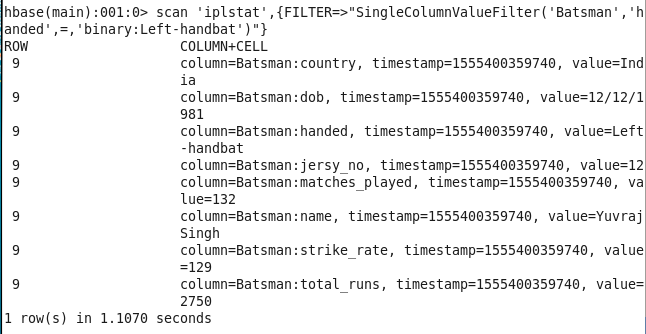
4: Players info which is left-handed: Finding player info on the basis of their batting hand
Command : scan ‘iplstat’,{FILTER=>”SingleColumnValueFilter(‘Batsman’,’handed’,=,’binary:Left-handbat’)”}
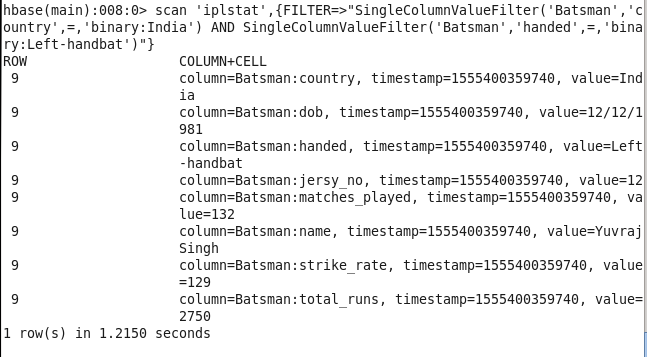
5: Players from a particular country which are left-handed: Finding info about a player on the basis of their country and Left-handed batting
Command : scan ‘iplstat’,{FILTER=>”SingleColumnValueFilter(‘Batsman’,’country’,=,’binary:India’) AND SingleColumnValueFilter(‘Batsman’,’handed’,=,’binary:Left-handbat’)”}
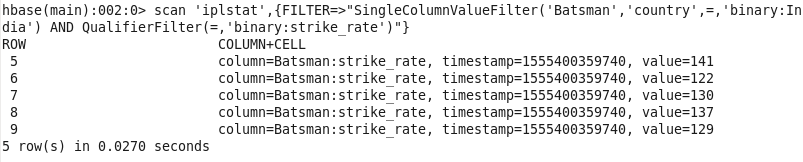
6: Players from a particular country with their strike rate: Finding the strike rate of players on the basis of their country.
Command : scan ‘iplstat’,{FILTER=>”SingleColumnValueFilter(‘Batsman’,’country’,=,’binary:India’) AND QualifierFilter(=,’binary:strike_rate’)”}
7: Total match played for particular jersey number: Finding total match played by the player on the basis of their jersey number
Command : scan ‘iplstat’,{FILTER=>”SingleColumnValueFilter(‘Batsman’,’jersy_no’,=,’binary:7′) AND QualifierFilter(=,’binary:matches_played’)”}

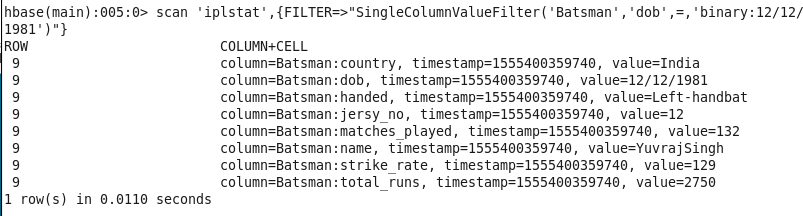
8: Info of player using DOB: Finding information about player on the basis of their DOB (Date of Birth)
Command : scan ‘iplstat’,{FILTER=>”SingleColumnValueFilter(‘Batsman’,’dob’,=,’binary:12/12/1981′)”}
9: Total run of the player using Player name: Using player name o find total run scored by him.
Command : scan ‘iplstat’,{FILTER=>”SingleColumnValueFilter(‘Batsman’,’name’,=,’binary:VKohli’) AND QualifierFilter(=,’binary:total_runs’)”}

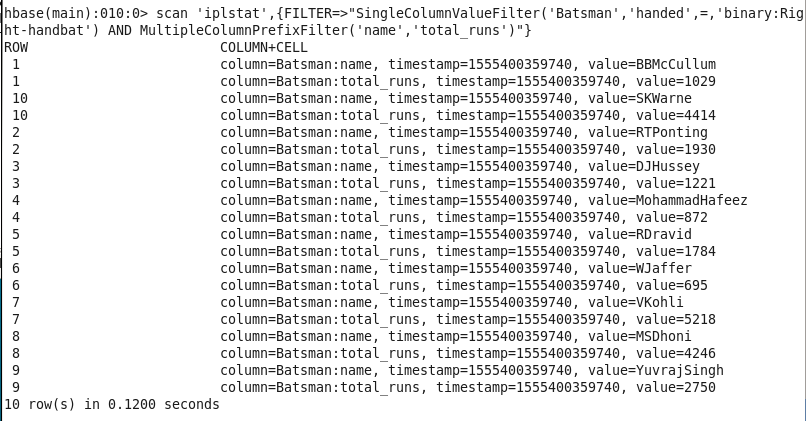
10: Runs scored and name of all Right Handed players: Finding the run scored and name for all right-handed players.
Command : scan ‘iplstat’,{FILTER=>”SingleColumnValueFilter(‘Batsman’,’handed’,=,’binary:Right-handbat’) AND MultipleColumnPrefixFilter(‘name’,’total_runs’)”}
Hadoop Hbase test case 3
Description: The basic objective of this project is to create a student database using HBase in such a way that we can easily extract data for a particular student on the basis of the column in particular columnar family. Using this technique we can easily sort and extract data from our database using a particular column as a reference.
Prerequisites :
♦ Cloudera v5
♦ Eclipse on Cloudera
♦ HBase daemons running
Create an HBase table for student query in such a way that it includes following columnar family :
- Weekdays_query
- Weekend_query
- Weekdays_demo
- Weekend_demo
- Weekdays_joining
- Weekend_joining
And add the following column in each column family as per query :
- Student id
- Date of Query (DOQ)
- Name
- Contact number
- Email id
- Course
- Location
- Status
Some of the use cases to extract data are mentioned below:
- Total number of Query for Particular date: Sorting student on the basis of the DOQ.
- Name of student between particular id: Sorting Student on the basis of id and course.
- Student details using particular student Id: Sorting Student on the basis of student Id.
- Student details for the particular course: Sorting Students on the basis of their choice of course.
- Student details using status: Sorting Students on the basis of their status.
- Name of student between particular id for a particular course: Sorting Student on the basis of id and course.
- A student enrolled for the demo: Sorting Student on the basis of the demo scheduled.
- A student not confirmed for the session: Sorting Student on the basis of the status of not joining or no response.
- Student query for Pune/Bangalore location: Sorting Student on the basis of location.
- Student name and email info using student ID: Sorting Student on the basis of missing email info.
Hadoop HBase Test case Solution
Create a student database
![]()
Data source: https://drive.google.com/open?id=1zVkg6_4matUGYfFA5Kkb9ao983lbrUyg
Move the above database in HDFS
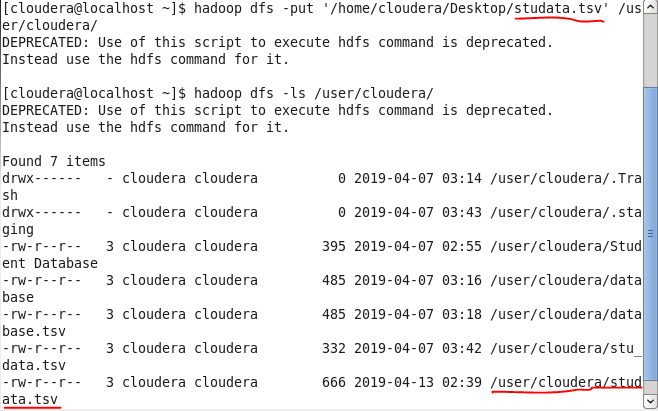
Create a table with following the columnar family in HBase
![]()
Move bulk data from HDFS into HBase

Data after loading into HBase
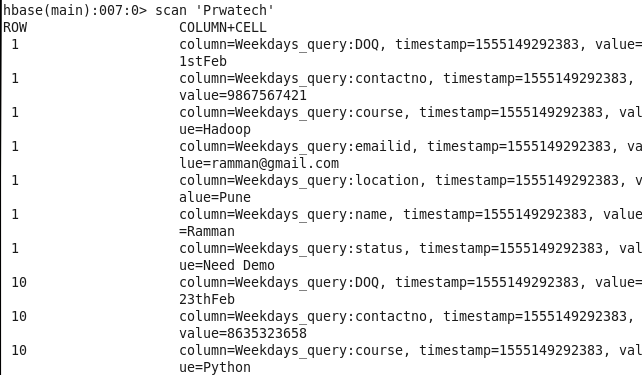
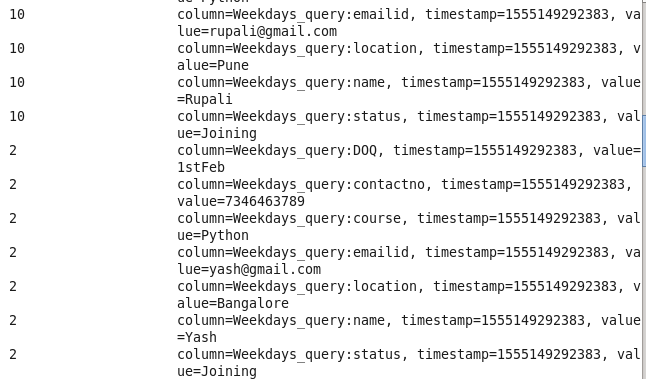
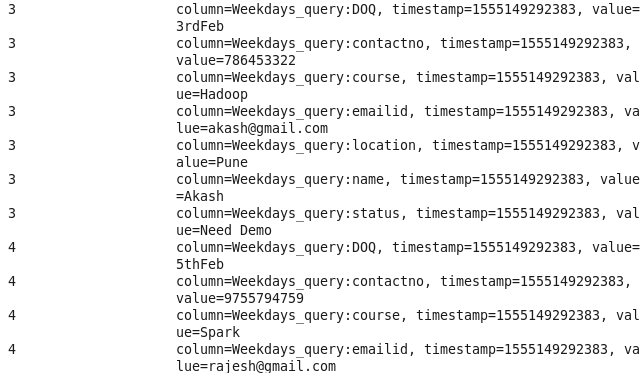
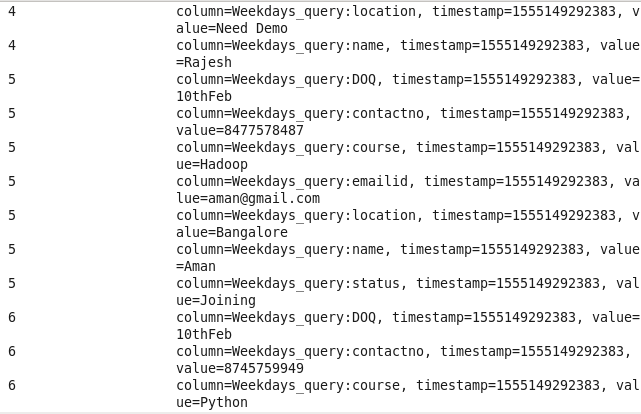
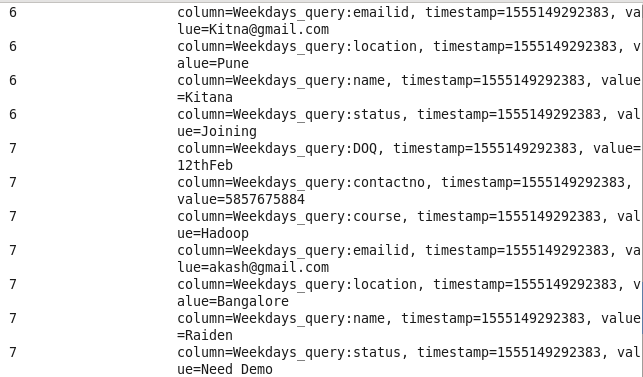
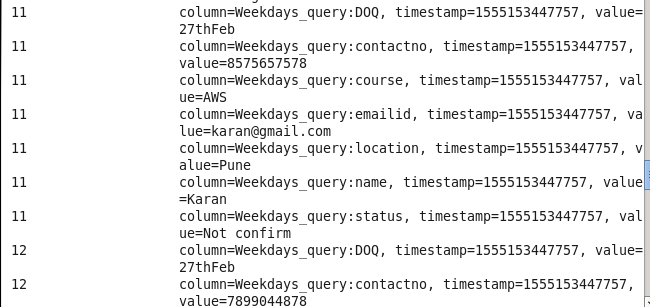
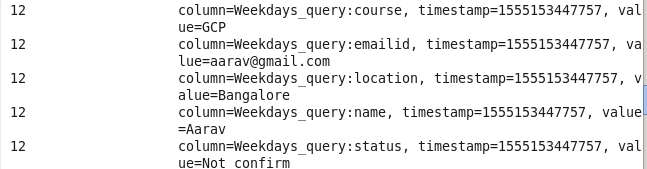
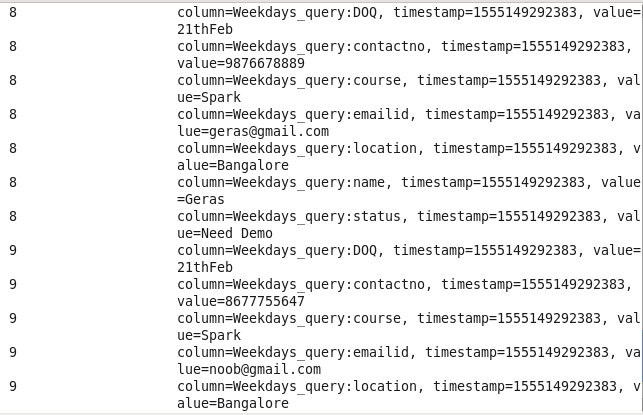

Using HBase Shell :
Hbase Test case Examples
1: Total number of Query for Particular date: Sorting student on the basis of the DOQ.
Command: scan ‘Prwatech’,{FILTER=>”SingleColumnValueFilter(‘Weekdays_query’,’DOQ’,=,’binary:1stFeb’)”}
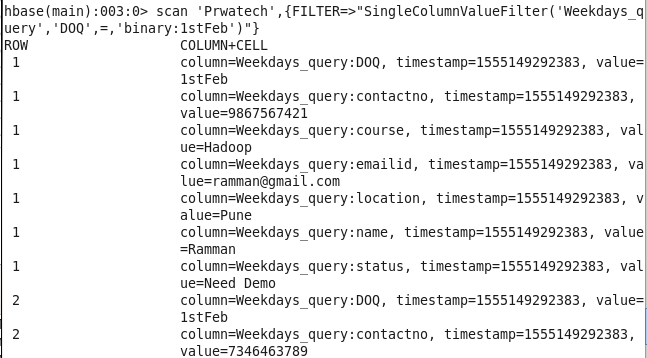
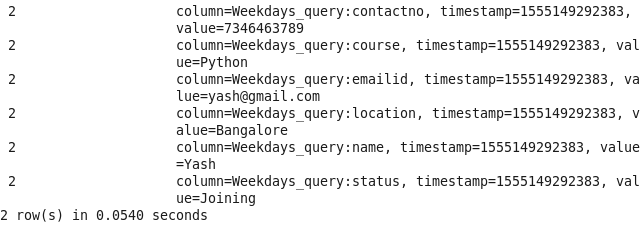
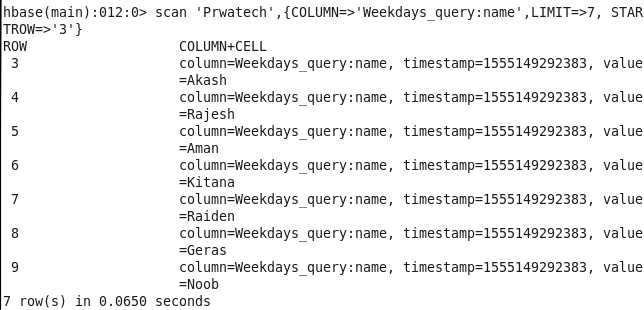
2: Name of student between particular id: Sorting Student on the basis of id and course
Command : scan ‘Prwatech’,{COLUMN=>’Weekdays_query:name’,LIMIT=>7, STARTROW=>’3′}
3: Student details using particular student Id: Sorting Student on the basis of student Id.
Command : scan ‘Prwatech’,{FILTER=>”(PrefixFilter(‘4’))”}
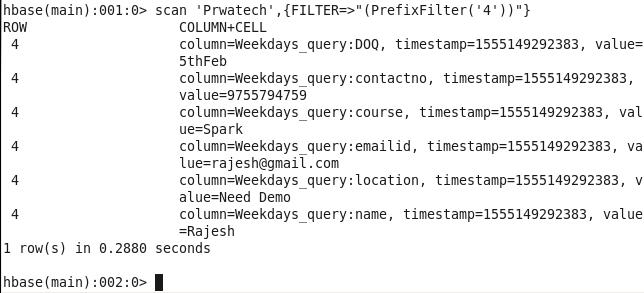
4: Student details for the particular course: Sorting Students on the basis of their choice of course.
Command : scan ‘Prwatech’,{FILTER=>”SingleColumnValueFilter(‘Weekdays_query’,’course’,=,’binary:Hadoop’)”}
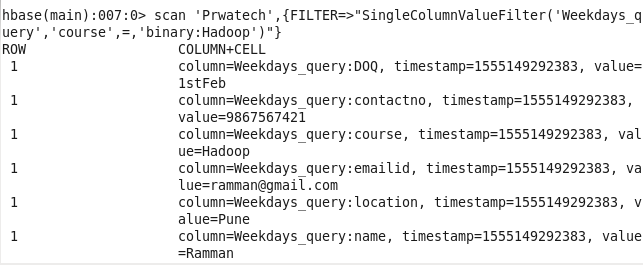
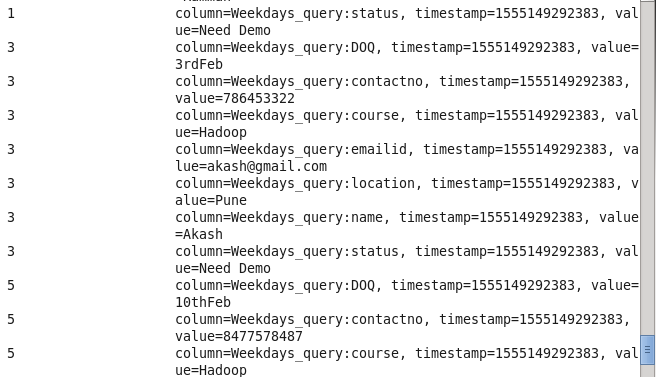
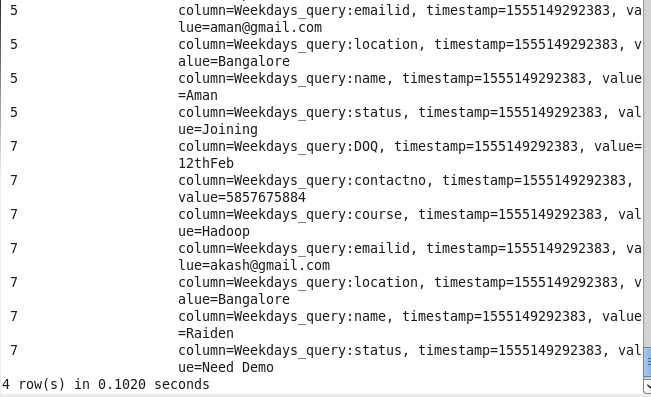
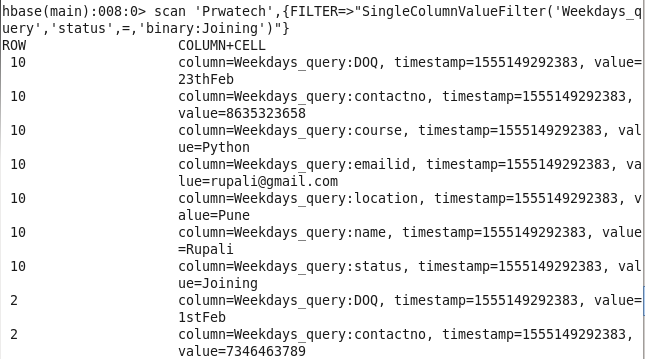
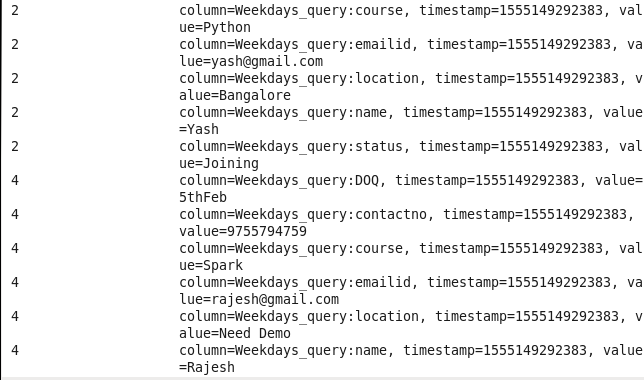
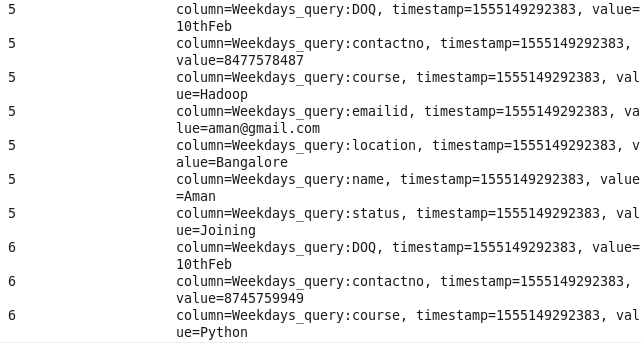
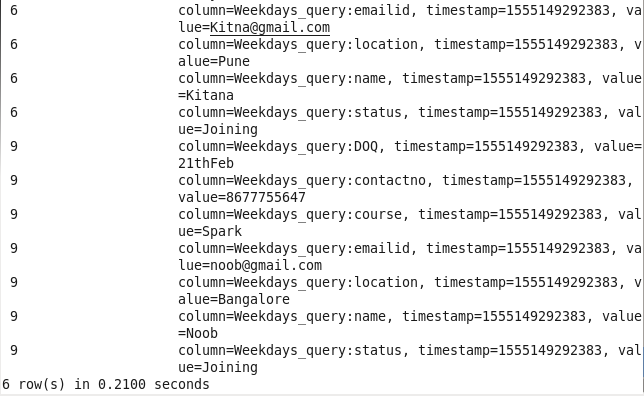
5: Student details using status: Sorting Students on the basis of their status.
Command : hbase(main):008:0> scan ‘Prwatech’,{FILTER=>”SingleColumnValueFilter(‘Weekdays_query’,’status’,=,’binary:Joining’)”}
6: Name of student between particular id for a particular course: Sorting Student on the basis of id and course.
Command: scan ‘Prwatech’,{COLUMN=>’Weekdays_query:course’,LIMIT=>7, STARTROW=>’3′,FILTER=>”ValueFilter(=,’binary:Hadoop’)”}

7: Student enrolled for the demo: Sorting Student on the basis of demo scheduled.
Command: scan ‘Prwatech’,{FILTER=>”SingleColumnValueFilter(‘Weekdays_query’,’status’,=,’binary:Need Demo’)”}
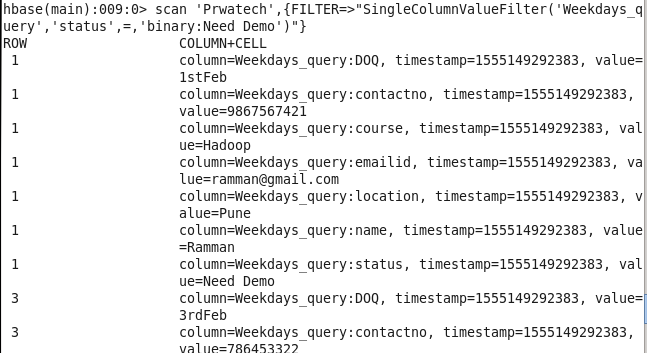

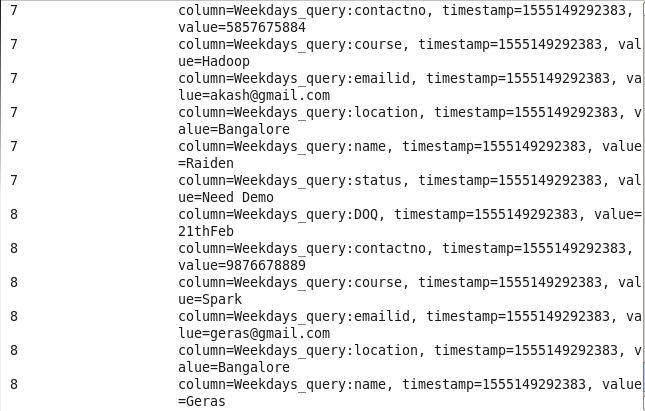

8: Student not confirmed for Session: Sorting Student on the basis of the status of not joining or no response.
Command: scan ‘Prwatech’,{FILTER=>”SingleColumnValueFilter(‘Weekdays_query’,’status’,=,’binary:Not confirm’)”}
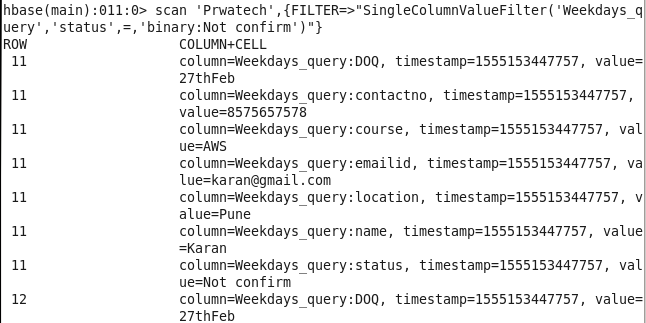
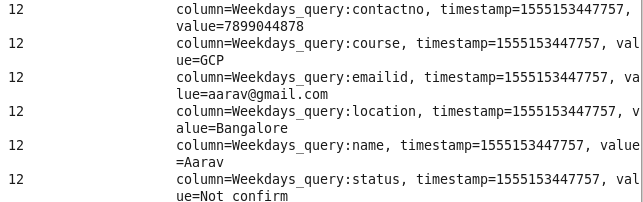
9: Student query for Pune/Bangalore location: Sorting Student on the basis of location.
Command: hbase(main):014:0> scan ‘Prwatech’,{FILTER=>”SingleColumnValueFilter(‘Weekdays_query’,’location’,=,’binary:Pune’)”}
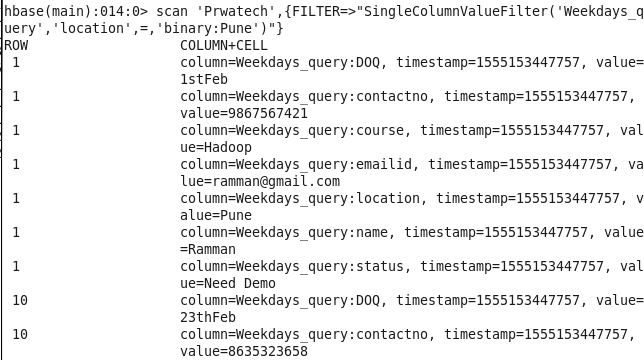
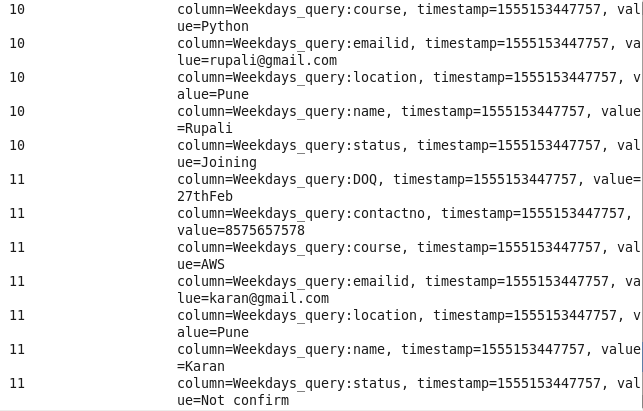
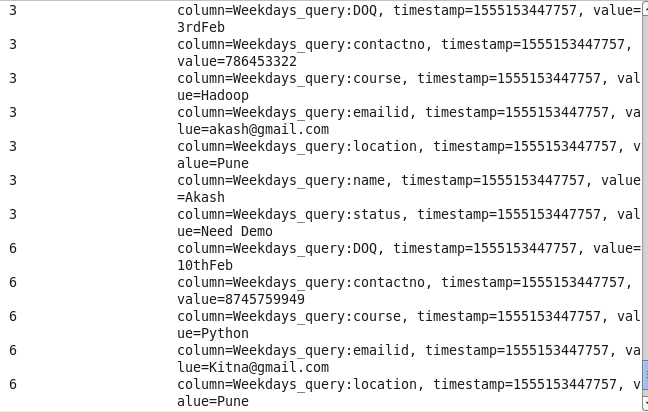

10: Student name and email info using student ID: Sorting Student on the basis of missing email info.
Command : scan ‘Prwatech’,{COLUMN=>’Weekdays_query’,STARTROW=>’3′,LIMIT=>5,FILTER=>”MultipleColumnPrefixFilter(‘name’,’emailid’)”}
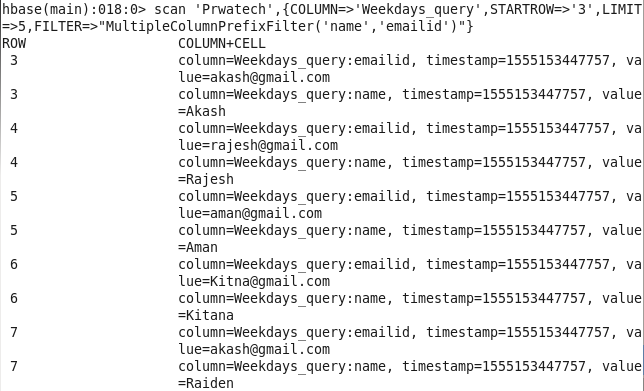
Using Eclipse :
Case 1: Total number of Query for Particular date: Sorting student on the basis of the DOQ.
package com.test.ap;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
import org.apache.hadoop.hbase.filter.CompareFilter;
import org.apache.hadoop.hbase.filter.BinaryComparator;
import com.amazonaws.services.applicationdiscovery.model.Filter;
import com.amazonaws.services.elasticmapreduce.model.KeyValue;
public class ScanTable{
public static void main(String args[]) throws IOException{
// Instantiating Configuration class
Configuration config = HBaseConfiguration.create();
// Instantiating HTable class
HTable table = new HTable(config, “Prwatech”);
// Instantiating the Scan class
Scan scan = new Scan();
SingleColumnValueFilter filter = new SingleColumnValueFilter(Bytes.toBytes(“Weekdays_query”), Bytes.toBytes(“DOQ”) , CompareFilter.CompareOp.EQUAL, new BinaryComparator(Bytes.toBytes(“1stFeb”)));
scan.setFilter(filter);
ResultScanner scanner = table.getScanner(scan);
// Reading values from the scan result
for (Result result = scanner.next(); result != null; result = scanner.next())
scan.setFilter(filter);
ResultScanner scanner1 = table.getScanner(scan);
for (Result result : scanner1) {
for (org.apache.hadoop.hbase.KeyValue kv : result.raw()) {
System.out.println(“KV: ” + kv + “, Value: ” +
Bytes.toString(kv.getValue()));
}
}
scanner1.close();
String result = null;
System.out.println(“Found row : ” + result);
//closing the scanner
scanner1.close();
}
}
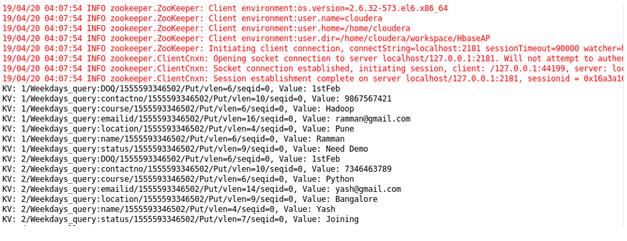
Case 2: Name of student between particular id: Sorting Student on the basis of id and course.
package com.test.ap;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.BinaryComparator;
import org.apache.hadoop.hbase.filter.InclusiveStopFilter;
import org.apache.hadoop.hbase.filter.PrefixFilter;
import org.apache.hadoop.hbase.filter.RegexStringComparator;
import org.apache.hadoop.hbase.filter.SubstringComparator;
import org.apache.hadoop.hbase.filter.CompareFilter;
import org.apache.hadoop.hbase.filter.Filter;
import org.apache.hadoop.hbase.filter.QualifierFilter;
import org.apache.hadoop.hbase.filter.FamilyFilter;
import org.apache.hadoop.hbase.filter.FilterList;
import org.apache.hadoop.hbase.filter.ValueFilter;
import org.apache.hadoop.hbase.util.Bytes;
import com.sun.imageio.plugins.png.RowFilter;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class Gaprow{
public static void main(String args[]) throws IOException{
// Instantiating Configuration class
Configuration config = HBaseConfiguration.create();
// Instantiating HTable class
HTable table = new HTable(config, “Prwatech”);
Scan scan = new Scan();
Filter filter1 = new InclusiveStopFilter(Bytes.toBytes(“7”));
Scan scan1 = new Scan();
scan1.setStartRow(Bytes.toBytes(“4”));
scan1.setFilter(filter1);
ResultScanner scanner = table.getScanner(scan1);
for (Result result : scanner) {
for (org.apache.hadoop.hbase.KeyValue kv : result.raw()) {
System.out.println(“KV: ” + kv + “, Value: ” +
Bytes.toString(kv.getValue()));
}
}
scanner.close();
ResultScanner scanner1 = table.getScanner(scan1);
// Reading values from the scan result
for (Result result = scanner1.next(); result != null; result = scanner1.next())
System.out.println(“Found row : ” + result);
//closing the scanner
scanner1.close();
}
}
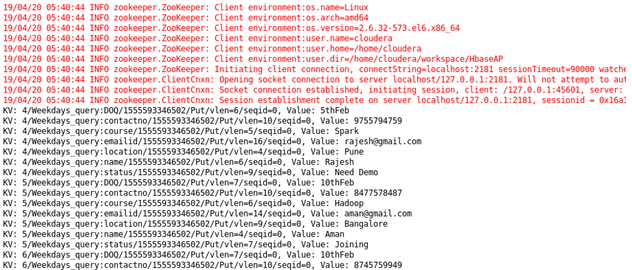
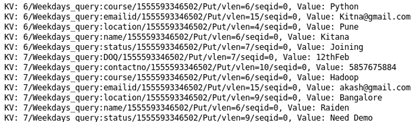
Case 3: Student details using particular student Id: Sorting Student on the basis of student Id.
package com.test.ap;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.BinaryComparator;
import org.apache.hadoop.hbase.filter.PrefixFilter;
import org.apache.hadoop.hbase.filter.RegexStringComparator;
import org.apache.hadoop.hbase.filter.SubstringComparator;
import org.apache.hadoop.hbase.filter.CompareFilter;
import org.apache.hadoop.hbase.filter.Filter;
import org.apache.hadoop.hbase.filter.QualifierFilter;
import org.apache.hadoop.hbase.filter.FamilyFilter;
import org.apache.hadoop.hbase.filter.FilterList;
import org.apache.hadoop.hbase.filter.ValueFilter;
import org.apache.hadoop.hbase.util.Bytes;
import com.sun.imageio.plugins.png.RowFilter;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class Rowfilter{
public static void main(String args[]) throws IOException{
// Instantiating Configuration class
Configuration config = HBaseConfiguration.create();
// Instantiating HTable class
HTable table = new HTable(config, “Prwatech”);
Scan scan = new Scan();
// Instantiating the Scan class
Filter filter = new PrefixFilter(Bytes.toBytes(“4”));
Scan scan1 = new Scan();
scan1.setFilter(filter);
ResultScanner scanner = table.getScanner(scan1);
for (Result result : scanner) {
for (KeyValue kv : result.raw()) {
System.out.println(“KV: ” + kv + “, Value: ” +
Bytes.toString(kv.getValue()));
}
}
scanner.close();
ResultScanner scanner1 = table.getScanner(scan1);
// Reading values from the scan result
for (Result result = scanner1.next(); result != null; result = scanner1.next())
System.out.println(“Found row : ” + result);
//closing the scanner
scanner1.close();
}
}
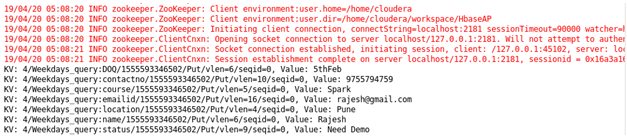
Case 4: Student details for the particular course: Sorting Students on the basis of their choice of course.
package com.test.ap;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
import org.apache.hadoop.hbase.filter.CompareFilter;
import org.apache.hadoop.hbase.filter.BinaryComparator;
import com.amazonaws.services.applicationdiscovery.model.Filter;
import com.amazonaws.services.elasticmapreduce.model.KeyValue;
public class ScanTable{
public static void main(String args[]) throws IOException{
// Instantiating Configuration class
Configuration config = HBaseConfiguration.create();
// Instantiating HTable class
HTable table = new HTable(config, “Prwatech”);
// Instantiating the Scan class
Scan scan = new Scan();
SingleColumnValueFilter filter = new SingleColumnValueFilter(Bytes.toBytes(“Weekdays_query”), Bytes.toBytes(“course”) , CompareFilter.CompareOp.EQUAL, new BinaryComparator(Bytes.toBytes(“Hadoop”)));
scan.setFilter(filter);
ResultScanner scanner = table.getScanner(scan);
// Reading values from the scan result
for (Result result = scanner.next(); result != null; result = scanner.next())
scan.setFilter(filter);
ResultScanner scanner1 = table.getScanner(scan);
for (Result result : scanner1) {
for (org.apache.hadoop.hbase.KeyValue kv : result.raw()) {
System.out.println(“KV: ” + kv + “, Value: ” +
Bytes.toString(kv.getValue()));
}
}
scanner1.close();
String result = null;
System.out.println(“Found row : ” + result);
//closing the scanner
scanner1.close();
}
}
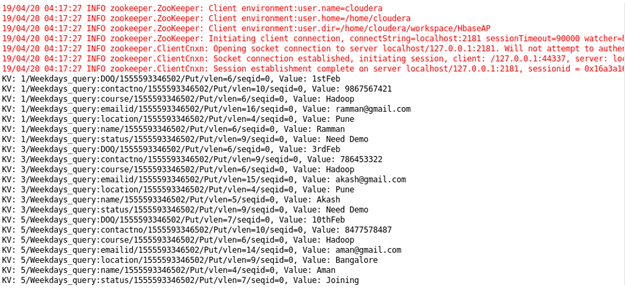

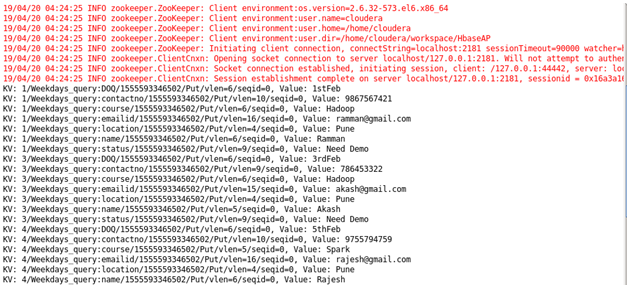
Case 5 : Student details using status: Sorting Student on the basis of their status.
package com.test.ap;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
import org.apache.hadoop.hbase.filter.CompareFilter;
import org.apache.hadoop.hbase.filter.BinaryComparator;
import com.amazonaws.services.applicationdiscovery.model.Filter;
import com.amazonaws.services.elasticmapreduce.model.KeyValue;
public class ScanTable{
public static void main(String args[]) throws IOException{
// Instantiating Configuration class
Configuration config = HBaseConfiguration.create();
// Instantiating HTable class
HTable table = new HTable(config, “Prwatech”);
// Instantiating the Scan class
Scan scan = new Scan();
SingleColumnValueFilter filter = new SingleColumnValueFilter(Bytes.toBytes(“Weekdays_query”), Bytes.toBytes(“status”) , CompareFilter.CompareOp.EQUAL, new BinaryComparator(Bytes.toBytes(“Joining”)));
scan.setFilter(filter);
ResultScanner scanner = table.getScanner(scan);
// Reading values from the scan result
for (Result result = scanner.next(); result != null; result = scanner.next())
scan.setFilter(filter);
ResultScanner scanner1 = table.getScanner(scan);
for (Result result : scanner1) {
for (org.apache.hadoop.hbase.KeyValue kv : result.raw()) {
System.out.println(“KV: ” + kv + “, Value: ” +
Bytes.toString(kv.getValue()));
}
}
scanner1.close();
String result = null;
System.out.println(“Found row : ” + result);
//closing the scanner
scanner1.close();
}
}
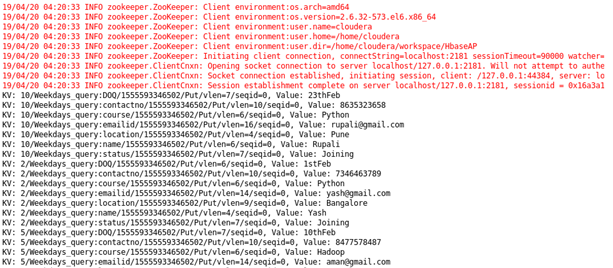

Case 6 : Name of student between particular id for a particular course: Sorting Student on the basis of id and course.
package com.test.ap;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.BinaryComparator;
import org.apache.hadoop.hbase.filter.InclusiveStopFilter;
import org.apache.hadoop.hbase.filter.PrefixFilter;
import org.apache.hadoop.hbase.filter.RegexStringComparator;
import org.apache.hadoop.hbase.filter.SubstringComparator;
import org.apache.hadoop.hbase.filter.CompareFilter;
import org.apache.hadoop.hbase.filter.Filter;
import org.apache.hadoop.hbase.filter.QualifierFilter;
import org.apache.hadoop.hbase.filter.FamilyFilter;
import org.apache.hadoop.hbase.filter.FilterList;
import org.apache.hadoop.hbase.filter.ValueFilter;
import org.apache.hadoop.hbase.util.Bytes;
import com.sun.imageio.plugins.png.RowFilter;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class Multifilter{
public static void main(String args[]) throws IOException{
// Instantiating Configuration class
Configuration config = HBaseConfiguration.create();
// Instantiating HTable class
HTable table = new HTable(config, “Prwatech”);
Scan scan = new Scan();
List<Filter> filters = new ArrayList<Filter>();
Filter filter1 = new ValueFilter(CompareFilter.CompareOp.EQUAL,
new SubstringComparator(“Hadoop”));
filters.add(filter1);
Filter filter2 = new InclusiveStopFilter(Bytes.toBytes(“7”));
Scan scan1 = new Scan();
scan1.setStartRow(Bytes.toBytes(“3”));
filters.add(filter2);
FilterList fl = new FilterList( FilterList.Operator.MUST_PASS_ALL,filters);
scan1.setFilter(fl);
ResultScanner scanner = table.getScanner(scan1);
for (Result result : scanner) {
for (org.apache.hadoop.hbase.KeyValue kv : result.raw()) {
System.out.println(“KV: ” + kv + “, Value: ” +
Bytes.toString(kv.getValue()));
}
}
scanner.close();
ResultScanner scanner1 = table.getScanner(scan1);
// Reading values from the scan result
for (Result result = scanner1.next(); result != null; result = scanner1.next())
System.out.println(“Found row : ” + result);
//closing the scanner
scanner1.close();
}
}
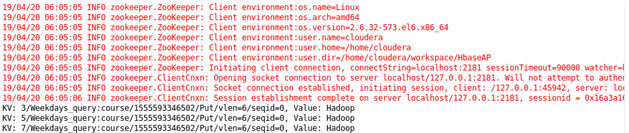
Case 7 : Student enrolled for the demo: Sorting Student on the basis of demo scheduled.
package com.test.ap;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
import org.apache.hadoop.hbase.filter.CompareFilter;
import org.apache.hadoop.hbase.filter.BinaryComparator;
import com.amazonaws.services.applicationdiscovery.model.Filter;
import com.amazonaws.services.elasticmapreduce.model.KeyValue;
public class ScanTable{
public static void main(String args[]) throws IOException{
// Instantiating Configuration class
Configuration config = HBaseConfiguration.create();
// Instantiating HTable class
HTable table = new HTable(config, “Prwatech”);
// Instantiating the Scan class
Scan scan = new Scan();
SingleColumnValueFilter filter = new SingleColumnValueFilter(Bytes.toBytes(“Weekdays_query”), Bytes.toBytes(“status”) , CompareFilter.CompareOp.EQUAL, new BinaryComparator(Bytes.toBytes(“Need Demo”)));
scan.setFilter(filter);
ResultScanner scanner = table.getScanner(scan);
// Reading values from the scan result
for (Result result = scanner.next(); result != null; result = scanner.next())
scan.setFilter(filter);
ResultScanner scanner1 = table.getScanner(scan);
for (Result result : scanner1) {
for (org.apache.hadoop.hbase.KeyValue kv : result.raw()) {
System.out.println(“KV: ” + kv + “, Value: ” +
Bytes.toString(kv.getValue()));
}
}
scanner1.close();
String result = null;
System.out.println(“Found row : ” + result);
//closing the scanner
scanner1.close();
}
}
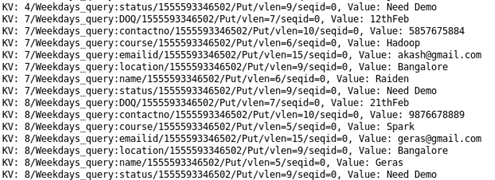
Case 8 : Student not confirmed for the session: Sorting Student on the basis of the status of not joining or no response.
package com.test.ap;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
import org.apache.hadoop.hbase.filter.CompareFilter;
import org.apache.hadoop.hbase.filter.BinaryComparator;
import com.amazonaws.services.applicationdiscovery.model.Filter;
import com.amazonaws.services.elasticmapreduce.model.KeyValue;
public class ScanTable{
public static void main(String args[]) throws IOException{
// Instantiating Configuration class
Configuration config = HBaseConfiguration.create();
// Instantiating HTable class
HTable table = new HTable(config, “Prwatech”);
// Instantiating the Scan class
Scan scan = new Scan();
SingleColumnValueFilter filter = new SingleColumnValueFilter(Bytes.toBytes(“Weekdays_query”), Bytes.toBytes(“status”) , CompareFilter.CompareOp.EQUAL, new BinaryComparator(Bytes.toBytes(“Not confirm”)));
scan.setFilter(filter);
ResultScanner scanner = table.getScanner(scan);
// Reading values from the scan result
for (Result result = scanner.next(); result != null; result = scanner.next())
scan.setFilter(filter);
ResultScanner scanner1 = table.getScanner(scan);
for (Result result : scanner1) {
for (org.apache.hadoop.hbase.KeyValue kv : result.raw()) {
System.out.println(“KV: ” + kv + “, Value: ” +
Bytes.toString(kv.getValue()));
}
}
scanner1.close();
String result = null;
System.out.println(“Found row : ” + result);
//closing the scanner
scanner1.close();
}
}
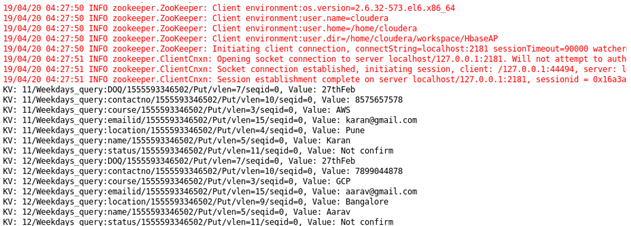
Case 9 : Student query for Pune/Bangalore location: Sorting Student on the basis of location.
package com.test.ap;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
import org.apache.hadoop.hbase.filter.CompareFilter;
import org.apache.hadoop.hbase.filter.BinaryComparator;
import com.amazonaws.services.applicationdiscovery.model.Filter;
import com.amazonaws.services.elasticmapreduce.model.KeyValue;
public class ScanTable{
public static void main(String args[]) throws IOException{
// Instantiating Configuration class
Configuration config = HBaseConfiguration.create();
// Instantiating HTable class
HTable table = new HTable(config, “Prwatech”);
// Instantiating the Scan class
Scan scan = new Scan();
SingleColumnValueFilter filter = new SingleColumnValueFilter(Bytes.toBytes(“Weekdays_query”), Bytes.toBytes(“location”) , CompareFilter.CompareOp.EQUAL, new BinaryComparator(Bytes.toBytes(“Pune”)));
scan.setFilter(filter);
ResultScanner scanner = table.getScanner(scan);
// Reading values from the scan result
for (Result result = scanner.next(); result != null; result = scanner.next())
scan.setFilter(filter);
ResultScanner scanner1 = table.getScanner(scan);
for (Result result : scanner1) {
for (org.apache.hadoop.hbase.KeyValue kv : result.raw()) {
System.out.println(“KV: ” + kv + “, Value: ” +
Bytes.toString(kv.getValue()));
}
}
scanner1.close();
String result = null;
System.out.println(“Found row : ” + result);
//closing the scanner
scanner1.close();
}
}