Hadoop-PIG with MapR

How to Configure Hadoop PIG with MapR
Configuring Hadoop Pig with MapR involves setting up Pig, a high-level data processing language for Hadoop, to run on a MapR cluster, a distribution of Hadoop that includes additional features and optimizations. MapR provides a comprehensive data platform with advanced capabilities for data storage, processing, and analytics.
To configure Hadoop Pig with MapR, users need to ensure that Pig is compatible with the MapR distribution and that the necessary configurations are in place to enable Pig to interact with the MapR file system (MapR-FS) and MapR ecosystem components.
Key steps in configuring Pig with MapR include:
- Installing Pig on each node of the MapR cluster and ensuring that Pig can access the MapR-FS.
- Configuring Pig properties such as
mapreduce.framework.nameto use MapReduce as the execution framework. - Setting up the MapR ecosystem components (e.g., MapR-DB, MapR Streams) for data ingestion and processing within Pig scripts.
- Testing Pig scripts on the MapR cluster to ensure compatibility and performance optimizations.
♦ Step 1. Go to pig console.
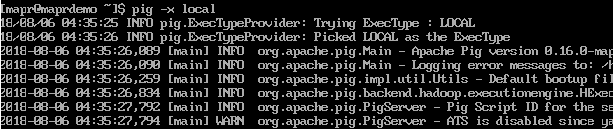
♦ Step 2. Load the data from your local machine.
![]()
♦ Step 3. check your dataset.
0
0
Popular Tags:
Difference between MapReduce and Pig
Getting started with Apache Pig!
How can I use the map datatype in Apache Pig?
Welcome to Apache Pig!






