Data Cleaning in Machine Learning, Are you the one who is looking forward to knowing data cleaning in machine learning? Or the one who is looking forward to knowing how to clean data for analysis in Machine Learning or Are you dreaming to become to certified Pro Machine Learning Engineer or Data Scientist then stops just dreaming, get your Data Science certification course from India’s Leading Data Science training institute.
Data Cleaning and its preparation is a very important step in Machine Learning and Data Science projects. As we know that more Data Scientists will spend their time on cleaning the data, Today in this blog Prwatech provides different data cleaning steps in machine learning. In this tutorial, we will learn how to clean data for analysis and will learn the Step by Step procedure of data cleaning in Machine Learning.
Do you want to know data cleaning steps in machine learning, So follow the below mentioned Python data cleaning guide from Prwatech and take advanced Data Science training like a pro from today itself under 10+ Years of hands-on experienced Professionals.
Data Cleaning Guide
The data set is an important asset in any data analysis and model building process. Generally, 80% of the time of data scientists are utilized in data cleaning and manipulation, whereas actually 20% time is utilized in analysis and modelling.
According to Wikipedia definition, ‘Data cleaning’ is the process of detecting and correcting (or removing) corrupt or inaccurate records from a recordset, table, or database and refers to identifying incomplete, incorrect, inaccurate or irrelevant parts of the data and then replacing, modifying, or deleting the dirty or coarse data. Data cleansing may be performed interactively with data wrangling tools, or as batch processing through scripting.
To perform the data analytics properly we need a variety of data cleaning methods. Data cleaning depends on the type of data set. We have to deal with missing or different types of improper entries. So let’s see the overall strategy.
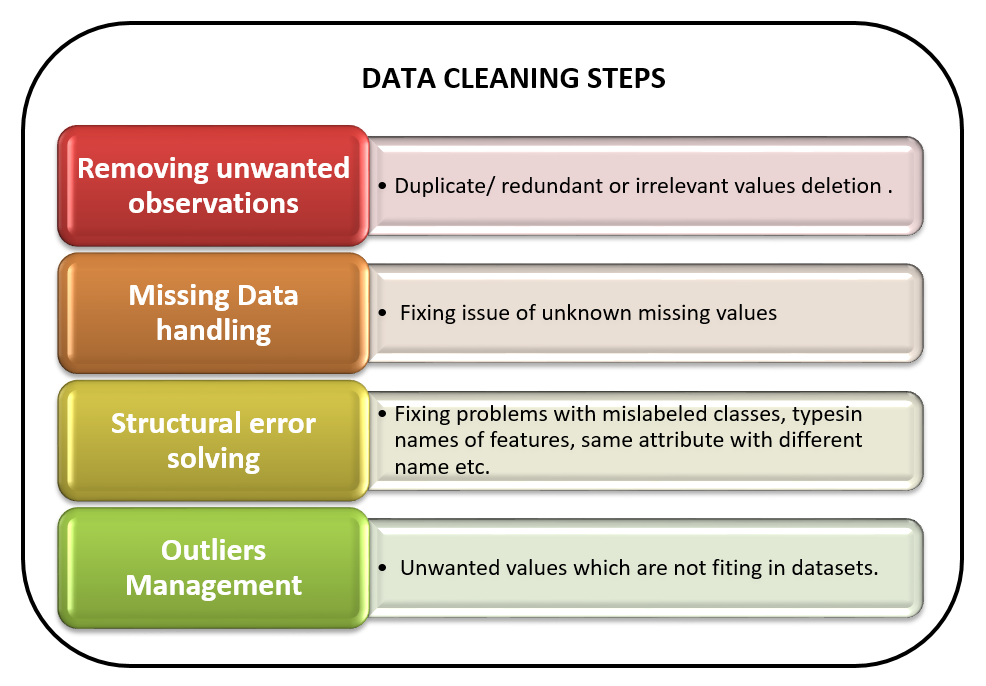
Data Cleaning Steps in Machine Learning
Removing Unwanted Observations
The important step is to observe the dataset and try to identify independent and dependant variables according to the problem statement or business domain. It will be easy for us to delete the unwanted columns from the tabular data set. Also, we have to check whether the dataset contains any null value. For that, a function from the panda's library ‘isnull ()’ is used.
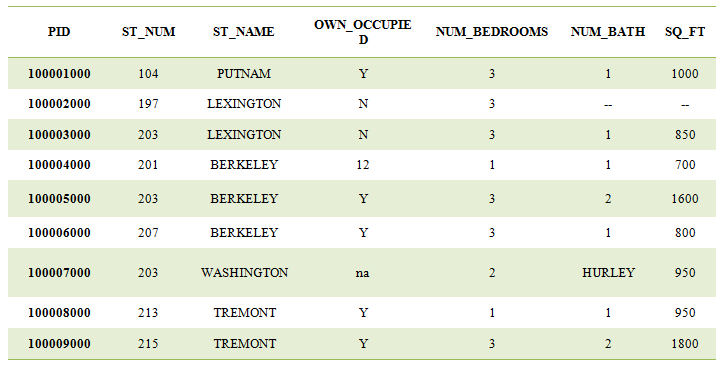
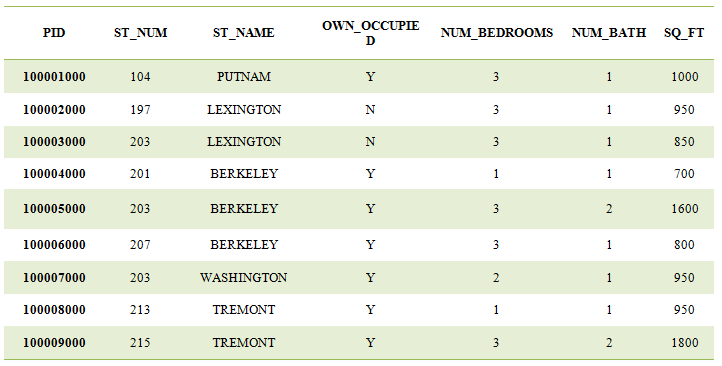
Example: Let’s consider the following dataset
Let’s assign the variable to this table as df:
df= pd_csv (“Give path of dataset”);
then find null values from each column.
df.isnull().any()
It will give output in True or False, where True value represents the Null value is present and false means there is no null value in the column. Where we get column-wise maximum null values, it is better to drop that column from the table. Now here BUI_NAME has maximum null values so we can drop this column as:
df=df.drop([‘BUI_NAME’],axis=1)
To Remove unwanted rows having maximum NaN values:
In a similar manner is we have rows with maximum null or NaN values we can remove those using dropna(). It can be used as:
df= df.dropna()
Note: This will remove all rows having at least one NaN value.
Missing Data Handling:
In some cases, missing values must be treated as unknown values rather than NULL or NaN values. Since columns can be important in the analysis process, in this scenario we must replace the values with proper values or formats. In the case of columns containing numerical values, we can fill that missing field with mean or mode value according to column requirement.
There may be different formats to manipulate missing values with different data types.
Example:
Here columns PID, ST_NUM, OWN_OCCUPIED, NUM_BEDROOMS, and NUM_BATH are having missing values. So in this scenario, it is easy to first replace it with NaN and then replace it with median or mode value. Also, we can add the method ‘interpolate’ where it will take an average of two values following NaN entry.
df['PID']=df['PID'].interpolate()
df['ST_NUM']=df['ST_NUM'].fillna(df.ST_NUM.median())
df['NUM_BEDROOMS']=df['NUM_BEDROOMS'].fillna(df. NUM_BEDROOMS.median())
df['SQ_FT']=df['SQ_FT '].fillna(df. SQ_FT.median())
Result:
Structural Error Solving
The errors arise while dimension transfer of data or other similar situations is called structural errors. Structural errors contain types in the name of features, or mislabelled classes, classes with the same category but inconsistent capitalization or difference.
Example: The model will treat TREMONT and Tremont in the following table as different classes or values, though they represent the same value, these are some structural errors that make our model inefficient and affect the further results.
In some unstructured data, NaN values can be written as na, -- or N/A, and these are also examples of mislabelled data. So we have to find those values in the table and we have to assign it as NaN as follows:
Mislabel_values = [“na”,”--“,”N/A”]df=pd.read_csv("Give file path",na_values=missing_values)df['SQ_FT']=df['SQ_FT'].fillna(df.SQ_FT.median())df['NUM_BATH']=df['NUM_BATH'].fillna(df. NUM_BATH.mode())
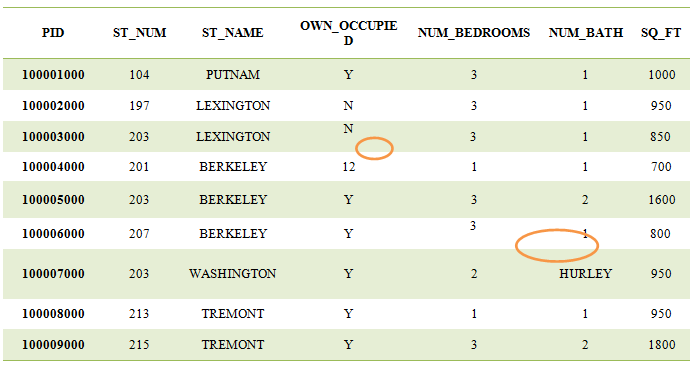
In the column named 'OWN_OCCUPIED', Most values are ‘Y’ so, it is better to replace the NA value with the most occurring value ‘Y’
df[‘QWN_OCCUPIED’]=df['QWN_OCCUPIED '].fillna(‘Y’)
Result:
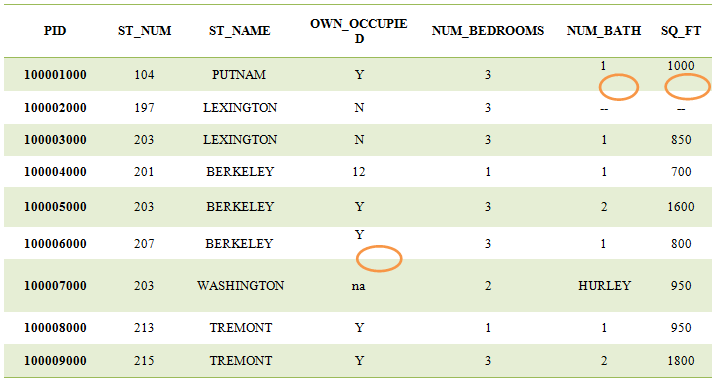
Now there is a number in column OWN_OCCUPIED, where one of the characters ‘Y’ or ‘N’ should be there. Similarly, there is word HURLEY present in column NUM_BATH, where a number is expected. These can be removed as follows:
First, we will see about removing the HURLEY word from the column and we will replace it with NaN. (A loop can be generated to replace all such values with NaN, which does not float)
count=0
for row in df['NUM_BATH']:
try:
float(row)
pass
except ValueError:
df.loc[count,'NUM_BATH']=np.nan
count+=1
And then we can replace these NaN values with Mode as mentioned below
df[‘NUM_BATH]=df['NUM_BATH'].fillna(df.NUM_BATH.median())
Result:
It is very important to check the data types of all columns in the data frame before and after the conversion process. To check the data type of columns we can write
df.dtypes
we get the result as
Now it is showing that the data type of column ‘NUM_BATH’ as afloat. Basically, a number of bathrooms must be in integer format as it will not be a float value. So we have to convert the column in integer form as follows:
df['NUM_BATH'] = df['NUM_BATH'].astype(int)
df
Which will give results with converted ‘NUM_BATH’ column into integer form.
Similarly, as you can see in the same table in the column of ‘OWN_OCCUPIED’ instead of string value a numerical value b12 is present. In this scenario first, we have to check the data type of the column and if it does not match with other values in the column. In the above case replace that number by Y or N which appears most.
count=0
for row in df['OWN_OCCUPIED']:
try:
int(row)
df.loc[count,'OWN_OCCUPIED']=np.nan
except ValueError:
pass
count+=1
Now we can replace this NaN value with Y as follows:
df[‘QWN_OCCUPIED’]=df['QWN_OCCUPIED '].fillna(‘Y’)
Outliers Management:
When almost all data gets cleared in the above scenarios, still there is the possibility that the model cannot give the expected results. It’s due to values that are significantly different from all other observations. Those are nothing but outliers. Generally, we do not remove outliers until we have a genuine reason to remove them. Sometimes, removing them improves performance, sometimes not. But in some cases suspicious values, those are unlikely to happen, should be found out and must be removed from the table.
We hope you understand Data Cleaning in Machine Learning concepts and how to clean data for analysis. Get success in your career as a Data Scientist by being a part of the Prwatech, India's leading Data Science training institute in Bangalore.
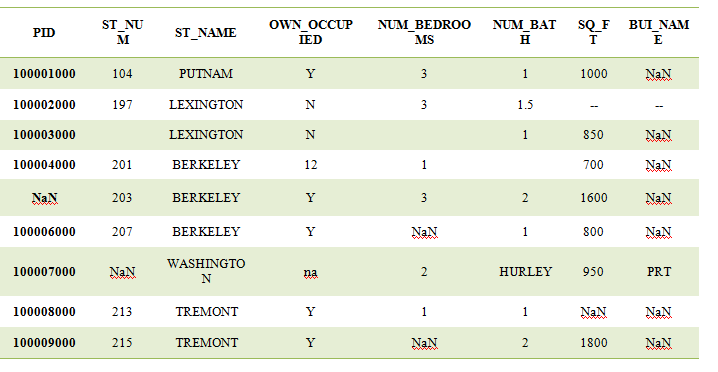 Let’s assign the variable to this table as df:
df= pd_csv (“Give path of dataset”);
then find null values from each column.
df.isnull().any()
It will give output in True or False, where True value represents the Null value is present and false means there is no null value in the column. Where we get column-wise maximum null values, it is better to drop that column from the table. Now here BUI_NAME has maximum null values so we can drop this column as:
df=df.drop([‘BUI_NAME’],axis=1)
Let’s assign the variable to this table as df:
df= pd_csv (“Give path of dataset”);
then find null values from each column.
df.isnull().any()
It will give output in True or False, where True value represents the Null value is present and false means there is no null value in the column. Where we get column-wise maximum null values, it is better to drop that column from the table. Now here BUI_NAME has maximum null values so we can drop this column as:
df=df.drop([‘BUI_NAME’],axis=1)
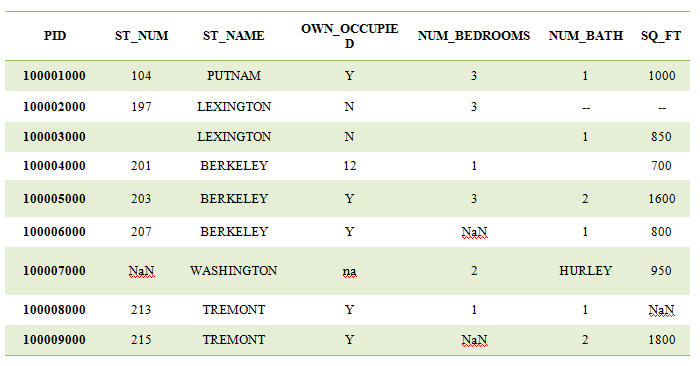 There may be different formats to manipulate missing values with different data types.
There may be different formats to manipulate missing values with different data types.
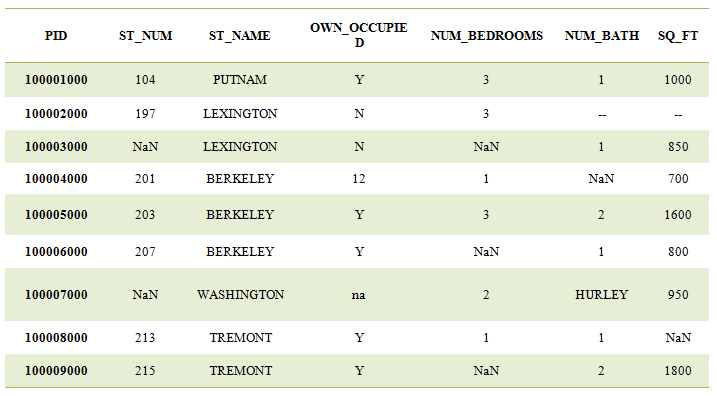 df['PID']=df['PID'].interpolate()
df['ST_NUM']=df['ST_NUM'].fillna(df.ST_NUM.median())
df['NUM_BEDROOMS']=df['NUM_BEDROOMS'].fillna(df. NUM_BEDROOMS.median())
df['SQ_FT']=df['SQ_FT '].fillna(df. SQ_FT.median())
df['PID']=df['PID'].interpolate()
df['ST_NUM']=df['ST_NUM'].fillna(df.ST_NUM.median())
df['NUM_BEDROOMS']=df['NUM_BEDROOMS'].fillna(df. NUM_BEDROOMS.median())
df['SQ_FT']=df['SQ_FT '].fillna(df. SQ_FT.median())
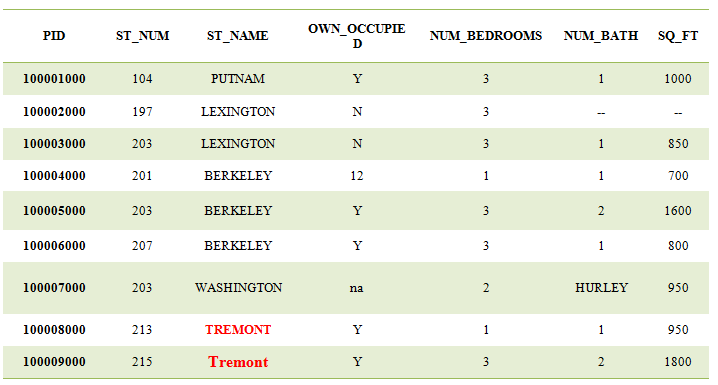 In some unstructured data, NaN values can be written as na, -- or N/A, and these are also examples of mislabelled data. So we have to find those values in the table and we have to assign it as NaN as follows:
In some unstructured data, NaN values can be written as na, -- or N/A, and these are also examples of mislabelled data. So we have to find those values in the table and we have to assign it as NaN as follows:
 Mislabel_values = [“na”,”--“,”N/A”]
df=pd.read_csv("Give file path",na_values=missing_values)
df['SQ_FT']=df['SQ_FT'].fillna(df.SQ_FT.median())
df['NUM_BATH']=df['NUM_BATH'].fillna(df. NUM_BATH.mode())
In the column named 'OWN_OCCUPIED', Most values are ‘Y’ so, it is better to replace the NA value with the most occurring value ‘Y’
df[‘QWN_OCCUPIED’]=df['QWN_OCCUPIED '].fillna(‘Y’)
Mislabel_values = [“na”,”--“,”N/A”]
df=pd.read_csv("Give file path",na_values=missing_values)
df['SQ_FT']=df['SQ_FT'].fillna(df.SQ_FT.median())
df['NUM_BATH']=df['NUM_BATH'].fillna(df. NUM_BATH.mode())
In the column named 'OWN_OCCUPIED', Most values are ‘Y’ so, it is better to replace the NA value with the most occurring value ‘Y’
df[‘QWN_OCCUPIED’]=df['QWN_OCCUPIED '].fillna(‘Y’)
 Now there is a number in column OWN_OCCUPIED, where one of the characters ‘Y’ or ‘N’ should be there. Similarly, there is word HURLEY present in column NUM_BATH, where a number is expected. These can be removed as follows:
First, we will see about removing the HURLEY word from the column and we will replace it with NaN. (A loop can be generated to replace all such values with NaN, which does not float)
count=0
for row in df['NUM_BATH']:
try:
float(row)
pass
except ValueError:
df.loc[count,'NUM_BATH']=np.nan
count+=1
And then we can replace these NaN values with Mode as mentioned below
df[‘NUM_BATH]=df['NUM_BATH'].fillna(df.NUM_BATH.median())
Now there is a number in column OWN_OCCUPIED, where one of the characters ‘Y’ or ‘N’ should be there. Similarly, there is word HURLEY present in column NUM_BATH, where a number is expected. These can be removed as follows:
First, we will see about removing the HURLEY word from the column and we will replace it with NaN. (A loop can be generated to replace all such values with NaN, which does not float)
count=0
for row in df['NUM_BATH']:
try:
float(row)
pass
except ValueError:
df.loc[count,'NUM_BATH']=np.nan
count+=1
And then we can replace these NaN values with Mode as mentioned below
df[‘NUM_BATH]=df['NUM_BATH'].fillna(df.NUM_BATH.median())
 It is very important to check the data types of all columns in the data frame before and after the conversion process. To check the data type of columns we can write
df.dtypes
we get the result as
Now it is showing that the data type of column ‘NUM_BATH’ as afloat. Basically, a number of bathrooms must be in integer format as it will not be a float value. So we have to convert the column in integer form as follows:
df['NUM_BATH'] = df['NUM_BATH'].astype(int)
df
Which will give results with converted ‘NUM_BATH’ column into integer form.
Similarly, as you can see in the same table in the column of ‘OWN_OCCUPIED’ instead of string value a numerical value b12 is present. In this scenario first, we have to check the data type of the column and if it does not match with other values in the column. In the above case replace that number by Y or N which appears most.
count=0
for row in df['OWN_OCCUPIED']:
try:
int(row)
df.loc[count,'OWN_OCCUPIED']=np.nan
except ValueError:
pass
count+=1
Now we can replace this NaN value with Y as follows:
df[‘QWN_OCCUPIED’]=df['QWN_OCCUPIED '].fillna(‘Y’)
It is very important to check the data types of all columns in the data frame before and after the conversion process. To check the data type of columns we can write
df.dtypes
we get the result as
Now it is showing that the data type of column ‘NUM_BATH’ as afloat. Basically, a number of bathrooms must be in integer format as it will not be a float value. So we have to convert the column in integer form as follows:
df['NUM_BATH'] = df['NUM_BATH'].astype(int)
df
Which will give results with converted ‘NUM_BATH’ column into integer form.
Similarly, as you can see in the same table in the column of ‘OWN_OCCUPIED’ instead of string value a numerical value b12 is present. In this scenario first, we have to check the data type of the column and if it does not match with other values in the column. In the above case replace that number by Y or N which appears most.
count=0
for row in df['OWN_OCCUPIED']:
try:
int(row)
df.loc[count,'OWN_OCCUPIED']=np.nan
except ValueError:
pass
count+=1
Now we can replace this NaN value with Y as follows:
df[‘QWN_OCCUPIED’]=df['QWN_OCCUPIED '].fillna(‘Y’)

