Hadoop Pig Introduction - Components and Commands of PIG
Hadoop Pig Introduction, Welcome to the world of Hadoop PIG Tutorials. In these Tutorials, one can explore Introduction to Hadoop PIG,Components and Commands of PIG. Learn More advanced Tutorials on introduction of Hadoop PIG from India’s Leading Hadoop Training institute which Provides Advanced Hadoop Course for those tech enthusiasts who wanted to explore the technology from scratch to advanced level like a Pro.
We Prwatech the Pioneers of Hadoop Training offering advanced certification course and Hadoop PIG Introduction to those who are keen to explore the technology under the World-class Training Environment.
Apache Hadoop Pig Introduction
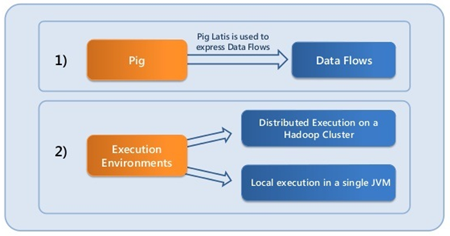
Apache Pig is a platform which is used to analyzing large data sets that consists of a high-level language for expressing data analysis programs, coupled with infrastructure for evaluating these programs. It supports many relational features making it easy to Join, group and aggregates data.
PIG has many things in common with ETL, if those ETL tools run over on many server simultaneously. Apache Pig is included in the Hadoop ecosystem. It is a front runner for extracting, loading and transforming various forms of data unlike, many traditional ETL tools which are good at structure data, HIVE and PIG are created to load and transform unstructured, structured and semi-structured data into HDFS.
Both PIG and HIVE make use of MapReduce function, they might not be as fast at doing non batch oriented processing. Some open source tool attempt to inform this limitation, but the problem still exists.
Components of PIG
ETL : It will extract data from sources A, B, and C but instead of transforming it first, you first load the row data into a database or HDFS.
Often the loading process requires no schema the data can remain in the repository, unprocessed for a longtime. That person might load the new , transformed data onto another platform such as Apache HBase.
VENDOR:
1. Yahoo: One of the heaviest user of Hadoop (core and Pig), runs 40% of all its Hadoop jobs with PIG.
2. Twitter: It is also well known user of PIG
Commands of PIG:
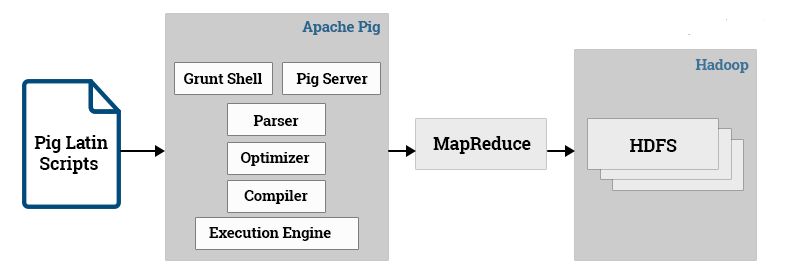
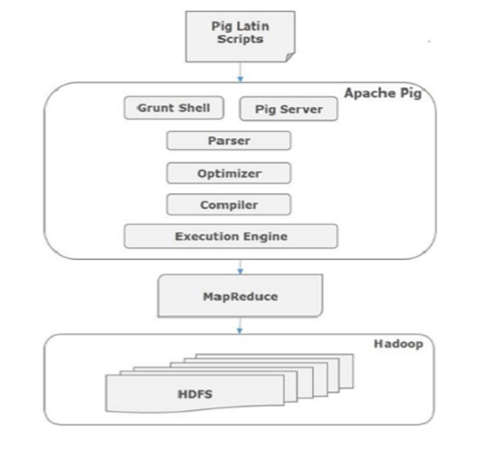
A high level data processing language called Pig Latin.
A compiler that compiles and runs Pig Latin scripts in a choice of evaluation mechanism. The main evaluation mechanism is Hadoop. Pig also supports a local mode for development purposes.
Data Flow Language:
We write Pig Latin Programs in a sequence of steps where each step is a single high-level data transformation. The transformation support relational style operations, such as filter, union, group and Join.
Even though the operations are relational in style, Pig Latin remains a data flow language. A flow language is friendlier to programmers who think in terms of algorithms, which are more natural of expressed by the data and the control flows. On the other hand, a declarative language such as SQL is preferr to just state the result.
Data Type :
“Pig eats anything”. Input data can come in any format. Popular format such as tab-delimit text files, are natively support. Users can add functions as well. Pig doesn’t require meta data or schema on data, but it can take advantage of them if they are provided.
The Pig can operate on data that is relational , nested ,semi-structured or unstructured .
Running PIG (PIG Shell):
Grunt: To enter PIG commands manually. It is ad hoc data analysis and performs interactive cycles of program development. The Grunt shell also supports file utility common ds such as ls and cp.
Script: Large Pig programs or ones that running are run in script file.
Pig Latin Data Model
The data model of Pig Latin is fully nest and it allows complex non-atomic datatypes such as map and tuple.
Example Data set : {Prwatech1,Hadoop,20000,Pune} {Prwatech2,Python,30000,Bangalore} {Prwatech3,AWS,12000,Pune}
Atom
Any single value in Pig Latin, irrespective of their data, type is known as an Atom. It is stored as string and can be used as string and number. int, long, float, double, chararray, and bytearray are the atomic values of Pig. A piece of data or a simple atomic value is known as a field.
Example − ‘Prwatech1’ or ‘Hadoop’
Tuple
A record that is formed by an ordered set of fields is known as a tuple, the fields can be of any type. A tuple is similar to a row in a table of RDBMS.
Example − (Prwatech1, Hadoop)
Bag
A bag is an unorder set of tuples. In other words, a collection of tuples (non-unique) is know as a bag. Each tuple can have any number of fields (flexible schema). A bag is represent by ‘{}’. It is similar to a table in RDBMS, but unlike a table in RDBMS, it is not necessary that every tuple contain the same number of fields or that the fields in the same position (column) have the same type.
Example − {(Prwatech1,Hadoop ), (Prwatech2, Python)}
A bag can be a field in a relation; in that context, it is known as inner bag.
Example − {Prwatech1, Hadoop, {20000, Pune,}}
Map
A map (or data map) is a set of key-value pairs. The key needs to be of type char array and should be unique. The value might be of any type. It is represent by ‘[]’
Example − [name#Prwatech1, Course#Hadoop]
Relation
A relation is a bag of tuples. The relations in Pig Latin are unorder (there is no guarantee that tuples are process in any particular order).
 2. Twitter: It is also well known user of PIG
2. Twitter: It is also well known user of PIG