Machine Learning Tutorial for Beginners
Machine Learning Tutorial for beginners: Machine Learning is the most in-demand technology in today’s market. In this blog on Introduction tIno Machine Learning, you will understand all the basic concepts of Machine Learning and Machine Learning Process steps, Machine learning types.
Are you the one who is looking for the best platform for the Machine Learning tutorial? Or do you want to become an expert as a Machine Learning Engineer, but thinking where to start? Then why to think… Prwatech is an excellent option for you to get Data Science Certification Course from basics to advanced level with 100% job assurance. We, India’s largest E-learning in Machine Learning are here to help you in learning Machine learning tutorials for beginners.
So, Let’s start our first topic “Machine Learning tutorial”.
Introduction to Machine Learning
Machine Learning is a field of study that enables computers to learn without explicit programming. It employs various algorithms and predictions to solve tasks in a scientific manner. Building mathematical models for training data involves specific algorithms based on statistics to make predictions without explicit programming. Given its myriad applications in real-life scenarios, different methods are employed as per requirement, utilizing specific algorithms to predict and obtain precise results.
Machine Learning Types
Machine learning falls under the following subclasses:
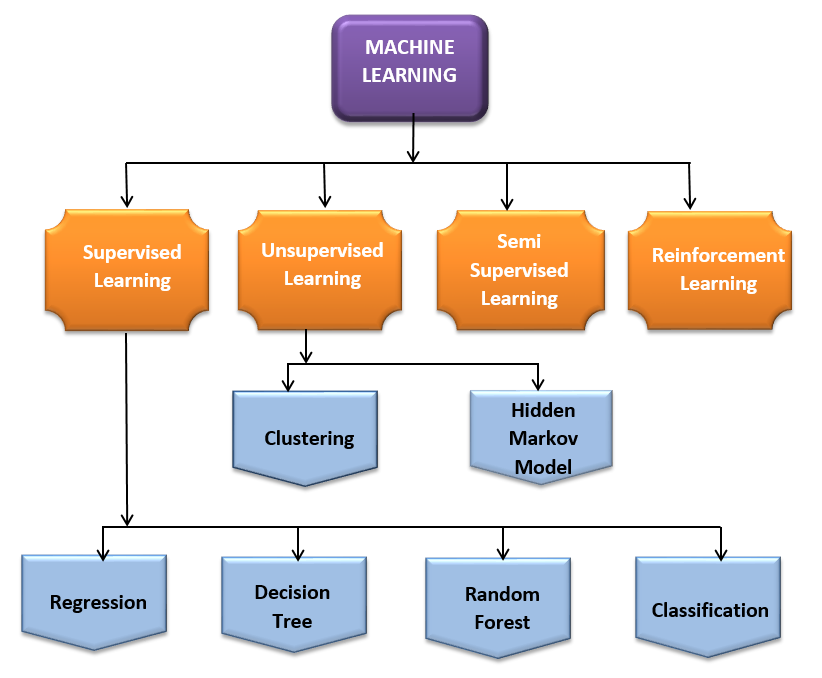
SUPERVISED LEARNING:
Supervised learning treats the labeled dataset as a trainer for the model, enabling the machine to learn and predict future values accordingly. It equips the system to provide predictive entities for any new input after adequate training. The learning algorithm can also relate its output with the correct, expected output, finding errors to provide feedback and modify the model accordingly.
UNSUPERVISED LEARNING:
Unsupervised learning comes into play when the information or dataset used for training is neither classified nor labeled. It aids in finding hidden structures from unlabeled data, uncovering hidden patterns and relationships in the dataset through clustering.
SEMI-SUPERVISED LEARNING:
Semi-supervised learning combines aspects of both supervised and unsupervised learning. It trains with labeled and unlabeled data, with the majority of data being unlabeled compared to labeled data.
Reinforcement Learning:
This learning category interacts with its environment by producing actions and discovering errors or correct output. Trial and error search and overdue reward are the most relevant characteristics of reinforcement learning. In supervised learning, the training dataset has answer keys with it, while in reinforcement learning, the machine tries to learn from acknowledged rewards or errors. It strives to obtain maximum rewards in the learning procedure for a particular input. The following image shows the overall view of categories in Machine Learning.
Machine Learning Process Steps:
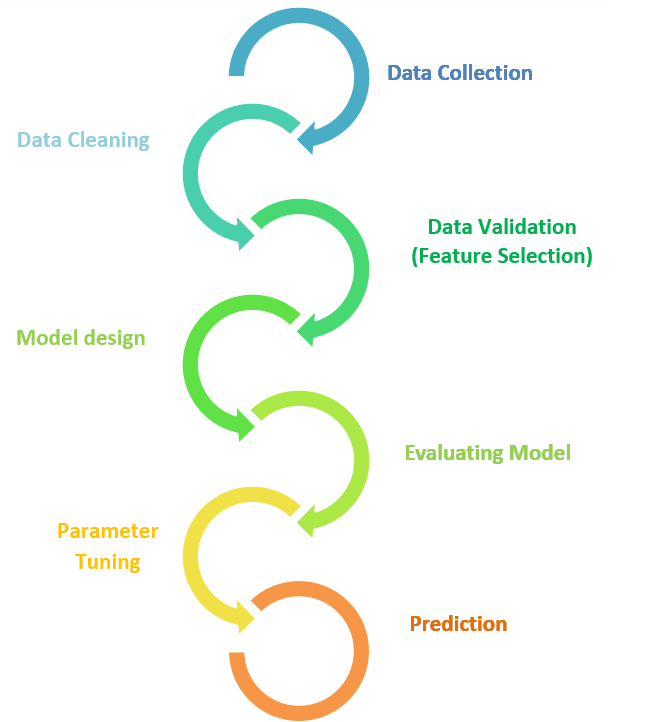
Steps involved in machine learning:
Data Collection:
This process involves collection of qualitative and quantitative data. The reference datasets can be collected from pre-collected data, through datasets from Kaggle, UCI, etc.
Data Cleaning:
Successful working of any model depends on qualitative dataset. So data cleaning is important step which includes wrangling data, removal of duplicates, correcting the errors, dealing with missing values, normalization, data type conversions etc.
Data Validation (Feature Selection):
It is process of picking up those features which are most contributing elements for dependant variable in prediction model. As irrelevant features decrease the performance of the model we have to choose only those which can help to train model for better prediction.
Model Design:
It is the step in which the model is designed based on the dataset. Different algorithms utilize to build a suitable model. According to supervised, unsupervised, and reinforcement types, algorithms are employed.
EVALUATING MODEL:
This step involves testing the performance of the model. The model trains with combinations of some datasets. Generally, 70% of the data from the set uses to train the model for objective performance, while the remaining 30% reserves for testing purposes.
PARAMETER TUNING:
This step involves tuning hyperparameters, which is one method to improve the performance of the model. It generally includes changes in certain functional parameters such as the number of training steps, learning rate, initialization values, and distribution, among others.
PREDICTION:
In the final step, the model is tested with unseen data. It generates results that show how the designed model approaches expected performance. If any unexpected result is obtained, then based on the requirement, some or all steps are repeated.
Thus, this marks the end of this machine learning tutorial for beginners' concepts. I hope you found this blog informative. If you have any thoughts to share, please comment below. Stay tuned for more blogs like these! Achieve success in your career as a Machine Learning Engineer or Data Scientist by being a part of Prwatech, India's leading Data Science training institute in Bangalore.

