Amazon Redshift

Amazon Redshift
Amazon Redshift, you can learn About Amazon Redshift. Are you the one who is looking for the best platform which provides information about Amazon Redshift? Or the one who is looking forward to taking the advanced Certification Course from India’s Leading AWS Training institute? Then you’ve landed on the Right Path.
The Below mentioned Tutorial will help to Understand the detailed information about Amazon Redshift, so Just Follow All the Tutorials of India’s Leading Best AWS Training institute and Be a Pro AWS Developer.
“Amazon Redshift” is a fully managed, petabyte-scale data warehouse service in the cloud platform. You can start with just a few 100 GB of data and scale to a petabyte or more. This enables you to use your data to acquire new insights for your business & customers.
Introduction
Redshift is a pretty new technology launched in late 2012. If you want to create a data warehouse then you have to launch a set of nodes, called an Amazon Redshift cluster. After you configured your cluster, you can upload your data set and then perform data analysis queries. Regardless of the size of the data set, Amazon Redshift offers faster query performance using the same SQL-based tools and business intelligence applications that you use today.
- OLAP: OLAP is an Online Analytics Processing System used by the Redshift.
- OLAP transaction Example:
Suppose we want to calculate the Net profit for EMEA and Pacific for the Digital Radio Product. This requires to pull a large number of records. Following are the records required to calculate a Net Profit:
- Sum of Radios sold in EMEA.
- Sum of Radios sold in the Pacific.
- Cost of per radio in each region.
- The sales price of each radio
- Sales price – unit cost
The complex queries are required to fetch the records given by the above. Data Warehousing databases use different types of architecture both from a database perspective and an infrastructure layer.
Redshift Configuration
Redshift consists of two types of nodes:
- Single node
- Multi-node
Single node: A single node stores up to 160 GB.
Multi-node: Multi-node is a node that consists of more than one node. It is of two types:
- Leader Node
It manages client connections and receives queries. A leader node receives the queries from the client applications, parses the queries, and develops the execution plans. It coordinates with the parallel execution of these plans with the compute node and combines the intermediate results of all the nodes, and then return the final result to the client application.
- Compute Node
A compute node executes the execution plans, and then intermediate results are sent to the leader node for aggregation before sending back to the client application. It can have up to 128 compute nodes.
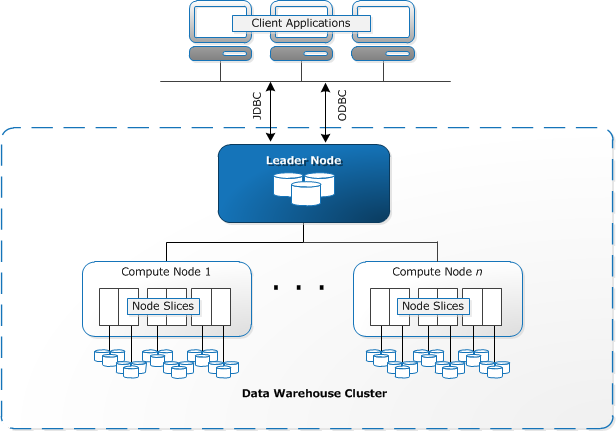
fig. Amazon Redshift Architecture and its components
- Client applications employ either JDBC or ODBC to connect to Redshift Data Warehouse. Amazon Redshift is based on the PostgreSQL database, so most existing SQL client applications will work with only minimal changes.
- An Amazon Data Warehouse is structured as a cluster. A cluster is one or more compute nodes. A cluster having more than one compute node appoints one node as a leader node. This leader node is responsible for communication with client applications and to distribute compiled code to other compute nodes for parallel processing. Once compute nodes return filtered records, the leader node combines results to form the final aggregated result.
- Node Slices is partitions within compute nodes to provide parallelism.
- Amazon Redshift is specifically made for data warehouse processing on your AWS cloud platform
- It can scale and performs well on the constantly improving AWS platform
- It’s considered easier to just learn (e.g. for RDBMS DBA’s) than the learning curve for Hadoop
- There are no upfront fees and you pay as you go.
Why Amazon Redshift?
1. If you want to start querying large amounts of data quickly
Amazon Redshift is built for querying big data. Instead of running taxing queries against your application database (or your read replica), you can run fast queries by setting up a dedicated BI database for running such queries.
You can connect to it via PostgreSQL clients and easily run PostgreSQL queries.
2. If your current data warehousing solution is too expensive
Price is often a very important factor when deciding what solution to use. Amazon offers Redshift at a cheap rate as $1000 per TB/year, which is a lot cheaper than many other solutions. Amazon Redshift is also scalable, so you can scale up clusters to support your data up to the petabyte level. More importantly, the flexible pricing structure allows you to pay for only what you use.
3. If you don’t want to manage hardware
Just like other AWS cloud services, Amazon will handle all the hardware on their end. This means you don’t have to worry about managing hardware issues, which could be quite a hassle if you are running everything on-premise.
In addition, monitoring can be done easily from the AWS Management Console. You can also set up alerts using Amazon CloudWatch to be quickly notified of any potential issues.
4. If you want higher performance for your aggregation queries
Amazon Redshift is a columnar database. As a columnar database, it is particularly good at queries that involve a lot of aggregations per column. This is especially true when you’re querying through the large amounts of data to gain insights against your data, such as when performing historical data analysis, or even when creating metrics for your recent application data.
5. If you want an easy way to move data to your data warehouse
There are often difficulties with continuously moving data to a data warehouse. However, because Redshift is within AWS, there are a few efficient ways to move the data over to your Redshift cluster. You can move data into Redshift from S3 using a COPY command or you can use Amazon’s Data Pipeline to start moving data to Redshift from other AWS sources. Additionally, you can try third-party vendors like our FlyData Sync to continually keep your MySQL instances synced with your Redshift cluster.
AWS Redshift Features
Here are the Amazon Redshift top features list:
- Optimizing the Data Warehousing
- Petabyte Scale
- Automated Backups
- Restore the data fast
- Network Isolation
1.Optimizing the Data Warehousing
Mostly the Amazon Redshift will make use of a variety of innovations to obtain the high quality of results on the datasets that range from hundred GB’s to an Exabyte and even more than that too. Whereas coming to the Petabyte sector, the local data use the columnar storage to compress and reduce the data according to the need to perform the queries.
2. Petabyte Scale
By using just a few clicks in the console and Simple API call, you can avail to change all the types of nodes that contain in the What is Data Warehouse by scaling the Petabyte data by compressing the user data.
3. Automated Backups
The data in the Amazon can be automatically and continuously set to get the backups directly from the new data to Amazon S3. Introduction by using this Amazon Redshift. It can be able to store all the snapshots of you for a particular period from 1-35 days approximately. You are also eligible to take your snapshots at any time by retaining the deleted data.
4. Restore the data fast
The Amazon Redshift is also used for any system or the user snapshot to restore the entire cluster quickly through AWS management consoles and API’s. The cluster is available according to the system metadata to restore all the running queries that spooled down the background.
5. Network Isolation
The network Isolation at Amazon Redshift enables the users to configure all the firewall rules, which can also give and network control access to your data warehouse cluster. With this, you can even process inside the Amazon VPC, particularly to isolate the data warehouse and connect automatically to the existed IT infrastructure.
Benefits of Amazon Redshift
The following are some of the major benefits of using the Amazon Redshift:
- Fast Performance
- Inexpensive
- Extensible
- Scalable
- Simple to Use
- Compatible
- Secured
1. Fast Performance:
The Amazon Redshift can deliver fast query performance with the help of column storage technology across the various nodes. The data load can speed up all the scales with the cluster size along with the various integrations like Amazon DB, Amazon EMR, Amazon S3, etc.
2. Inexpensive:
In this AWS Redshift, you can pay the amount on what you use for. You can also get an unlimited number of clients along with the unmetered analytics for your 1 TB data at just $1000/ years and 1/10th of the cost for the remaining traditional warehouse data solutions. To reduce the cost between the $250-$333 per year, the clients are compressing the data plan according to it.
3. Extensible:
The Redshift spectrum at AWS will enable the users to run the queries concerning the data in the Amazon S3 that can be stored on local disks of Amazon Redshift. You can also make use of the SQL syntax as well as the BI tools to store the highly structured and frequent access data to keep all the amounts of data safely.
4. Scalable to Use:
The Amazon Redshift is very easy to resize the ups and downs of the cluster according to your performances and capacity, which needs a few clicks to console with a simple API call.
5. Simple:
The Amazon Redshift will allow the users to automate all the administrative tasks to scale, monitor and manage all the data that consists of a warehouse. BY handling this process, you can consume less time and free up to focus as well as on the data and your business.
6. Compatible:
The compatible model at Amazon Redshift will support all the standard SQL by providing the custom ODBC and JDBC drivers to console the use of SQL customers.
7. Secured:
The security at Amazon Redshift is the built-in option, which is specifically designed to encrypt the data in transit and rest at the clusters of Amazon VPC and also helps to manage the keys by using the AWS KMS and HSM.
How to get started with Amazon Redshift?
Let’s discuss the key steps to start with AWS Redshift:
Step1: If you are not having an AWS account, sign up for one. If you already have an account, use the existing AWS account.
Step2: In this step, create an IAM role to access data from Amazon S3 buckets. In the next step, you will attach a role to your cluster.
Step3: Now launch an Amazon Redshift cluster.
Step4: To connect with the cluster, you need to configure the security settings to authorized the cluster access.
Step5: Connect to the cluster and run the queries on the AWS management console with the query editor.
Step6: Now create tables in the database and upload the sample data from Amazon S3 buckets.
Step7: Finally, find additional resources and reset your environment according to your requirements.
Conclusion
“Amazon Redshift” is a dominant technology in the modern analytics toolkit, which allows business users to analyze datasets and run into billions of rows with agility and speed. Other data analytics tools like Tableau connects to Amazon Redshift for advanced speed, scalability, and flexibility, accelerating the results from days to seconds. With AWS Redshift potential, the user can analyze vast amounts of data at the speed of thought and get into action immediately.
#Last but not least, always ask for help!






