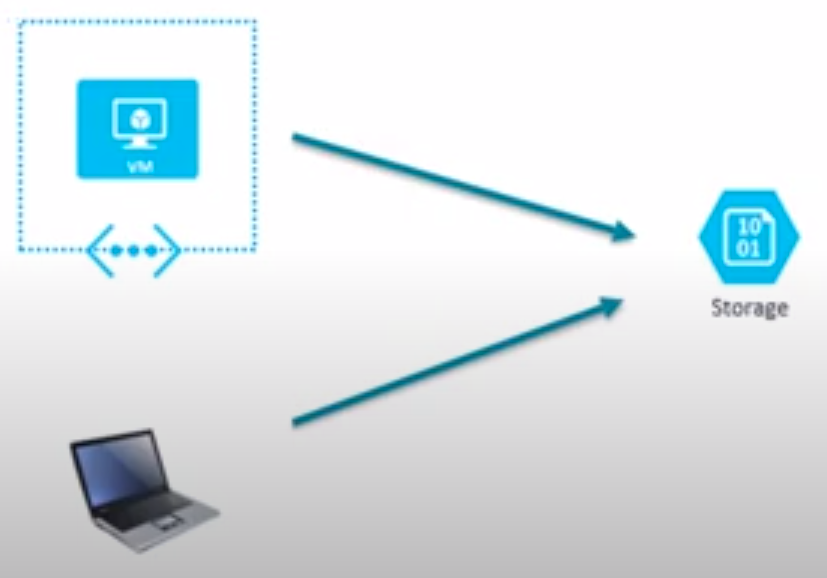
Hands-on
UI of the logic app, click on add to create a new logic app.
Select the subscription and create the resource group
Give the name to the logic app and select the region.
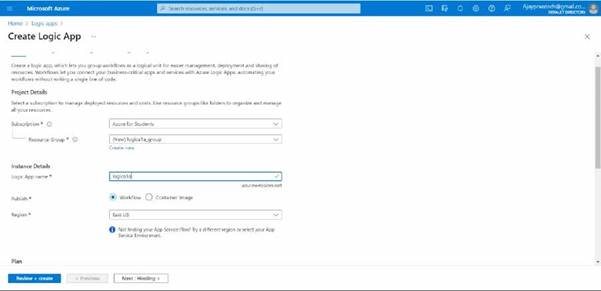
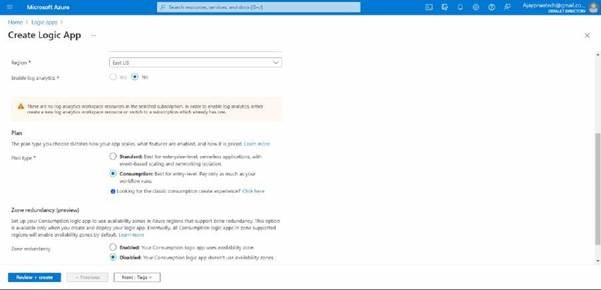
Try to select the plan as a consumption
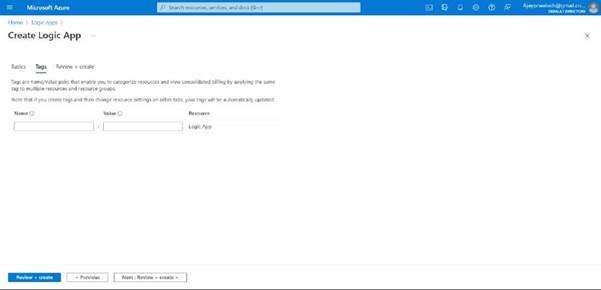
In tags session, no need to enter anything
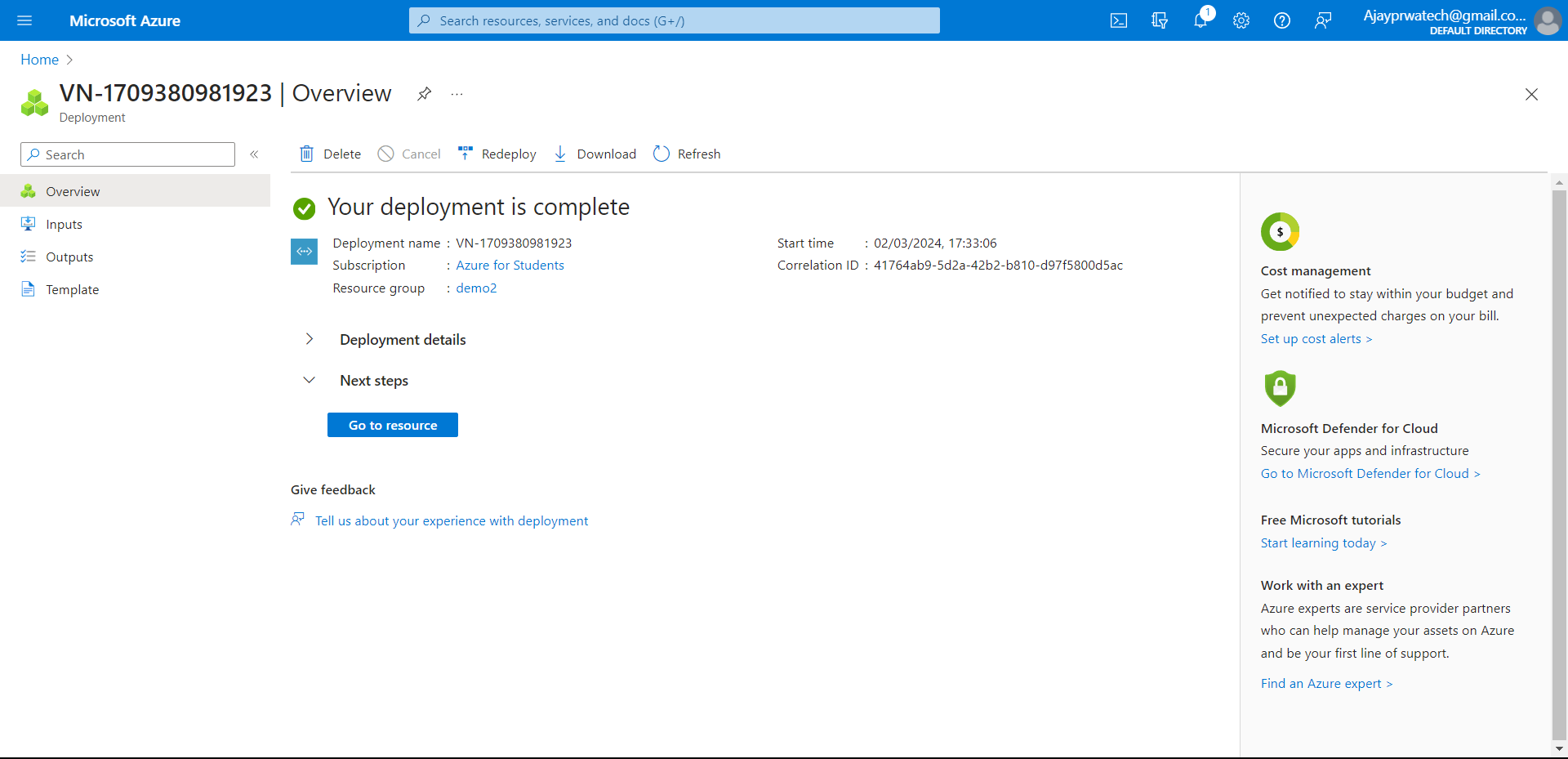
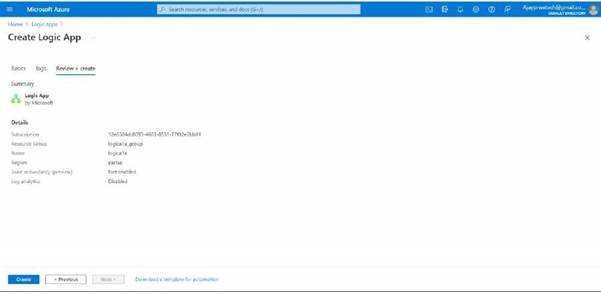
Now can review the details that we have entered and click on Create.
Here you can see the overview of the logic app
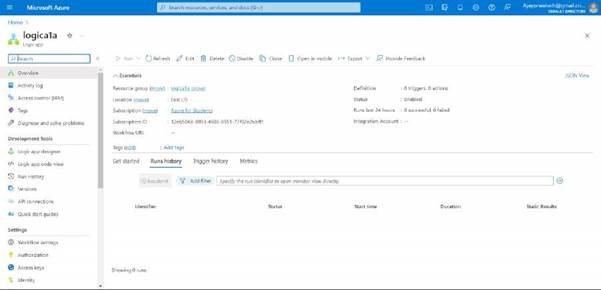
you can see the logic app designer on the left side, click on it.

Here you can see the different types of templets
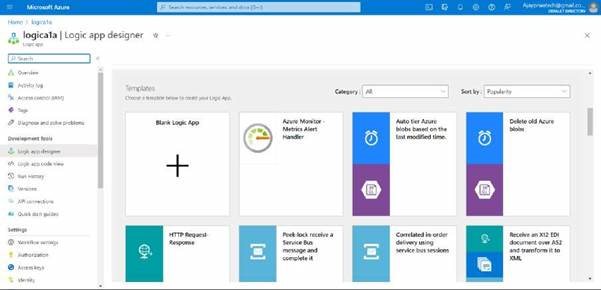
Now I’ll try to select the “Delete old Azure blobs” and click on Use template
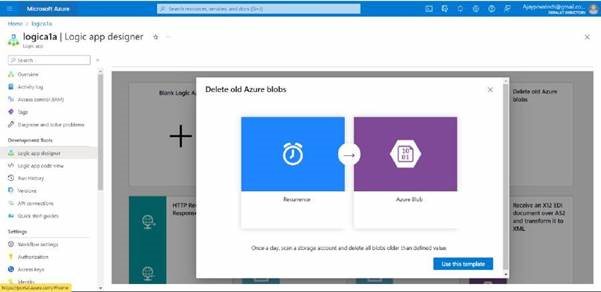
in this click on create
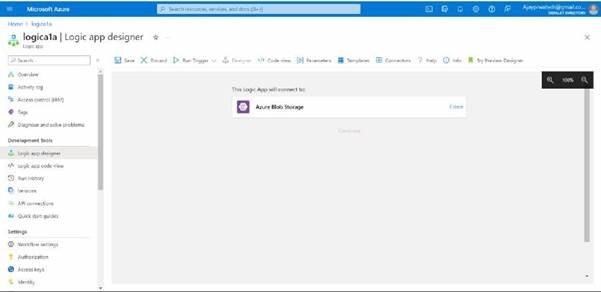
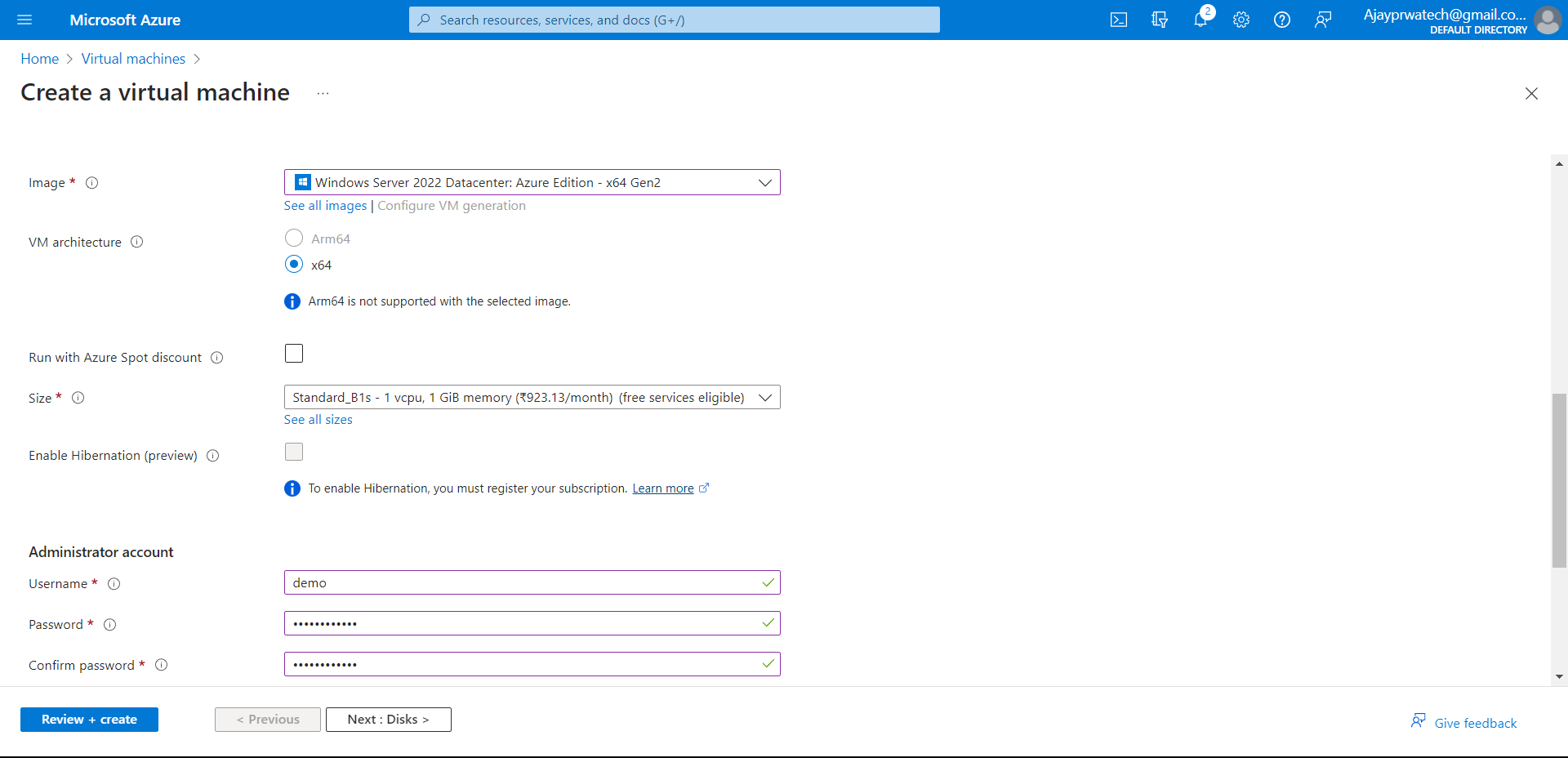
Here we need to add the details, I’ll give the name as a demo and I’ll select the access key as the authentication type for the storage account.
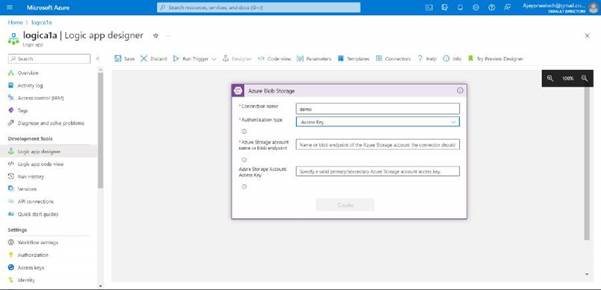
Now for this, we need to have a storage account, so we will create the storage account and files in it.
It’s the UI of the storage account. Click on Create.
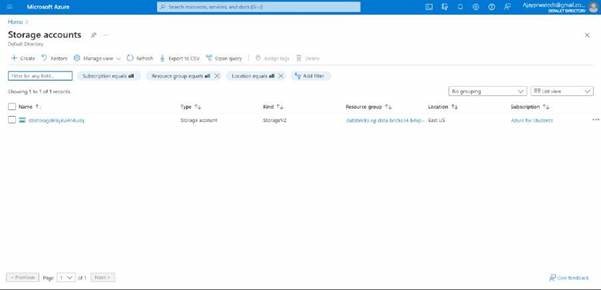
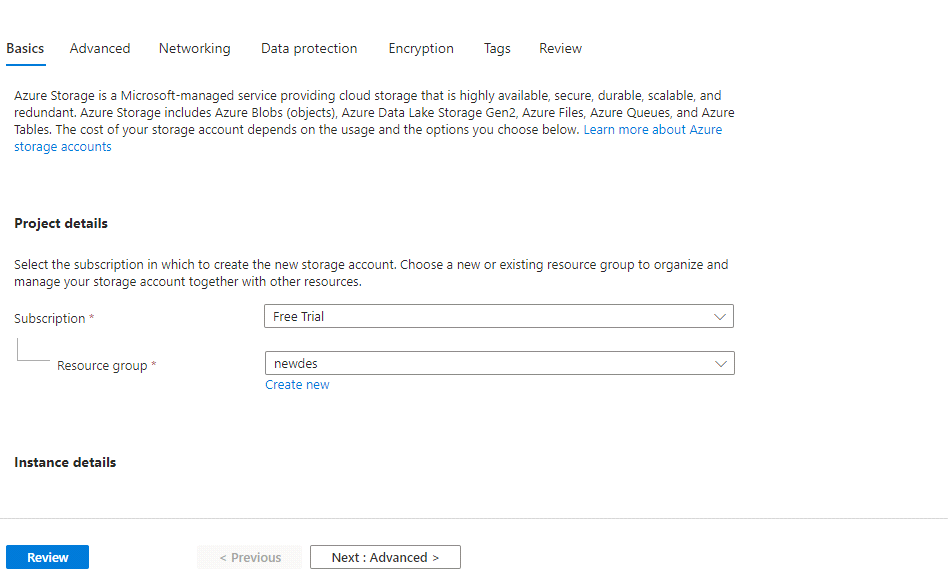
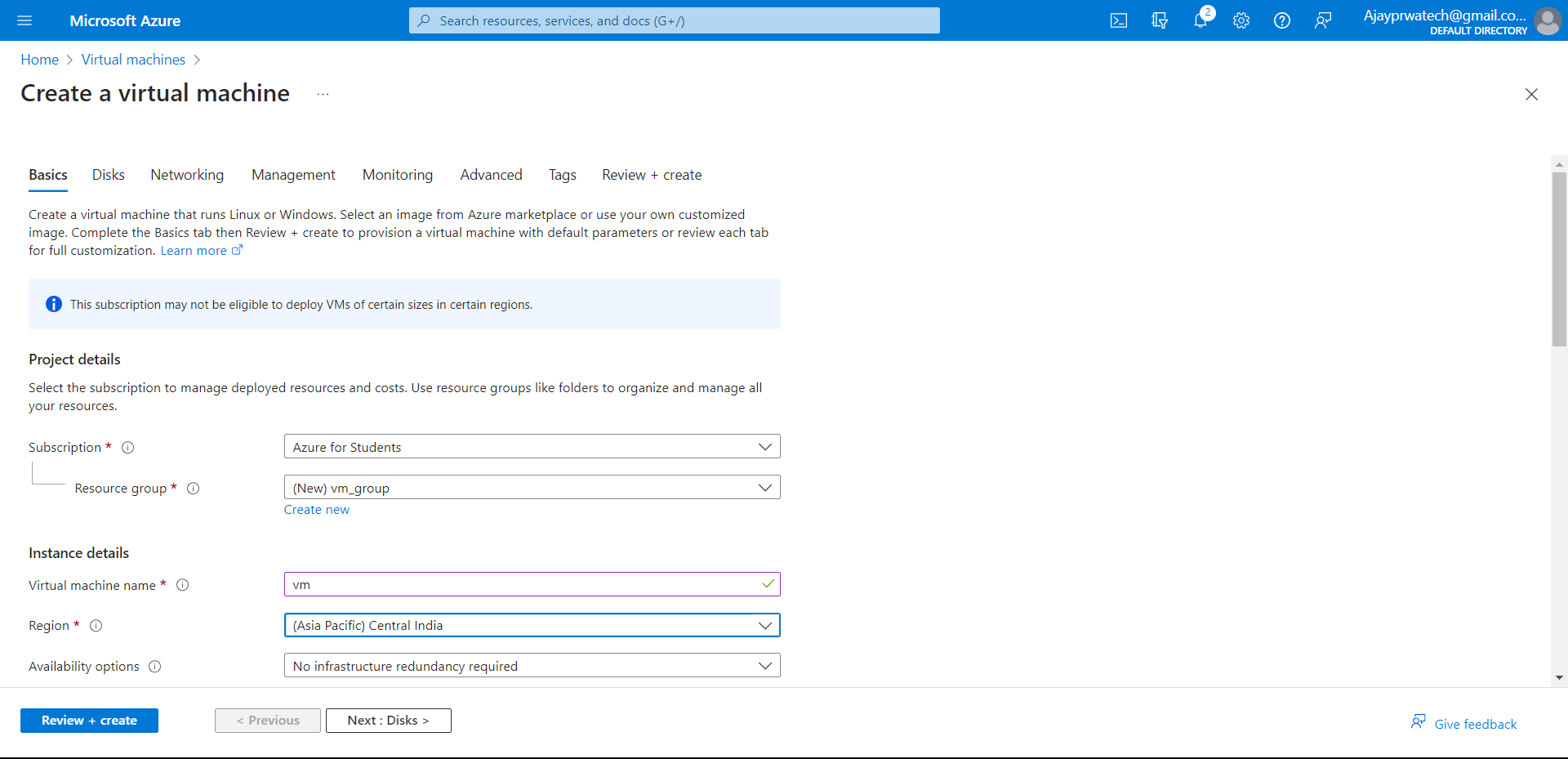
Now we will try to select the subscription and we will create the resource group for that.
We will give a name for the storage account.
In advance let it be default
In the network also it should be the default
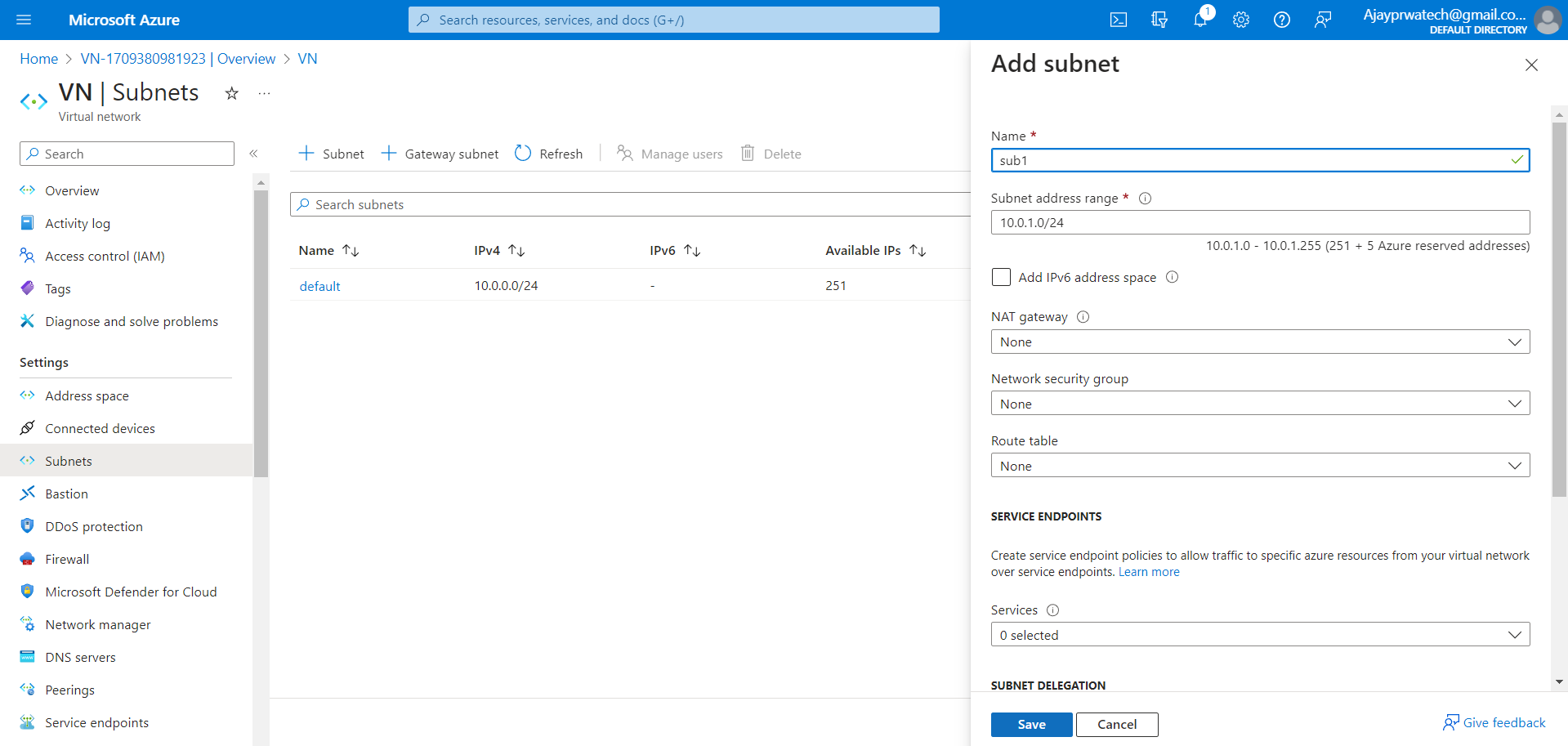
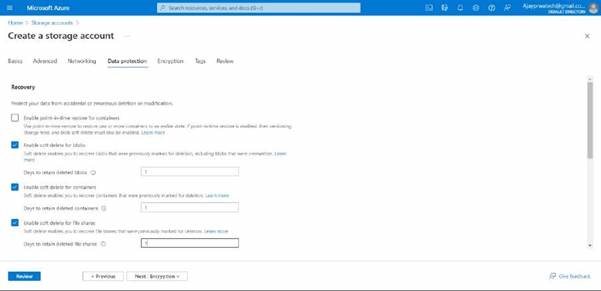
Here in data protection, we can give 1-365 days in all the options which are shown below, as I have given 1 day
Here no need to change anything, if we want we can create CMK
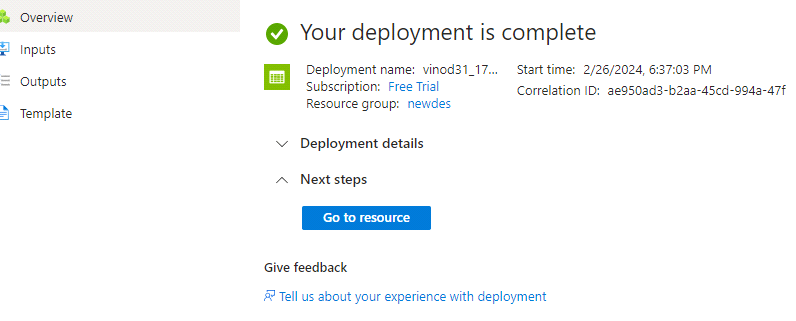
now you can review and click on create
here you can see we have created
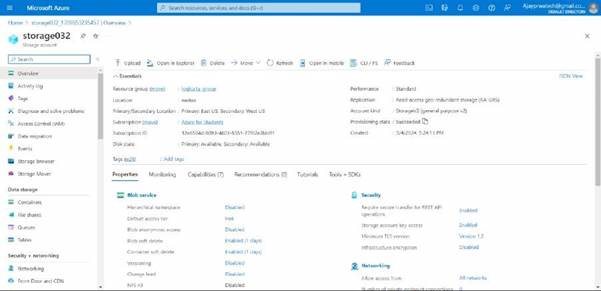
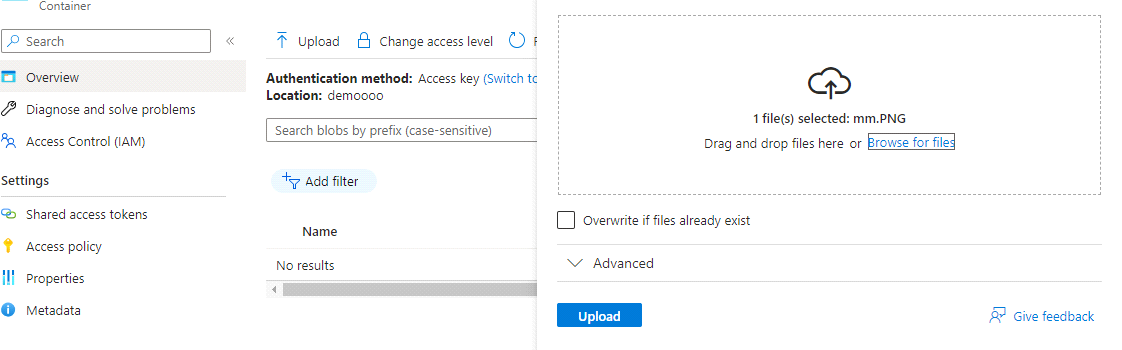
Now we will try to add the files to it.
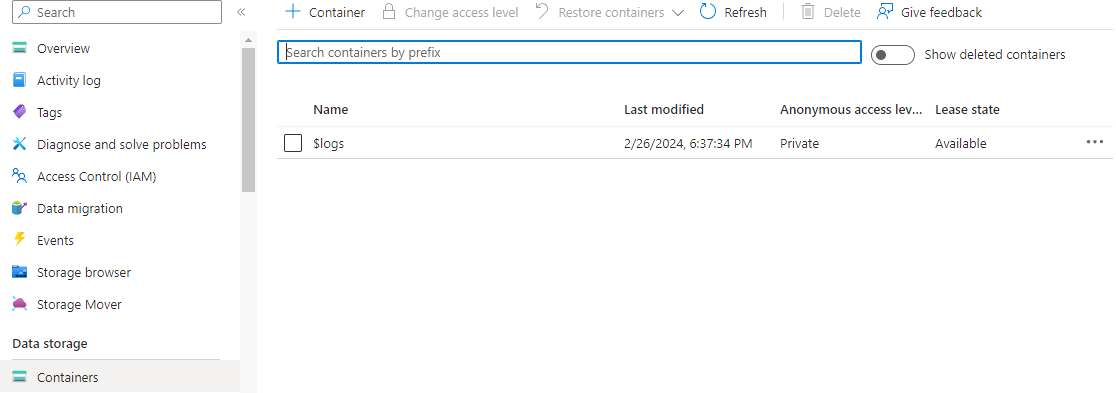
For that click on container and add files in it.
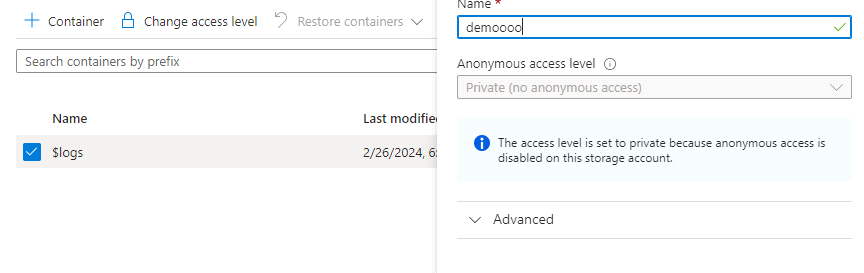
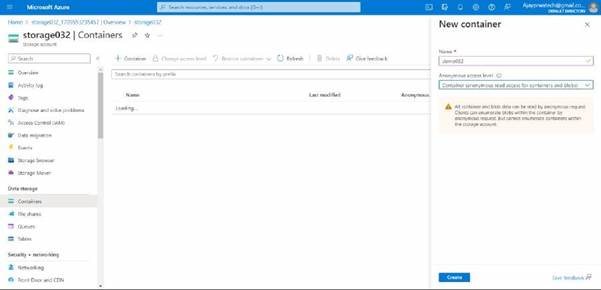
Here you can see, that we need to give a name to the container and select the anonymous access level
Here you can see we have created the container.
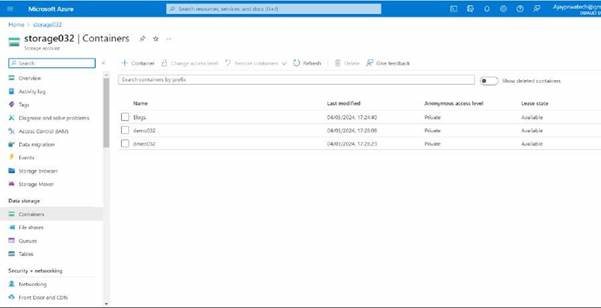
Now we will try to add this storage account ID and name to logic apps
For these fields
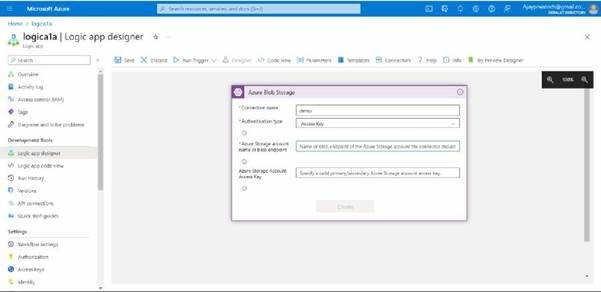
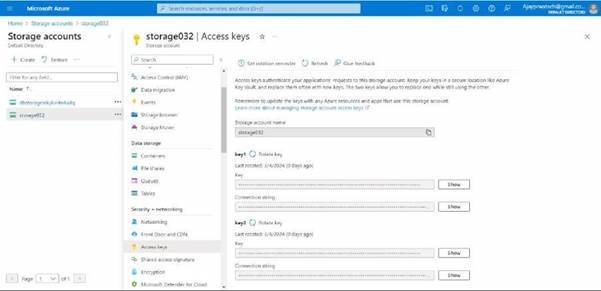
Here you can see the storage account access key and name.
Try to and copy paste it in to the logic app.
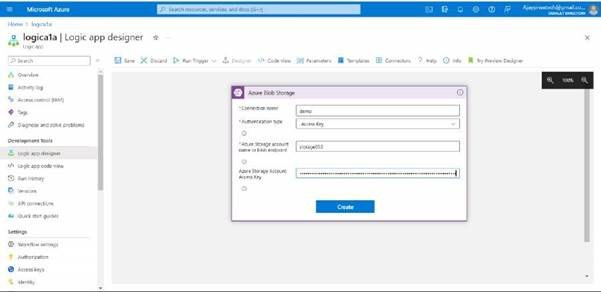
Here you can see I have copy pasted
Here you can see it has been created, just click on continue to proceed.
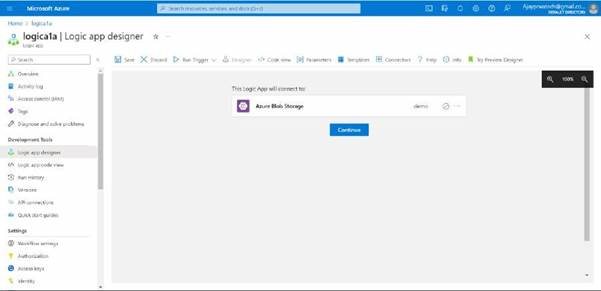
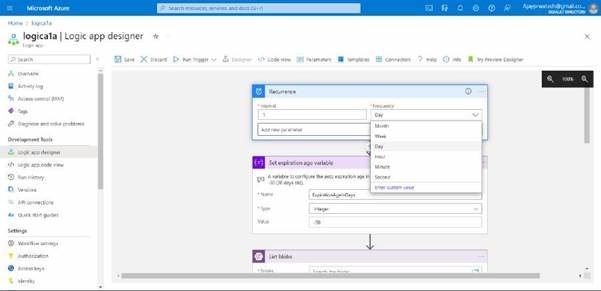
In this you can see we can change the interval and frequency based on our requirements
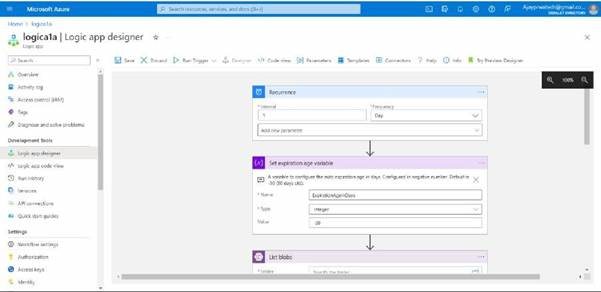
you can see.
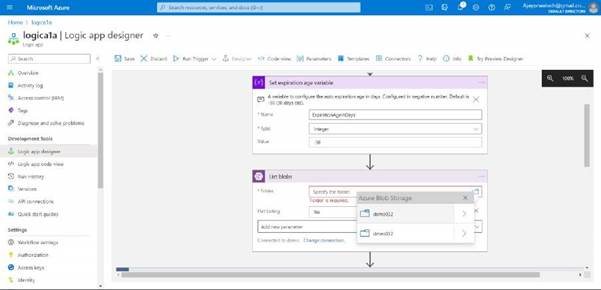
Here we need to select the folder
you can add a condition, I’ll just leave it as it is and click on save
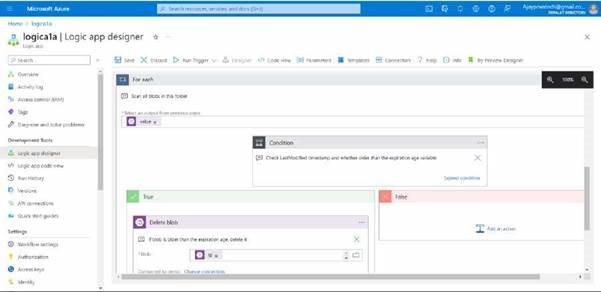
Here you can see it has been saved, now you can run trigger it, and see.
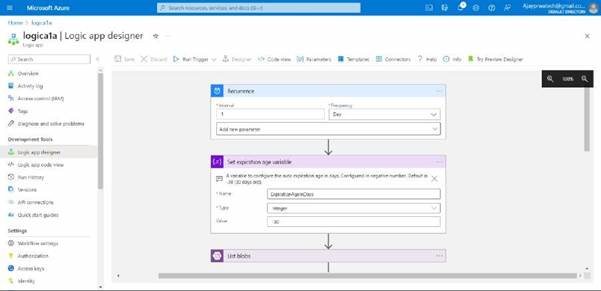
you can see it has been successfully executed, as we have not added the files so it’s showing an error in list blobs.
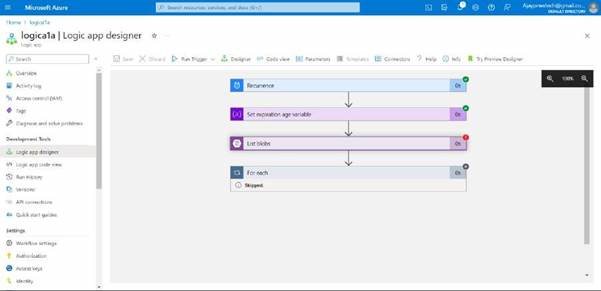
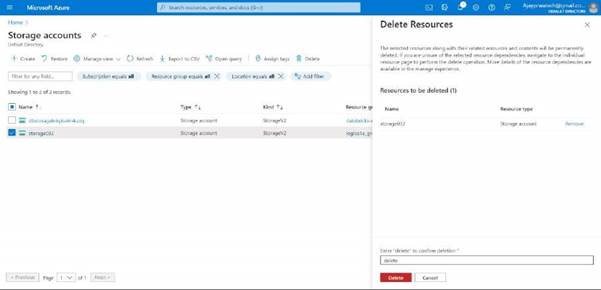
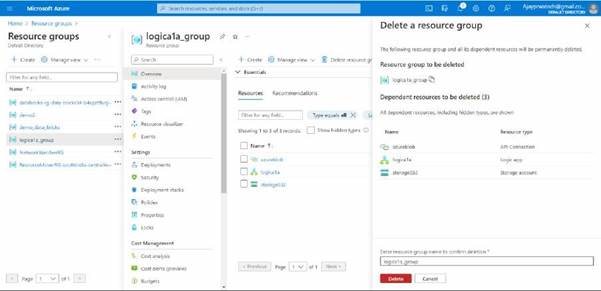
After these try to delete the resource groups and logic apps along with the storage account.
Deleting resource group.
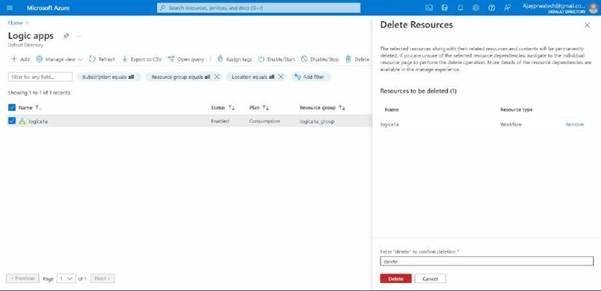
Delete logic app
Delete storage account