Hadoop GCP with Hive
GCP Hadoop Hive Tutorials
 ♦ In Cloud Shell, set the default Compute Engine zone to the zone where you are going to create your Cloud Dataproc clusters.
♦ In Cloud Shell, set the default Compute Engine zone to the zone where you are going to create your Cloud Dataproc clusters.
export REGION=us-central1 export ZONE=us-central1-a gcloud config set compute/zone $ZONE
 ♦ Enable the Cloud Dataproc and Cloud SQL Admin APIs by running this command in Cloud Shell:
♦ Enable the Cloud Dataproc and Cloud SQL Admin APIs by running this command in Cloud Shell:
gcloud services enable dataproc.googleapis.com sqladmin.googleapis.com
export PROJECT=$(gcloud info --format='value(config.project)') gsutil mb -l $REGION gs://$PROJECT-warehouse
 ♦ Create a new Cloud SQL instance that will later be used to host the Hive metastore :
♦ Create a new Cloud SQL instance that will later be used to host the Hive metastore :
gcloud sql instances create hive-metastore \
--database-version="MYSQL_5_7" \
--activation-policy=ALWAYS \
--gce-zone $ZONE
 ♦ Create the first Cloud Dataproc cluster:
♦ Create the first Cloud Dataproc cluster:
gcloud dataproc clusters create hive-cluster \
--scopes sql-admin \
--image-version 1.3 \
--initialization-actions gs://dataproc-initialization-actions/cloud-sql-proxy/cloud-sql-proxy.sh \
--properties hive:hive.metastore.warehouse.dir=gs://$PROJECT-warehouse/datasets \
--metadata "hive-metastore-instance=$PROJECT:$REGION:hive-metastore"
 ♦ Copy the sample dataset to your warehouse bucket:
♦ Copy the sample dataset to your warehouse bucket:
gsutil cp gs://hive-solution/part-00000.parquet \ gs://$PROJECT-warehouse/datasets/transactions/part-00000.parquet
gcloud dataproc jobs submit hive \
--cluster hive-cluster \
--execute "
CREATE EXTERNAL TABLE transactions
(SubmissionDate DATE, TransactionAmount DOUBLE, TransactionType STRING)
STORED AS PARQUET
LOCATION 'gs://$PROJECT-warehouse/datasets/transactions';"
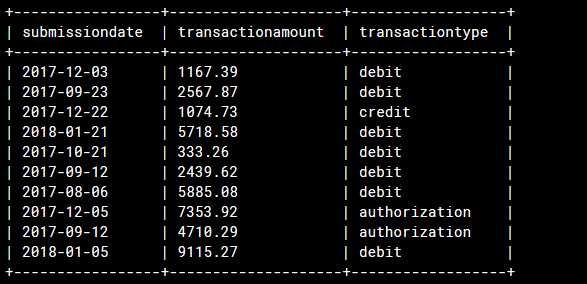
 ♦ Run the following simple HiveQL query to verify that the parquet file is correctly linked to the Hive table:
♦ Run the following simple HiveQL query to verify that the parquet file is correctly linked to the Hive table:
gcloud dataproc jobs submit hive \
--cluster hive-cluster \
--execute "
SELECT *
FROM transactions
LIMIT 10;"