Share Ideas, Start Something Good.

Our Clients







If you want to join the basic & advanced Hadoop Training in Bangalore, then you are at the right place! Here at PrwaTech, we offer advanced Hadoop courses with the best professors. We have the best tech enthusiast in our group who designed & Experienced amazing software. The certified trainers of PrwaTech help you to get deep knowledge and real-time experience on projects. We have the best trainers who are capable of delivering the best opportunity for the freshers as well as experienced.
PrwaTech invites you to enroll in our Hadoop Admin Training in Bangalore and become a first rate Hadoop Administrator. This training Course is designed by professionals to provide practical skills and knowledge to become a successful Hadoop Administrator. Learn from experts, get all your queries answered and enjoy 24/7 support and get unlimited access to tutorials.
Bangalore is the hub of IT learning institutes, and if you are a newcomer, then you feel confused, right? If you have the same feeling as this, then you can join our class now! We are the best commercial e-learning institute that offers certified courses. By joining Training Institute for Hadoop in Bangalore, you can receive complete knowledge about Technology. If you have completed your academics this year and searching for a job, then wait a minute!
Before joining any company, strengthen the skills that give you extra chances and the best positions in your company. If you want to learn some advanced IT learning courses in Bangalore to strengthen your resume, then Prwatech for Hadoop Training is the best platform!
Why should you join Training Institute for Hadoop in Bangalore?
By joining this Hadoop Training Institute in Bangalore, you can not only sharpen your basic knowledge but also learn some advanced and extra topics that make you unique from others. We know what is trending in the market and what recruiters are searching for in a candidate. We will cover all the chapters and topics in a minimum time period. Here you can learn theoretical as well as practical knowledge. We also provide daily assignments, projects, q & A events, and many more things that can double up your e-learning experience.
Want to be a pro IT expert?
We are the most trusted Hadoop Training Institute in Bangalore, where you can know how important it is to learn Hadoop and what is Hadoop cluster. This course covers the Hadoop 2.x Architecture, RDD in Spark and implementing map Reduce integration, and many more. You can also ask your doubts at any time with just a few clicks, and our expert pro teachers will support you instantly. We are serving the nation for more than 10+ years, and many of our students were situated in the top industries. If you also want to show yourself at the peak of success, then enroll yourself today and live your dreams!
Contact Us +91 8147111254
Learning Objective : In this module, you will explore what is BigData, What are its limitations of the existing solutions for BigData problem, How Hadoop solves the Big Data problem, What are the common Hadoop ecosystem components, How Hadoop Architecture works, HDFS and Map Reduce Framework, and Anatomy of File Write and Read in HDFS .
Learning Objective : In this module, you will learn the Hadoop 1.x and 2.x Cluster Architecture and Setup, Important File Configurations in Hadoop Cluster and Data Loading Techniques .
Topics,
- Hadoop 2.x Cluster Architecture
- Federation and High Availability Architecture
- Typical Production Hadoop Cluster
- Hadoop Cluster Modes
- Common Hadoop Shell Commands
- Hadoop 2.x Configuration Files
- Single Node Cluster & Multi-Node Cluster set up
- Basic Hadoop Administration
Learning Objective : This module will help you understand multiple hadoop server roles such as Namenode & Datanode and their responsibilities and MapReduce data processing. You will also understand the Hadoop 1.0 cluster setup and configuration, steps in setting up Hadoop clients using Hadoop 1.0, and important Hadoop configuration files and parameters .
Topics,
- Hadoop Installation and Initial Configuration
- Deploying Hadoop in fully-distributed mode
- Deploying a multi-node Hadoop cluster
- Installing Hadoop Clients
- Hadoop server roles and their usage
- Rack Awareness
- Anatomy of Write and Read
- Replication Pipeline
- Data Processing
Learning Objective : In this module, you will be understanding all the regular Cluster Administration task such as adding and removing data nodes, namenode recovery, configuring backup and recovery in hadoop, Diagnosing the node failure in the cluster, Hadoop upgrade etc.
Topics,
- setting up Hadoop Backup
- Whitelist and Blacklist data nodes in cluster
- setup quota’s, upgrade hadoop cluster
- Copy data across clusters using distcp
- Diagnostics and Recovery
- Cluster Maintenance
- Configure rack awareness
Learning Objective : Flume is a standard, simple, robust, flexible, and extensible tool allows data ingestion from various data producers (web servers) into Hadoop.
Topics,
- What is Flume
- Why Flume
- Importing Data using Flume
- Twitter Data Analysis using Hive
Learning Objective : In this module, we will learn about analytics with PIG. About Why Pig used, Pig Latin scripting, complex data type, different cases to work with PIG. Execution environments, operation & transformation.
Topics,
- Execution Types
- Grunt Shell
- Pig Latin
- Data Processing
- Schema on read Primitive data types and complex data types and complex data types
- Tuples Schema
- BAG Schema and MAP Schema
- Loading and storing
- Validations in PIG, Type casting in PIG
- Filtering, Grouping & Joining, Debugging commands (Illustrate and Explain)
- Working with function
- Types of JOINS in pig and Replicated join in detail
- SPLITS and Multi query execution
- Error Handling
- FLATTEN and ORDER BY parameter
- Nested for each
- How to LOAD and WRITE JSON data from PIG
- Piggy Bank
- Hands on exercise
Learning Objective : This module will cover to Import & Export Data from RDBMS(MySql, Oracle,Plsql) to HDFS & Vice Versa
Topics,
- What is Sqoop
- Why Sqoop
- Importing and exporting data using sqoop
- Provisioning Hive Metastore
- Populating HBase tables
- SqoopConnectors
- What are the features of sqoop
- Multiple case with HBase using client
- What are the performance benchmarks in our cluster for sqoop
Learning Objectives : This module will allow you to explore all the advanced HBase concepts. You will also learn what Zookeeper is all about, how It helps in monitoring a cluster, why HBase uses zookeeper and how to build an application with zookeeper.
Topics,
- The Zookeeper Service : DataModel
- Operations
- Implementations
- Consistency
- Sessions
- States
Learning Objective : in this module, you will understand the newly added features in Hadoop 2.0, namely MRv2, Namenode’s High Availability, HDFS federation, support for Window etc.
Topics,
- Hadoop 2.0 New Feature : Name Node High Availability
- HDFS Federation
- MRv2
- YARN
- Running MRv1 in YARN
- Upgrade your existing MRv1 to MRv2
In this module, will work on Hadoop MapReduce Framework. How MapReduce implement on Data which is stored in HDFS. Know about input split, input format & output format,Mapreduce flow, Overall Map Reduce process & different stages to process the data.
Topics,
- Map Reduce Concepts
- Mapper and Reducer
- Driver
- Record Reader
- Input Split(Input Format (Input Split and Records, Text Input, Binary Input, Multiple InputOverview of InputFileFormat
- Hadoop Project : MapReduce Programming
In this module, we will discuss a data warehouse package which analyses structured data. About Hive installation and loading data, Storing Data in different file formats in different Hive tables.
Topics,
- Hive Services and Hive Shell
- Hive Server and Hive Web Interface (HWI)
- Meta Store
- Hive QL
- OLTP vs. OLAP
- Working with Tables
- Primitive data types and complex data types
- Working with Partitions
- User Defined Functions
- Hive Bucketed Table and Sampling
- External partitioned tables, Map the data to the partition in the table
- Writing the output of one query to another table, Multiple inserts
- Differences between ORDER BY, DISTRIBUTE BY and SORT BY
- Bucketing and Sorted Bucketing with Dynamic
- RC File, ORC, SerDe : Regex
- MAPSIDE JOINS
- INDEXES and VIEWS
- Compression on Hive table and Migrating Hive Table
- How to enable update in HIVE
- Log Analysis on Hive
- Access HBase tables using Hive
- Hands on Exercise
Learning Objective : Apache Oozie is a workflow scheduler for Hadoop. Oozie is the tool in which all sort of programs can be pipelined in a desired order to work in Hadoop’s distributed environment. Oozie also provides a mechanism to run a job at a given schedule.
Topics :
- What is Oozie
- Architecture
- Kinds of Oozie Jobs
- Configuration Oozie Workflow
- Developing & Running an Oozie Workflow (MapReduce, Hive, Pig, Sqoop)
- Kinds of Nodes
Learning Objectives: This module includes Apache Spark Architecture, Spark features , How to use Spark with Scala and How to deploy Spark projects to the cloud Machine Learning with Spark. Spark is a unique framework for big data analytics which allows very fast data processing.
Topics :
- Spark Introduction
- Architecture
- Functional Programming
- Collections
- Spark Streaming
- Spark SQL
- Spark MLLib
Hadoop Training in Bangalore!
We provide extensive Hadoop Training and certification courses in Bangalore taking the course with us have its Own Benefits. Our Qualified Industry Certified Experts have More Than 20+ Years of Experience in the Current Hadoop Domain and They Know well about the industry Needs. This makes Prwatech as Bangalore’s leading Training Institute for Hadoop. We have a very deep understanding of the industry needs and what skills are in the demand, so we tailored our Hadoop classes as per the current It Standards. We have Separate batches for Weekends, Week batches and we Support 24*7 regarding any Queries. Best Hadoop Admin Training in Bangalore offering the best in the industry Certification courses which incorporate course which is fulfilling the Current IT Markets Needs Successfully.
Benefits of Hadoop Training in Bangalore @ Prwatech
- 100% Job Placement Assistance
- 24*7 Supports
- Support after completion of Course
- Mock tests
- Free Webinar Access
- Online Training
- Interview Preparation
- Real Times Projects
- Course Completion Certificate
- Weekly Updates on Latest news about the technology via mailing System
- During various sessions, one can learn the use of different tools of this framework.
Experts in the Big Data and Hadoop industries have put together the Big Data Hadoop Training Course, which will teach you all you need to know about Big Data and Hadoop Ecosystem products like HDFS, YARN, MapReduce, Hive, Sqoop, Pig, HBase, Oozie, Flume, and Apache Spark. Upon completion, you will be tasked with working on a Hadoop project with real-time use cases.
The fastest-growing technology for managing massive amounts of data so that data analytics can be performed is called big data. With the aid of this Big Data Hadoop course, you will be able to quickly acquire the most difficult professional abilities. Big Data specialists are in high demand since nearly all of the leading multinational corporations (MNCs) seek to enter the Hadoop Big Data space. You may learn Big Data and advance your career in the Big Data field with the aid of our online training programme. You’ll be working on several real-world projects to improve your big data expertise much more quickly. When it comes to applying for the best jobs, obtaining the Big Data certification from Prwatech might put you in a different league and advance your career.
This course is designed for both IT professionals and recent graduates who want to become Big Data Hadoop Developers by learning and exploring the fundamentals of Big Data Analytics using Hadoop and Spark Framework. The course’s primary audience consists of ETL developers, software professionals, and analytics professionals.
In India, Prwatech was the first training centre for Hadoop. As you are aware, there is a severe shortage of Hadoop experts in the market nowadays. Therefore, in order to obtain high salaries when learning Hadoop, it pays to be with the industry leader like Prwatech. You will learn about the many essential Hadoop components during the session, including MapReduce, HDFS, HBase, Hive, Pig, Sqoop, Flume, and Oozie. Gaining a comprehensive understanding of the complete Hadoop framework will enable you to handle massive amounts of data in practical situations.
The most thorough course is the Prwatech training, which was created by industry professionals taking the business requirements and work environment into account. We also provide free course materials, videos, and round-the-clock support for life.
Prwatech basically offers the self-paced training and online instructor-led training. Apart from it we even provide corporate training for enterprises. All our trainers come with over 5 years of industry experience in relevant technologies and moreover they are subject matter experts working as consultants. You can check about the quality of our trainers in the sample videos provided.
Indeed, you don’t need to have any experience with software to understand Hadoop. We provide free classes in Linux and Java so you may sharpen your programming abilities. This will enable you to master Hadoop technology more quickly and effectively.
Yes, placement assistance is offered by Prwatech. We have partnerships with more than 80 companies who are seeking Hadoop specialists, such as Ericsson, Cisco, Cognizant, and TCS, among others. We would be pleased to help you with the process of getting ready for the interview and the position.
Course Tools

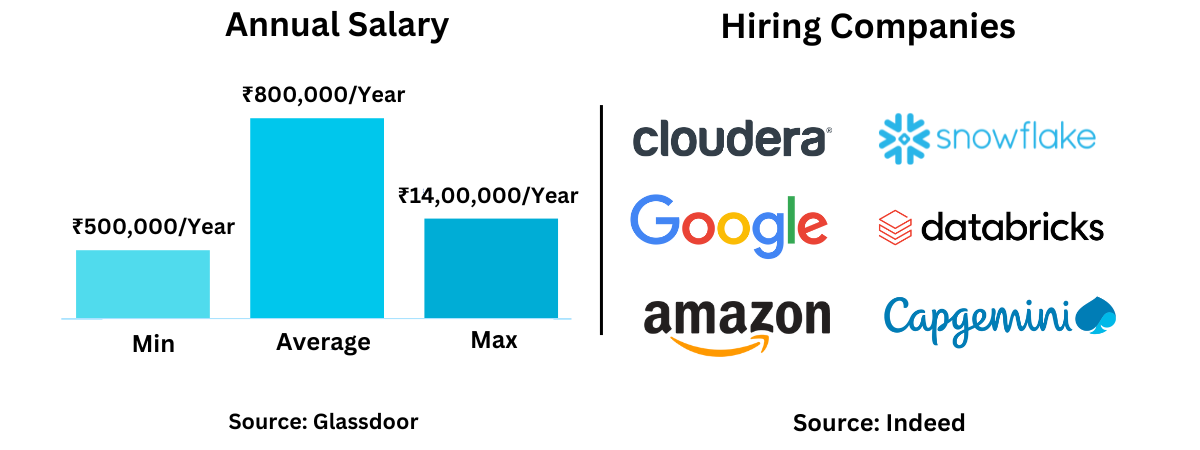
Salary
Offers

Program Features

Instructor-led Sessions

Real-life Case Studies

Assignments

Lifetime Access

24 x 7 Expert Support
Free Courses & Free MCQ




Recommended Jobs
Our Blogs
Highly specialized courses to drive your success




Corporate Training

Workplace Learning that Works
- Blended learning delivery model (self-paced eLearning and/or instructor-led options)
- Flexible pricing options
- Enterprise grade Learning Management System (LMS)
- Enterprise dashboards for individuals and teams
- 24×7 learner assistance and support
Contact Us
Our Projects
Highly specialized courses
Happy Graduates
Highly specialized courses to drive your success

Dr Vamsi Mohan
“We got a chance to learn a lot of new things in Big Data. It is a great place for exchanging ideas and sharing knowledge. Everyone in the class room was so friendly and helpful”.

Sunit sushil
“Faculty is good,Verma takes keen interest and personnel care in improvising skills in students. And most importantly,Verma will be available and clears doubts at any time apart from class hours.

Raghu Sistla
“Prwatech is one of the best institution I felt for hadoop online training. Instructor is very good, very knowledgeable, explains all the doubts and gives enough time to all the participants.

Varun Shivashanmugum
The Course covered everything that was essential for me to start project in my company. The Classes were very flexible so it allowed me to adjust my work and my classes. The course gave me an amazing insight on the HADOOP system.

Hadoop Course
Course Certification
Looking for a good big data certification course online? Prwatech provides you several certification courses at realistic prices from the comfort of your house
How it Works
Stands by you all the way to ensure that you achieve your
Your Learning Manager Gets in Touch with You
Share your learning objectives and get oriented with our web and mobile platform. Talk to your personal learning manager to clarify your doubts.
Live Interactive Online Session with Your Instructor
Live screensharing, step-by-step live demonstrations and live Q&A led by industry experts. Missed a class? Not an issue. We record the classes and upload them to your LMS.
Access our Extensive Learning Repository
We have pre-populated your learning platform with previous class recordings and presentations. You will have life time access to Learning Repository.
Solve an Industry Live Use Case
Projects developed by industry experts gives you the experience of solving real-world problems you will face in the corporate world
Get Certified and Fast Track Your Career Growth
Earn a valued certificate. Get help in creation of a professionally written CV & Guidance for interview preparation & questions
Recomended Courses

Course
10 best Hadoop articles from 2016 that you should read:
Course
Advantages and Disadvantages of Big Data
Course
Benefits of learning Hadoop – From advantages to opportunities!!!
Course
5 Reasons to Learn Apache Spark Now