Introduction to Apache Spark
Introduction to Apache Spark for Beginners
Introduction to Apache Spark for Beginners, Welcome to the world of Apache Spark Introduction tutorials. In these Tutorials, one can explore introduction to Apache Spark, history of Apache Spark, How does Apache Spark work and components of Apache Spark. Learn More advanced Tutorials on Apache Spark introduction for beginners from India’s Leading Apache Spark Training institute which Provides Advanced Apache Spark Course for those tech enthusiasts who wanted to explore the technology from scratch to advanced level like a Pro.
We Prwatech, the Pioneers of Apache Spark Training Offering Advanced Certification Course and Apache Spark Introduction to those who are keen to explore the technology under the World-class Training Environment.
Apache Spark Introduction
Apache Spark is a fast and general-purpose cluster computing system. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming.
History of Apache Spark
At first, in 2009 Apache Spark was introduced in the UC Berkeley R&D Lab, which is now known as AMPLab. Afterward, in 2010 it became open source under BSD license. Further, the spark was donated to Apache Software Foundation, in 2013. Then in 2014, it became top-level Apache project.
Why Spark?
To perform batch processing, we were using Hadoop MapReduce.
Also, to perform stream processing, we were using Apache Storm / S4.
Moreover, for interactive processing, we were using Apache Impala / Apache Tez.
To perform graph processing, we were using Neo4j / Apache Giraph.
Hence there was no powerful engine in the industry, that can process the data both in real-time and batch mode. Also, there was a requirement that one engine can respond in sub-second and perform in-memory processing.
Therefore, Apache Spark programming enters, it is a powerful open source engine. Since, it offers real-time stream processing, interactive processing, graph processing, in-memory processing as well as batch processing. Even with very fast speed, ease of use and standard interface. Basically, these features create the difference between Hadoop and Spark. Also makes a huge comparison between Spark vs Storm.
Components of Apache Spark

Spark Core
Spark Core is a central point of Spark. Basically, it provides an execution platform for all the Spark applications. Moreover, to support a wide array of applications, Spark Provides a generalized platform.
Spark SQL
On the top of Spark, Spark SQL enables users to run SQL/HQL queries. We can process structured as well as semi-structured data, by using Spark SQL. Moreover, it offers to run unmodified queries up to 100 times faster on existing deployments.
Spark Streaming
Basically, across live streaming, Spark Streaming enables a powerful interactive and data analytics application. Moreover, the live streams are converted into micro-batches those are executed on top of spark core.
Spark MLlib
Machine learning library delivers both efficiencies as well as the high-quality algorithms. Moreover, it is the hottest choice for a data scientist. Since it is capable of in-memory data processing, that improves the performance of iterative algorithm drastically.
Spark GraphX
Basically, Spark GraphX is the graph computation engine built on top of Apache Spark that enables to process graph data at scale.
SparkR
Basically, to use Apache Spark from R. It is R package that gives light-weight front end. Moreover, it allows data scientists to analyze large data sets. Also allows running jobs interactively on them from the R shell. Although, the main idea behind SparkR was to explore different techniques to integrate the usability of R with the scalability of Spark.
Apache Spark architecture overview
Apache Spark has a well-defined layered architecture where all the spark components and layers are loosely coupled. This architecture is further integrated with various extensions and libraries. Apache Spark Architecture is based on two main abstractions:
Resilient Distributed Dataset (RDD)
Directed Acyclic Graph (DAG)
How Apache Spark Works
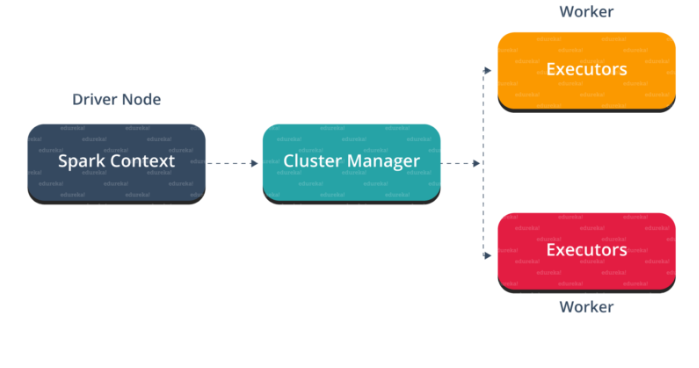
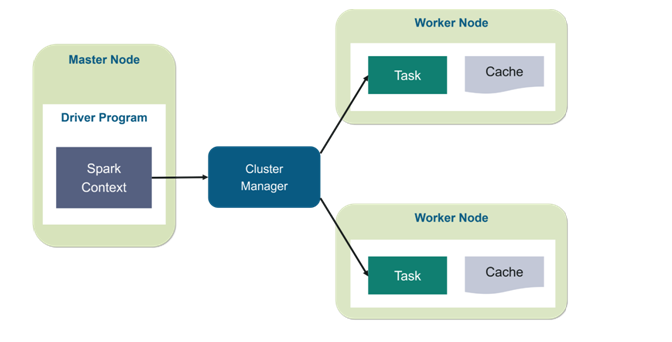
Apache Spark is an open source, general-purpose distributed computing engine used for processing and analyzing a large amount of data. Just like Hadoop MapReduce, it also works with the system to distribute data across the cluster and process the data in parallel. Spark uses master/slave architecture i.e. one central coordinator and many distributed workers. Here, the central coordinator is called the driver.
Apache Spark terminology
Apache Spark Context
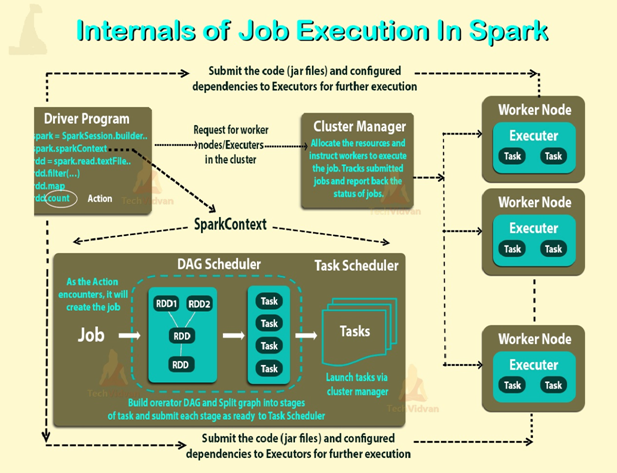
Spark Context is the heart of Spark Application. It establishes a connection to the Spark Execution environment. It is used to create spark RDD, accumulators, and broadcast variables, access Spark services and run jobs. spark Context is a client of Spark execution environment and acts as the master of Spark application. The main works of Spark Context are:
- Getting the current status of spark application
- Canceling the job
- Canceling the Stage
- Running job synchronously
- Running job asynchronously
- Accessing persistent RDD
- Unpersisting RDD
- Programmable dynamic allocation
Apache Spark Shell
Spark Shell is a Spark Application written in Scala. It offers command line environment with auto-completion. It helps us to get familiar with the features of spark, which help in developing our own Standalone Spark Application. Thus, this tool helps in exploring Spark and is also the reason why Spark is so helpful in processing data set of all size.
Spark Application
The Spark application is a self-contained computation that runs user-supplied code to compute a result. A Spark application can have processes running on its behalf even when it’s not running a job.
Task
A task is a unit of work that sends to the executor. Each stage has some task, one task per partition. The Same task is done over different partitions of RDD.
Job
The job is parallel computation consisting of multiple tasks that get spawned in response to actions in Apache Spark.
Stage
Each job divides into smaller sets of tasks called stages that depend on each other. Stages are classified as computational boundaries. All computation cannot be done in a single stage. It achieves over many stages.
Components of Spark Runtime Architecture
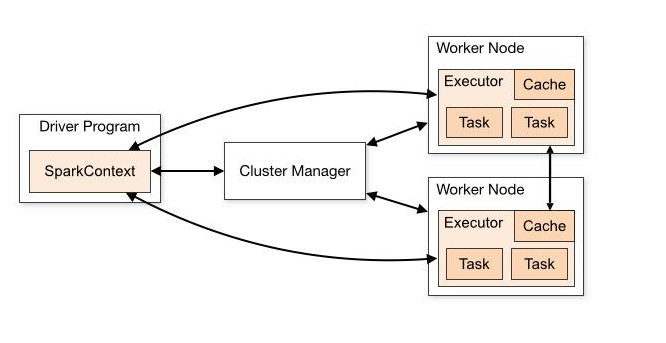
Apache Spark Driver
The main() method of the program runs in the driver. The driver is the process that runs the user code that creates RDDs, and performs transformation and action, and also creates Spark Context. When the Spark Shell is launched, this signifies that we have created a driver program. On the termination of the driver, the application is finished.
The driver program splits the Spark application into the task and schedules them to run on the executor. The task scheduler resides in the driver and distributes task among workers. The two main key roles of drivers are:
- Converting user program into the task.
- Scheduling task on the executor.
The structure of Spark program at a higher level is: RDDs consist of some input data, derive new RDD from existing using various transformations, and then after it performs an action to compute data. In Spark Program, the DAG (directed acyclic graph) of operations create implicitly. And when the driver runs, it converts that Spark DAG into a physical execution plan.
Apache Spark Cluster Manager
Spark relies on cluster manager to launch executors and in some cases, even the drivers launch through it. It is a plug gable component in Spark. On the cluster manager, jobs and action within a spark application scheduled by Spark Scheduler in a FIFO fashion. Alternatively, the scheduling can also be done in Round Robin fashion. The resources used by a Spark application can dynamically adjust based on the workload. Thus, the application can free unused resources and request them again when there is a demand. This is available on all coarse-grained cluster managers, i.e. standalone mode, YARN mode, and Mesos coarse-grained mode.
Apache Spark Executors
The individual task in the given Spark job runs in the Spark executors. Executors launch once in the beginning of Spark Application and then they run for the entire lifetime of an application. Even if the Spark executor fails, the Spark application can continue with ease. There are two main roles of the executors:
- Runs the task that makes up the application and returns the result to the driver.
- Provide in-memory storage for RDDs that are cached by the user.
Resilient Distributed Dataset(RDD):
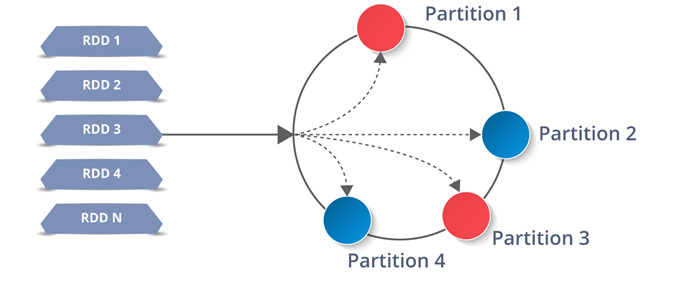
RDDs are the building blocks of any Spark application. RDDs Stands for:
- Resilient: Fault tolerant and is capable of rebuilding data on failure
- Distributed: Distributed data among the multiple nodes in a cluster
- Dataset: Collection of partitioned data with values
RDD Persistence :
One of the most important capabilities in Spark is persisting (or caching) a data set in memory across operations. When you persist an RDD, each node stores any partitions of it that it computes in memory and reuses them in other actions on that data set (or data sets derived from it). This allows future actions to be much faster (often by more than 10x). Caching is a key tool for iterative algorithms and fast interactive use.
You can mark an RDD to be persisted using the persist() or cache() methods on it. The first time it is computed in an action, it will be kept in memory on the nodes. Spark’s cache is fault-tolerant – if any partition of an RDD is lost, it will automatically be recomputed using the transformations that originally created it.
In addition, each persisted RDD can be stored using a different storage level, allowing you, for example, to persist the data set on disk, persist it in memory but as serialized Java objects (to save space), replicate it across nodes. These levels are set by passing a Storage Level object (Scala,Java, Python) to persist(). The cache() method is a shorthand for using the default storage level, which is StorageLevel.MEMORY_ONLY (store deserialized objects in memory).
The full set of storage levels is:
| Storage Level | Meaning |
| MEMORY_ONLY | Store RDD as deserialized Java objects in the JVM. If the RDD does not fit in memory, some partitions will not be cached and will be recomputed on the fly each time they’re needed. This is the default level. |
| MEMORY_AND_DISK | Store RDD as deserialized Java objects in the JVM. If the RDD does not fit in memory, store the partitions that don’t fit on disk, and read them from there when they’re needed. |
| MEMORY_ONLY_SER (Java and Scala) |
Store RDD as serialized Java objects (one byte array per partition). This is generally more space-efficient than deserialized objects, especially when using a fast serializer, but more CPU-intensive to read. |
| MEMORY_AND_DISK_SER (Java and Scala) |
Similar to MEMORY_ONLY_SER, but spill partitions that don’t fit in memory to disk instead of recomputing them on the fly each time they’re needed. |
| DISK_ONLY | Store the RDD partitions only on disk. |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2, etc. | Same as the levels above, but replicate each partition on two cluster nodes. |
| OFF_HEAP (experimental) | Similar to MEMORY_ONLY_SER, but store the data in off-heap memory. This requires off-heap memory to be enabled. |
Performance Tuning on Spark
To understand Spark, you need to know about Transformation, Action, RDD, DStream etc.
To write better/fast Spark program, you need to understand Job, Stage, task etc.
How to deploy yarn on spark
| MASTER URL | MEANING | ||
| Run Spark locally with one worker thread (i.e. no | |||
| local | |||
| parallelism at all). | |||
| Run Spark locally with K worker threads (ideally, set | |||
| local[K] | |||
| this to the number of cores on your machine). | |||
Different mode to deploy yarn on spark
| Yarn cluster | Yarn client | Spark standalone | |
| Driver run in | Application master | Client | Client |
| Who requires resources | AM | AM | Client |
| Who started executor process | Yarn NM | Yarn NM | Spark slave |
| Persistent service | Yarn RM & NM | Yarn RM &NM | Spark masters & workers |
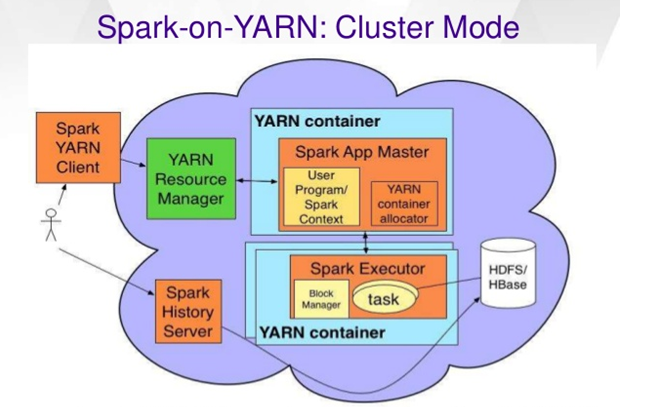
Yarn-cluster mode