Submitting Spark Jobs to Your Dataproc Clusters
Working with Dataproc in the Google Cloud Console provides users with a user-friendly interface to manage, configure, and monitor their managed Apache Hadoop and Apache Spark clusters. Dataproc simplifies big data processing by automating cluster management tasks, allowing users to focus on analyzing and deriving insights from their data.
Within the Google Cloud Console, users can create, configure, and delete Dataproc clusters with just a few clicks. The console provides intuitive wizards to guide users through the cluster creation process, allowing them to specify parameters such as the cluster name, machine type, number of worker nodes, and software components (such as Hadoop, Spark, or Hive) to be installed on the cluster.
Prerequisites
GCP account
Open Notepad/Text editor in your machine.
Paste the below code.
from pyspark import SparkConf, SparkContext
import collections
conf = SparkConf().setMaster(“local”).setAppName(“Ratings”)
sc = SparkContext(conf = conf)
lines = sc.textFile(“/user/<userid>/sparkdata/u.data”)
ratings = lines.map(lambda x: x.split( )[2])
result = ratings.countByValue()
sortedResults = collections.OrderedDict(sorted(result.items()))
for key, value in sortedResults.items():
print(“%s %i” % (key, value))
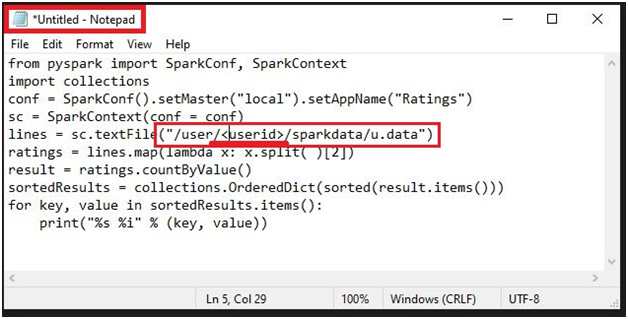
Give your user ID of console.
To get your user ID, Open cloud shell.
$ pwd #It will show path with your user ID

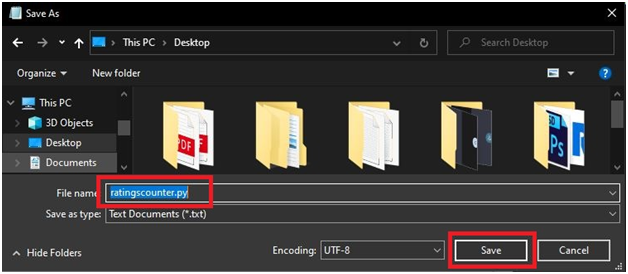
Save file as ratingscounter.py
Open Cloud Console
Open Cloud Storage > Browser
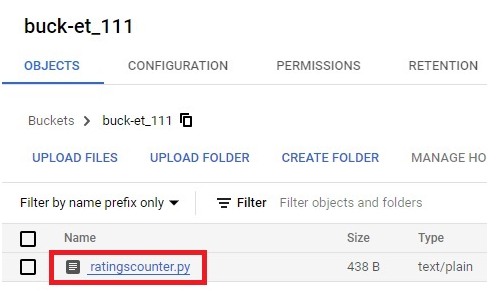
Upload the created file into bucket.
Click on the file.
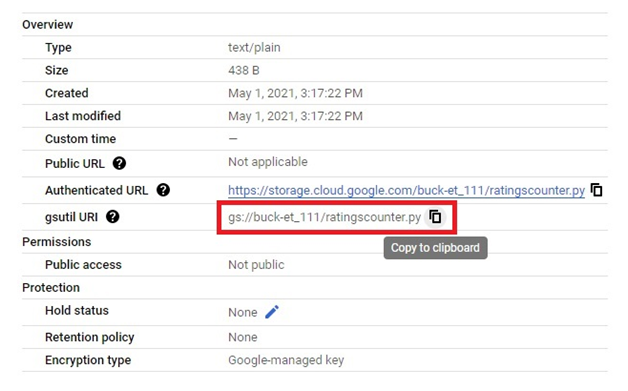
Copy the URI of file.
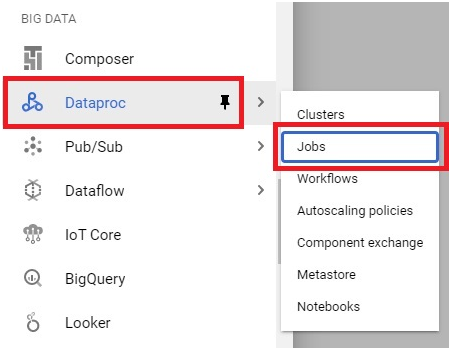
Open Menu > Dataproc > Jobs
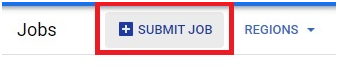
Click on Submit Job
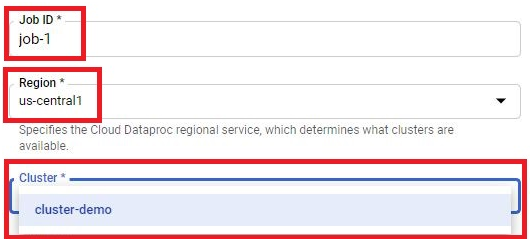
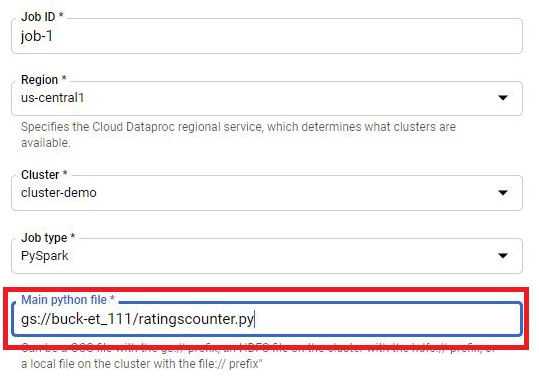
Give the Job ID.
Region will be automatically selected.
Choose the cluster.
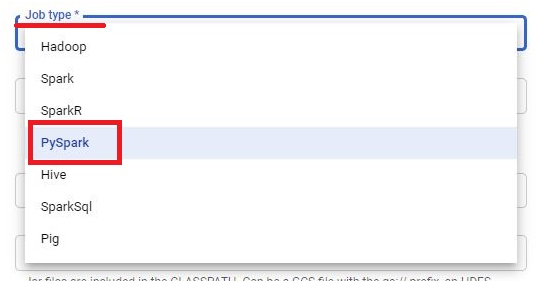
Choose the job type as PySpark
Paste the URI of python file.
Click Submit.
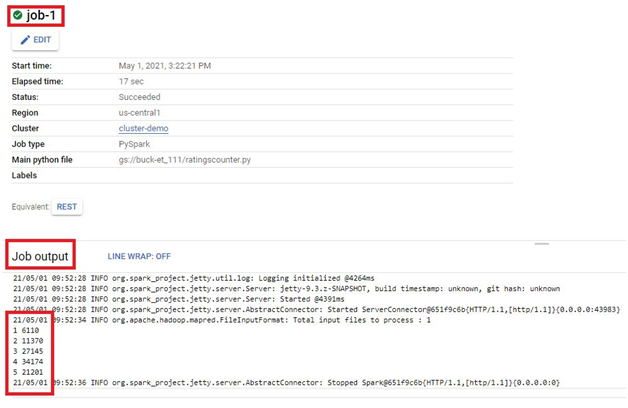
It will execute the job and give the result.
Submitting Spark Jobs to Your Dataproc Clusters

