Hadoop flume tutorial
Hadoop flume tutorial
Hadoop flume tutorial, Welcome to the world of Hadoop flume Tutorials. In these Tutorials, one can explore how to fetch Flume Data from Twitter. Learn More advanced Tutorials on flume configuration in Hadoop from India’s Leading Hadoop Training institute which Provides Advanced Hadoop Course for those tech enthusiasts who wanted to explore the technology from scratch to advanced level like a Pro.
We Prwatech, the Pioneers of Hadoop Training Offering advanced Certification course and Hadoop flume setup to those who are keen to explore the technology under the World-class Training Environment.
Fetching Flume Data from Twitter
- Ubuntu v12 (or above)
- Apache flume 1.3.1 bin.tar
- Flume source 1.0. SNAPSHOT
Twitter data analysis using flume
Make a new directory in /usr/lib for flume
$cd /usr/lib/

$mkdir myflume

moving the apache-flume 1.3.1 bin.tar to /usr/lib/myflume
$sudo mv /home/cloudera/Desktop/apache flume 1.3.1 bin.tar /usr/lib/myflume
Untar the file.
$sudo tar -zxvf apache flume 1.3.1 bin.tar
Now we will have two files in /usr/lib/myflume
apache flume 1.3.1 bin.tar.gz
apache flume 1.3.1 bin

This apache “flume 1.3.1 bin” will have many directories one among them will be lib . move the “flume-source -1.0.SNAPSHOT.jar to this lib. $ sudo mv /home/cloudera/Desktop/flume source 1.0. SNAPSHOT

/usr/lib/myflume/apache-flume 1.3.1 bin /lib/

Go to the conf directory
$ cd ../conf/

Create a copy of flume-env.sh.template as flume-env.sh in the same /conf/ dir. as :
$ cp /usr/lib/myflume/apache flume 1.3.1 bin /conf/flume-env.sh.template/usr/lib/myflume/apache flume 1.3.1 bin /conf/flume-env.sh

Hence it will contain :
flume-env.sh.template
2 flume-env.sh
![]()
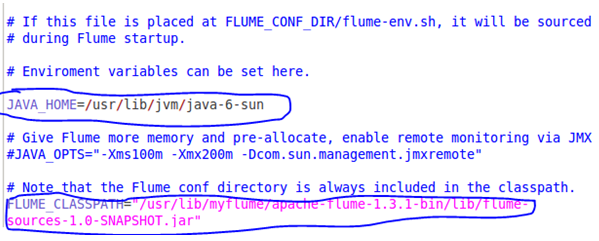
configuring the flume-env.sh as
$ sudo gedit flume-env.sh
![]()
JAVA_HOME=/usr/lib/jvm/java-6-sun
FLUME_CLASSPATH=”/usr/lib/myflume/apache flume 1.3.1 bin/lib/flume-source -1.0.SNAPSHOT.jar”
CREATING API CREDENTIALS:
app twitter –> twitter application management :
sign in : username:
password :
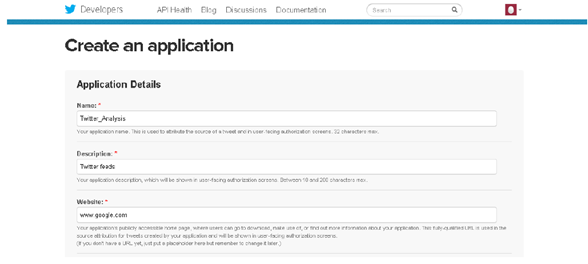
CREATE NEW API :
Application Details:
* Name:
* Description:
* Website :
* Callback URL: not require
*Finally click on “yes I agree”
KEY AND ACCESS TOKENS :
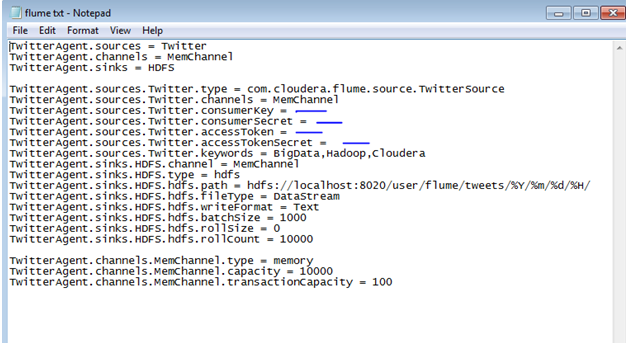
#NOTE: Get the following information and fill it in the flume.txt file.
- ConsemerKey
- ConsumerSecret:
- AccessTokens:
- AccessTokenSecret:
Now move the flume.txt file to the Cloudera
create a new file in the /conf/ directory.
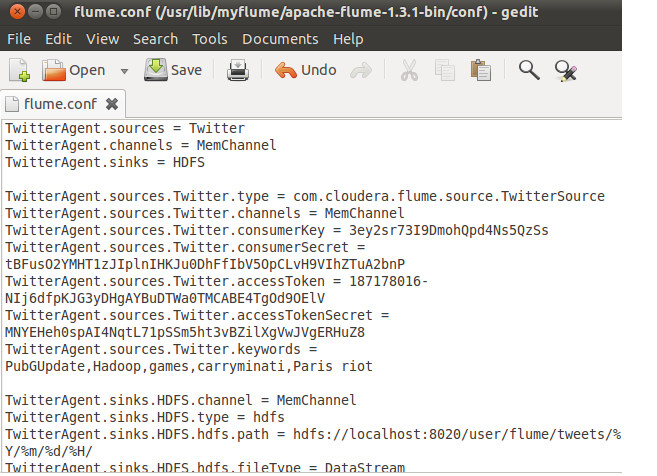
$ cd /usr/lib/myflume/apache flume 1.3.1 bin/conf/
$sudo gedit flume.conf
![]()
copy the content of the flume.txt in this file and save it
Go to the bin directory and fire the final command:
- $cd /usr/lib/myflume/apache flume 1.3.1 bin/bin/
- $./flume-ng agent -n TwitterAgent -c conf -f /usr/lib/myflume/apache /conf/flume.conf
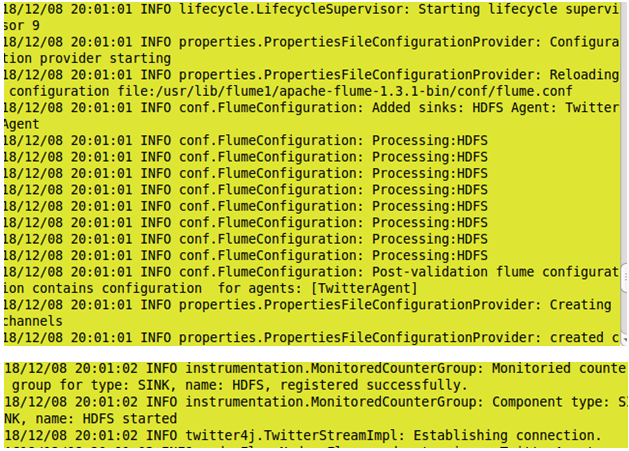
Now we use our virtual machine web browser to see our records collected by user from Twitter.
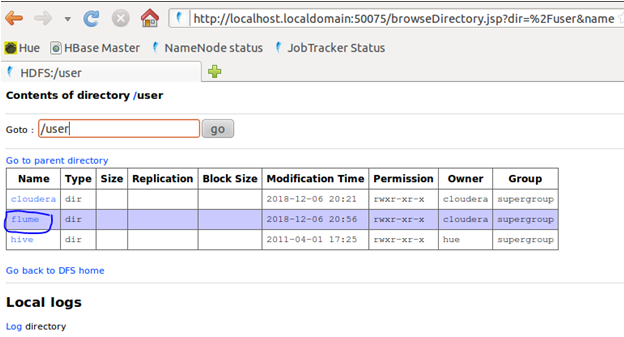

Goto NameNode Status > user > flume > tweets
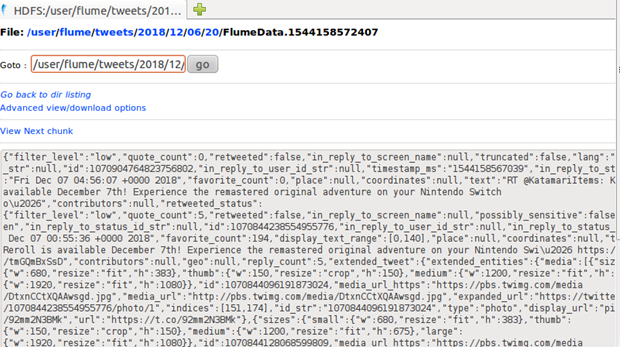
As you can see all the data collected from twitter is in json format which is needed to be converted in csv so that user can understand the data collected.
For this we can use online json to csv converter to convert the following data.






