Hadoop-Map_Side Join in Hive

♦ Create two tables

♦ Copy the file or document in HDFS for both the tables:
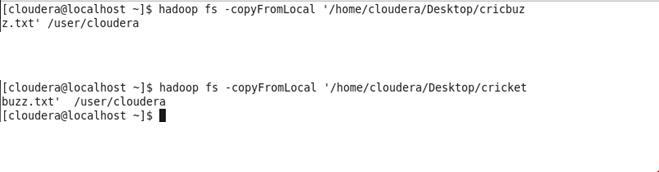
♦ Load the data of the files into the tables:
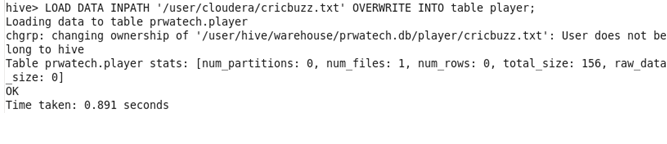
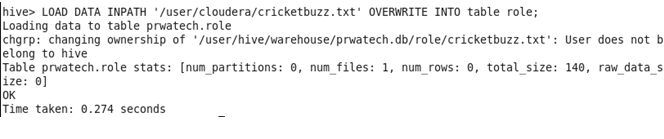
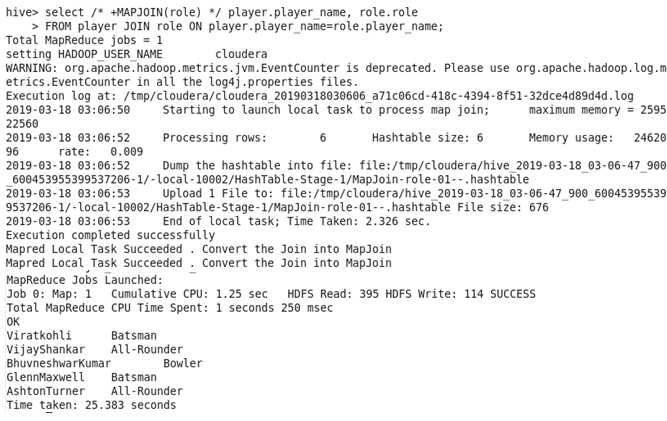
♦ Run the join task by Map-Side Join
♦ Join by Reduce-side :

♦ As we can see, the time taken in map-side join is less than that in reduce-side.
Hence, Map-Side Join is more efficient when one of the table is small enough to fit in the memory.
0
0






