Cloud Pub/Sub and Dataflow for Stream Processing
Prerequisites
GCP account
Open console.
Open Console. Click on Activate cloud shell
NB: If any permission error arises, give owner permission for the default service account
Create variables for your bucket, project, pubsub topic and region. Select a Dataflow region close to where you run the commands
BUCKET_NAME=your-bucket-name
PROJECT_ID=(gcloud config get-value project)
TOPIC_ID=your-topic-id
REGION=dataflow-region

Create a Cloud Scheduler job in this project.
$ gcloud scheduler jobs create pubsub publisher-job \
--schedule="* * * * *" \
--topic=$TOPIC_ID --message-body="Hello!"
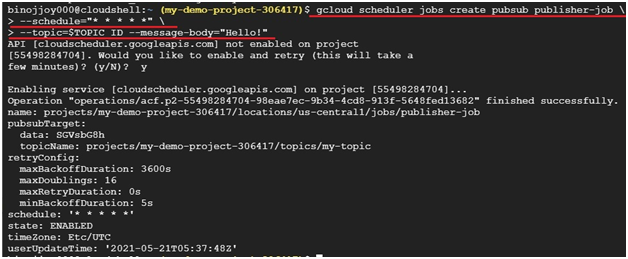
Start the job.
gcloud scheduler jobs run publisher-job

Use the following commands to clone the quickstart repository and navigate to the sample code directory:
git clone https://github.com/GoogleCloudPlatform/python-docs-samples.git

cd python-docs-samples/pubsub/streaming-analytics

pip3 install -r requirements.txt

NB : If error arises as apache beam version is not available, open requirements.txt file (nano requirements.txt) and change version to 2.24.0
Open File
$ nano PubSubToGCS.py
paste the below code

# Copyright 2019 Google LLC.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
# limitations under the License.
# [START pubsub_to_gcs]
import argparse
from datetime import datetime
import logging
import random
from apache_beam import DoFn, GroupByKey, io, ParDo, Pipeline, PTransform, WindowInto, WithKeys
#from apache_beam.options.pipeline_options import PipelineOptions
from apache_beam.transforms.window import FixedWindows
class GroupMessagesByFixedWindows(PTransform):
"""A composite transform that groups Pub/Sub messages based on publish time
and outputs a list of tuples, each containing a message and its publish time.
"""
def __init__(self, window_size, num_shards=5):
# Set window size to 60 seconds.
self.window_size = int(window_size * 60)
self.num_shards = num_shards
def expand(self, pcoll):
return (
pcoll
Bind window info to each element using element timestamp (or publish time).
| "Window into fixed intervals"
>> WindowInto(FixedWindows(self.window_size))
| "Add timestamp to windowed elements" >> ParDo(AddTimestamp())
Assign a random key to each windowed element based on the number of shards.
| "Add key" >> WithKeys(lambda _: random.randint(0, self.num_shards - 1))
Group windowed elements by key. All the elements in the same window must fit
memory for this. If not, you need to use `beam.util.BatchElements`.
| "Group by key" >> GroupByKey()
)
class AddTimestamp(DoFn):
def process(self, element, publish_time=DoFn.TimestampParam):
"""Processes each windowed element by extracting the message body and its
publish time into a tuple.
"""
yield (
element.decode("utf-8"),
datetime.utcfromtimestamp(float(publish_time)).strftime(
"%Y-%m-%d %H:%M:%S.%f"
),
)
class WriteToGCS(DoFn):
def __init__(self, output_path):
self.output_path = output_path
def process(self, key_value, window=DoFn.WindowParam):
"""Write messages in a batch to Google Cloud Storage."""
ts_format = "%H:%M"
window_start = window.start.to_utc_datetime().strftime(ts_format)
window_end = window.end.to_utc_datetime().strftime(ts_format)
shard_id, batch = key_value
filename = "-".join([self.output_path, window_start, window_end, str(shard_id)])
with io.gcsio.GcsIO().open(filename=filename, mode="w") as f:
for message_body, publish_time in batch:
f.write(f"{message_body},{publish_time}".encode("utf-8"))
def run(input_topic, output_path, window_size=1.0, num_shards=5, pipeline_args=None):
Set `save_main_session` to True so DoFns can access globally imported modules.
pipeline_options = PipelineOptions(
pipeline_args, streaming=True, save_main_session=True
)
with Pipeline(options=pipeline_options) as pipeline:
(
pipeline
Because `timestamp_attribute` is unspecified in `ReadFromPubSub`, Beam
binds the publish time returned by the Pub/Sub server for each message
to the element's timestamp parameter, accessible via `DoFn.TimestampParam`.
https://beam.apache.org/releases/pydoc/current/apache_beam.io.gcp.pubsub.html
apache_beam.io.gcp.pubsub.ReadFromPubSub
"Read from Pub/Sub" >> io.ReadFromPubSub(topic=input_topic)
"Window into" >> GroupMessagesByFixedWindows(window_size, num_shards)
"Write to GCS" >> ParDo(WriteToGCS(output_path))
)
if __name__ == "__main__":
logging.getLogger().setLevel(logging.INFO)
parser = argparse.ArgumentParser()
parser.add_argument(
"--input_topic",
help="The Cloud Pub/Sub topic to read from."
'"projects/<PROJECT_ID>/topics/<TOPIC_ID>".',
)
parser.add_argument(
"--window_size",
type=float,
default=1.0,
help="Output file's window size in minutes.",
)
parser.add_argument(
"--output_path",
help="Path of the output GCS file including the prefix.",
)
parser.add_argument(
"--num_shards",
type=int,
default=5,
help="Number of shards to use when writing windowed elements to GCS.",
)
known_args, pipeline_args = parser.parse_known_args()
run(
known_args.input_topic,
known_args.output_path,
known_args.window_size,
known_args.num_shards,
pipeline_args,
)
# [END pubsub_to_gcs]
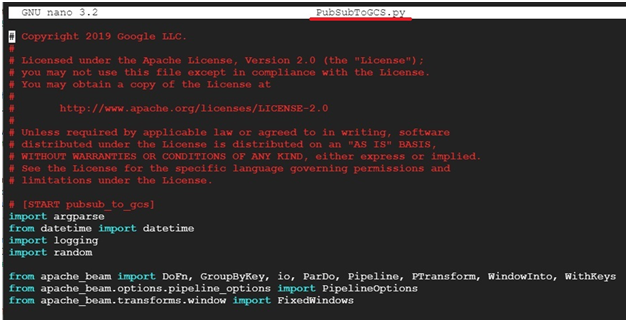
To save and exit press Ctrl+ x then press Y to confirm then press Enter.
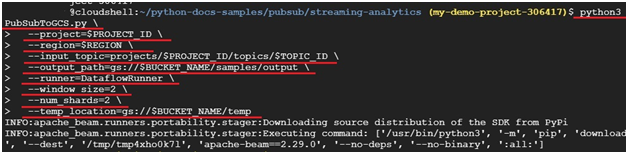
Paste the below code in shell.
$ python3 PubSubToGCS.py \
--project=$PROJECT_ID \
--region=$REGION \
--input_topic=projects/$PROJECT_ID/topics/$TOPIC_ID \
--output_path=gs://$BUCKET_NAME/samples/output \
--runner=DataflowRunner \
--window_size=2 \
--num_shards=2 \
--temp_location=gs://$BUCKET_NAME/temp
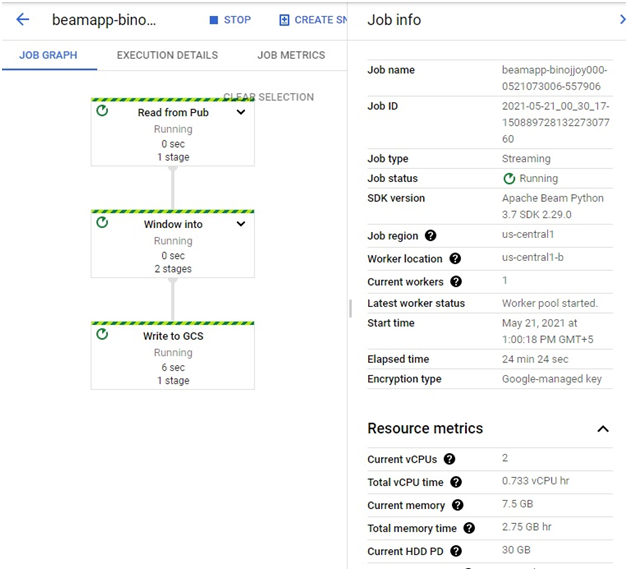
In console, Open Menu > Dataflow.
You can see the Job progress in Dataflow Console
Wait little bit time and check the bucket. It will have samples folder and inside that the output will be created. Or
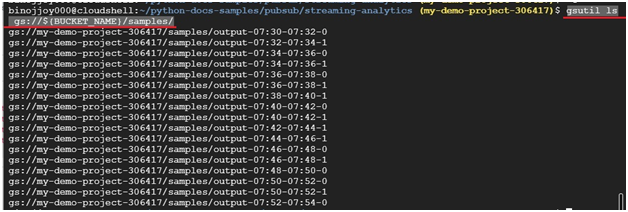
$ gsutil ls gs://${BUCKET_NAME}/samples/
It will display the output created
Delete the Cloud Scheduler job.
$ gcloud scheduler jobs delete publisher-job


