Cloud Data Fusion and BigQuery for data integration
Prerequisites
GCP account
Open Console.
Click on Activate cloud shell
$ echo $GOOGLE_CLOUD_PROJECT #Display the Project ID
$ gsutil cp gs://cloud-training/OCBL017/ny-taxi-2018-sample.csv gs://$GOOGLE_CLOUD_PROJECT
#Copying file from cloud training public bucket into our bucket
$ gsutil mb gs://$GOOGLE_CLOUD_PROJECT-temp #Creating bucket

Open Menu > Cloud Storage > Browser
The temporary bucket is created and the file is copied in main bucket.
Open Menu > Data Fusion
Click on View Instance. It will open the Data Fusion page.
Click No thanks.
Click on Wrangler
In Default Cloud Storage > Open the bucket which we copied the file.
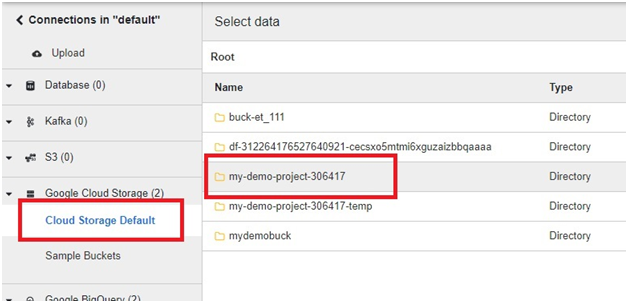
Select the copied file.
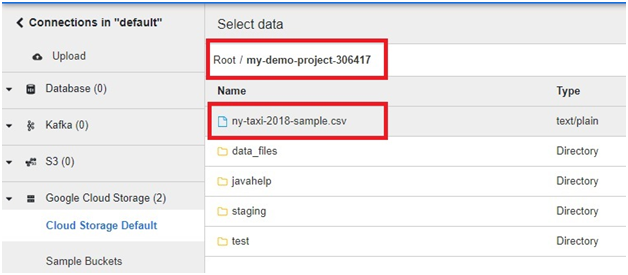
Click on drop down arrow.
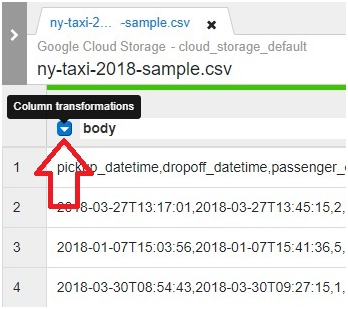
Click Parse > CSV
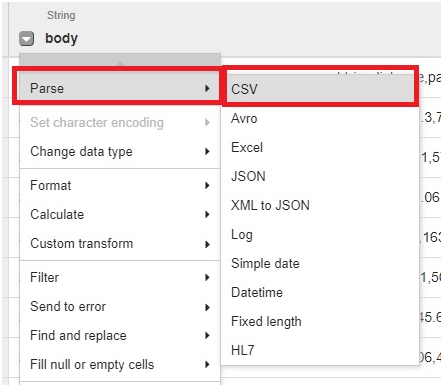
Select comma and tick set first row as header.
Click Apply
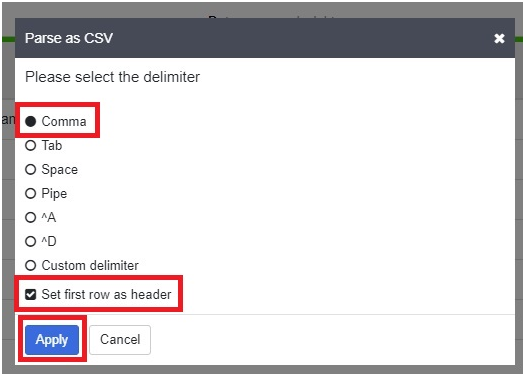
In drop down of body column, Click delete column
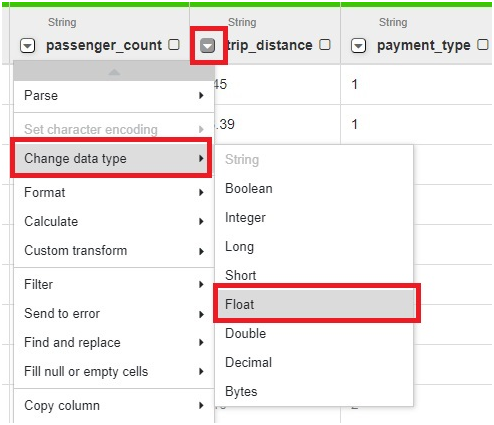
In Trip distance drop down > change data type to Float
open Filter > Custom condition
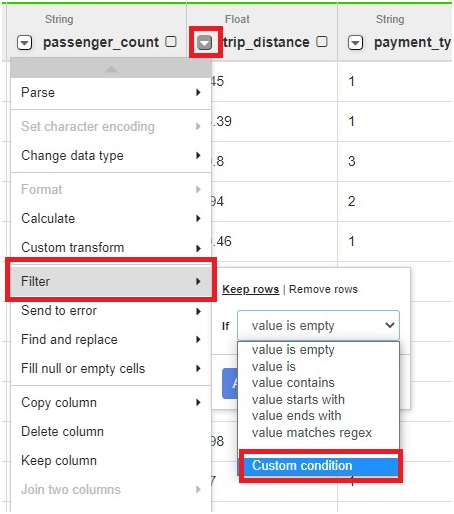
Give Condition as >0.0
Click Apply
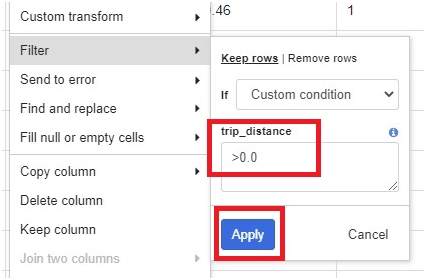
In right side of table, we can see the transformations which we did in our table
Then Click on Create a pipeline
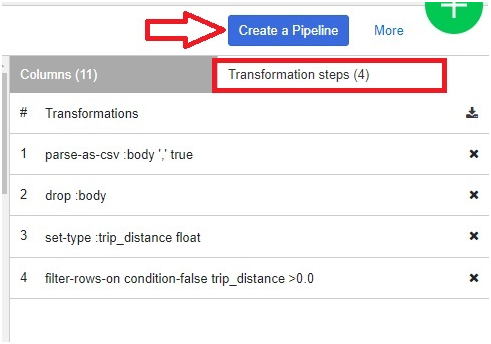
Click on Batch Pipeline.

It will create a Pipeline.
properties in Wrangler
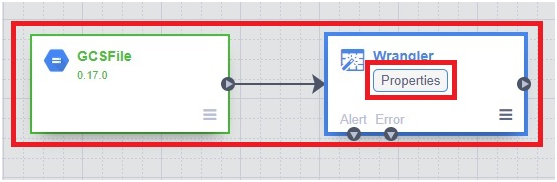
The modifications done in table will be already mentioned in here
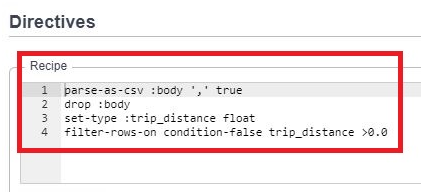
In right side, output schema is visible. In that delete column named extra.
Validate.
Click on close if no errors found.
Open Console > BigQuery
Click Create dataset.

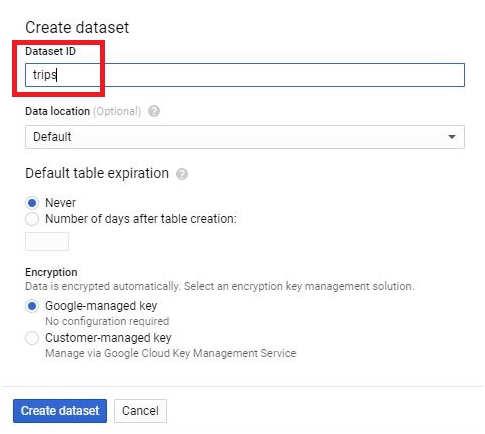
Give dataset name. Click Create Dataset.
Click on More > Query Settings
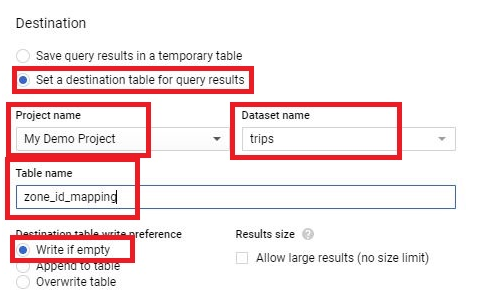
Select Set destination table for query results.
Give Project name,Dataset name, and table name.
Select Write if empty or Overwrite table and press save.
Click save
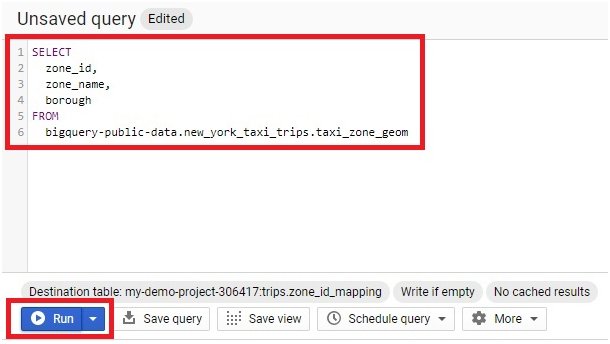
In Query Editor, Paste the below code
SELECT
zone_id,
zone_name,
borough
FROM
bigquery-public-data.new_york_taxi_trips.taxi_zone_geom
Click Run
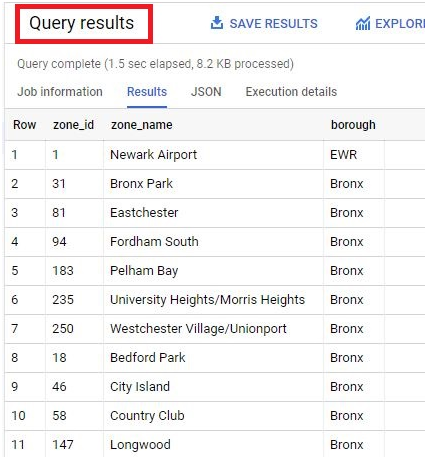
The output will be saved in the created table.
Go back to Data Fusion
Source > BigQuery
Properties in BigQuery.
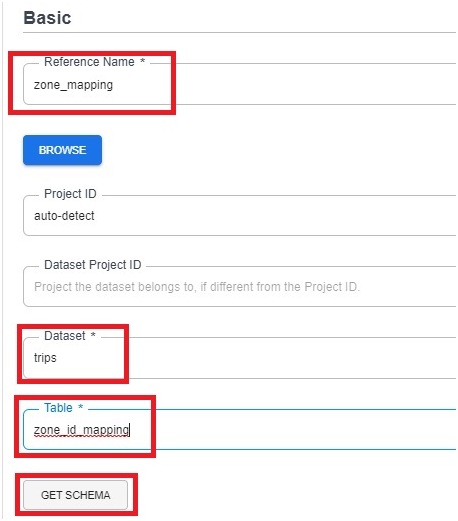
Reference name.
Give the dataset name and table name which we created.
Click Get schema
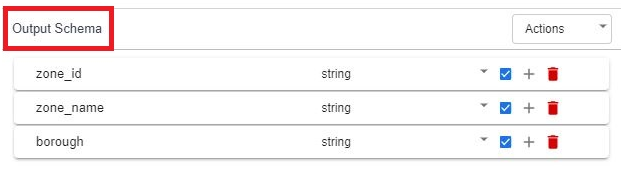
The Output Schema will be displayed in Right side.
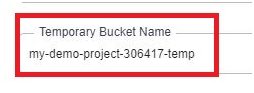
Temporary bucket name.
Click on Validate.
if no errors found.
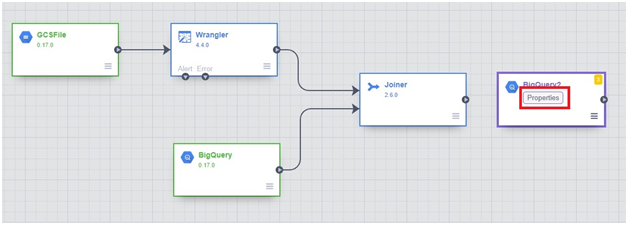
Click Analytics > Joiner
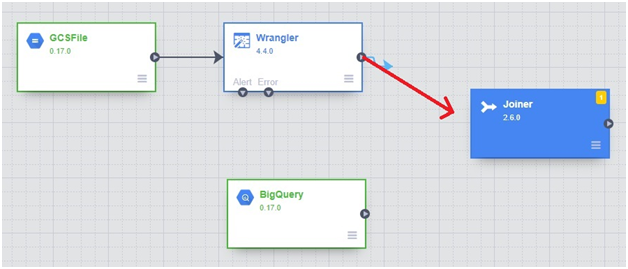
Drag the arrow into joiner from both BigQuery and Wrangler.
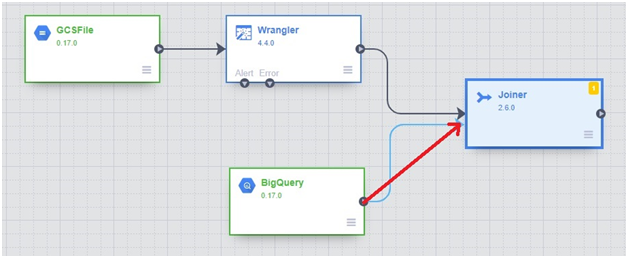
Click on properties in joiner
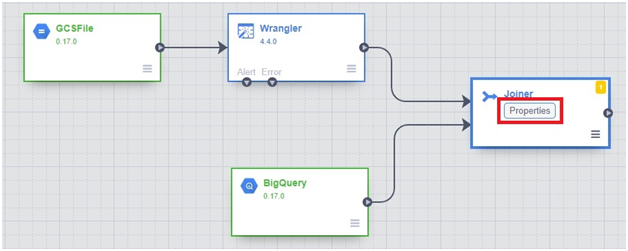
Jointype : inner
Join condition
Wrangler : pickup_location_id
BigQuery : zone_id
Click on Get Schema.
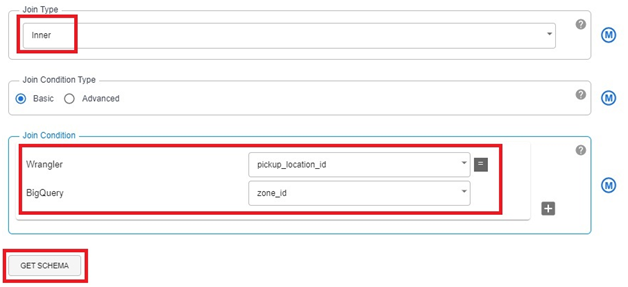
In output schema remove pickup_location_id & zone_id
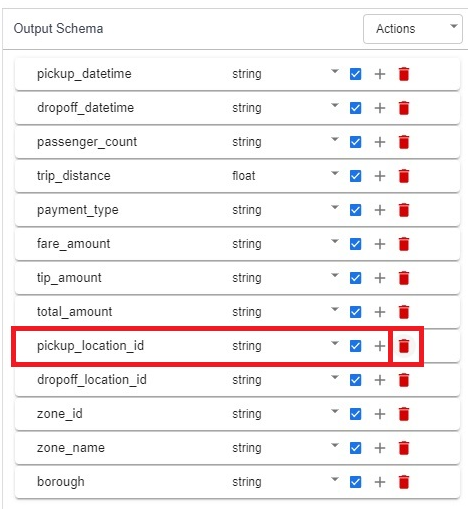
remove zone_id.
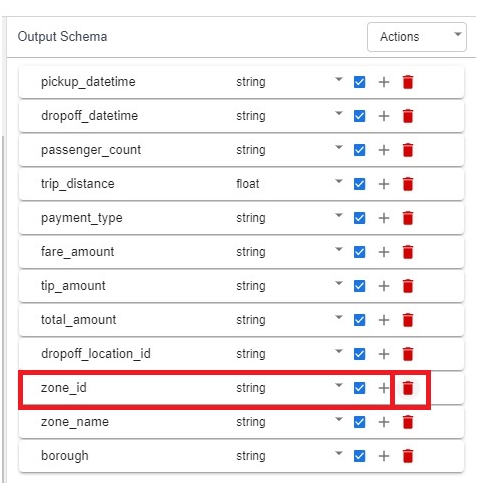
Validate.
close if no errors found.
Sink > bigQuery
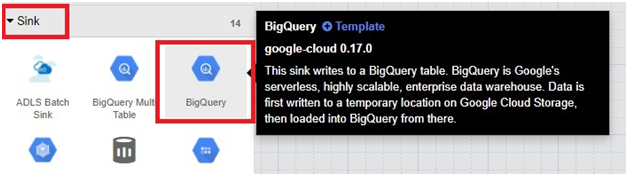
properties in second big query.
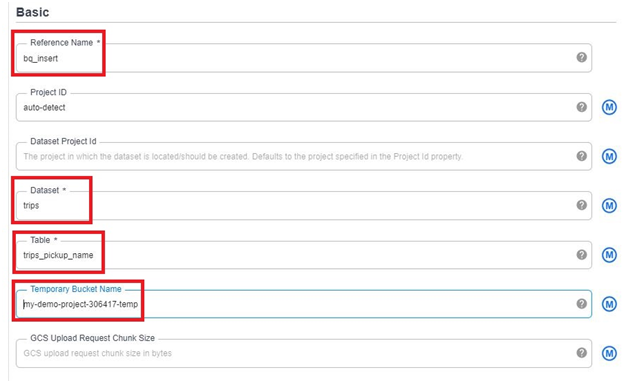
Give Reference name, dataset, table name.
Give the temporary bucket name which we created.
Click on Validate.
close if no errors found
Now drag the arrow from Joiner
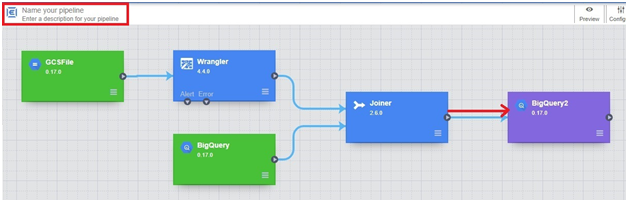
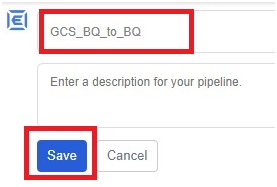
rename the pipeline. Click save
Save.
Deploy
It will deploy pipeline
Click run.
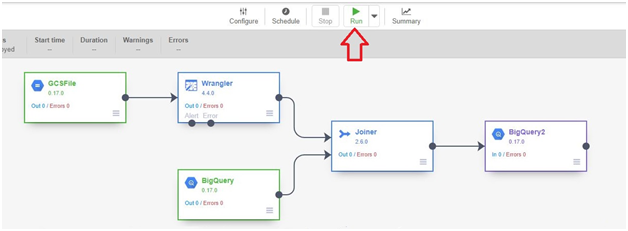
It will Start Execution. This execution will take arround 10-15 minutes.
Execution is Provisioning
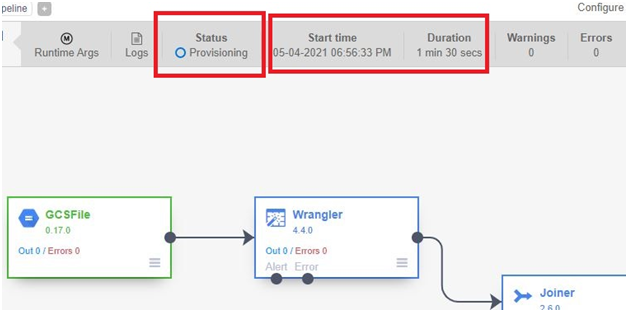
Starting

Running

Finished Successfully.
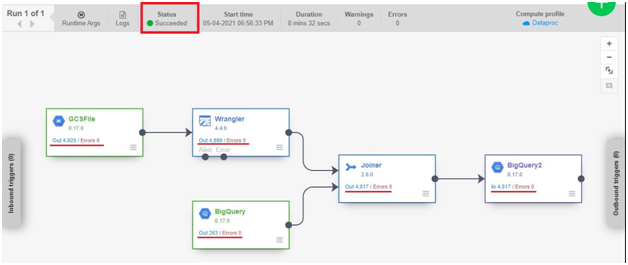
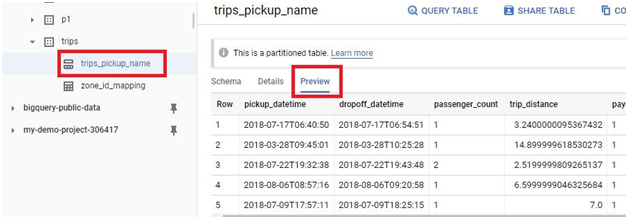
Go to BigQuery. In the dataset, new table will be created.
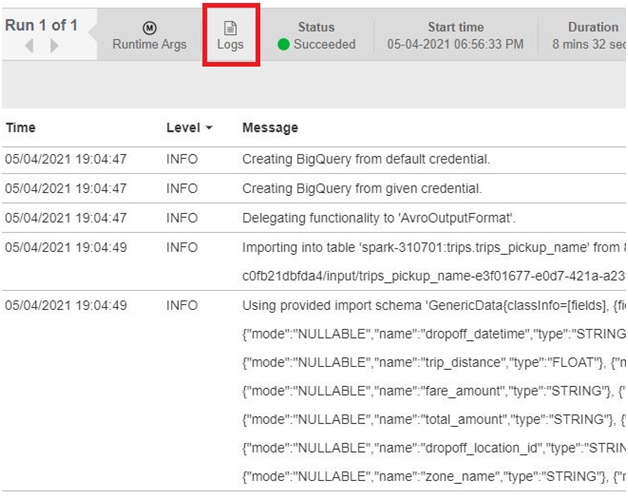
In the data Fusion, Click Logs.You can see the logs of Execution.
Cloud Data Fusion and BigQuery for data integration

