ETL Processing on Google Cloud Using Dataflow and Big Query
Dataflow and BigQuery for ETL on Google Cloud
Prerequisites
Hardware : GCP
Google account
Open the console.
Click on activate cloud shell.
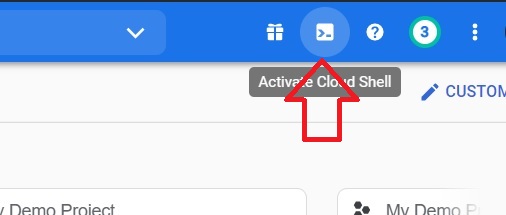
$ gcloud config list project #To List Projects
$ gcloud config set project my-demo-project-306417 #To Select Project
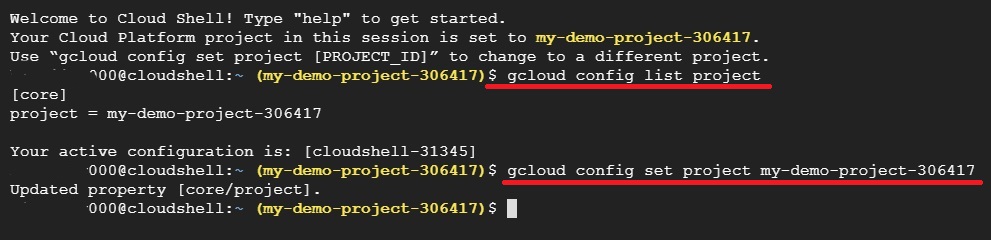
In the Cloud console, click Menu > IAM & Admin.
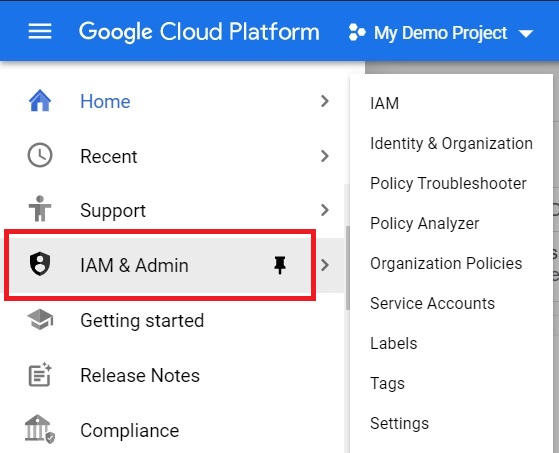
Confirm that the default compute Service Account is present and has the editor role assigned.
{project-number}-compute@developer.gserviceaccount.com
To check the project number, Go to Menu > Home > Dashboard
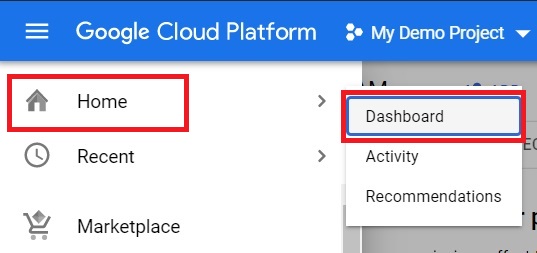
In the dashboard under the project info project number will be displayed.
In the console, copy the below code.
$ gsutil -m cp -R gs://spls/gsp290/dataflow-python-examples . # To copy the Dataflow Python Examples from Google Cloud’s professional services in GitHub

Export the name of your cloud project as an environment variable.
$ export PROJECT=<YOUR-PROJECT-ID>
Select the project which has been exported. [Don’t change $PROJECT]
gcloud config set project $PROJECT

gsutil mb -c regional -l us-central1 gs://$PROJECT #To create new Bucket

gsutil cp gs://spls/gsp290/data_files/usa_names.csv gs://$PROJECT/data_files/ #To copy the files into the bucket which we created

bq mk lake #To make Big Query Lake

Go to the directory
cd dataflow-python-examples/
Install Virtual Environment
sudo pip install virtualenv
virtualenv -p python3 venv #Creating Virtual Environement

source venv/bin/activate #Activating Virtual Environment
pip install apache-beam[gcp]==2.24.0 #Installing Apache-beam

In the Cloud Shell window, Click on Open Editor

In the Workspace, the dataflow-python-examples folder will be copied. Go through each python programs and try to understand the code.
Here we’ll run the Dataflow pipeline in cloud. It will add the workers required, and shut them down when complete
python dataflow_python_examples/data_ingestion.py –project=$PROJECT –region=us-central1 –runner=DataflowRunner –staging_location=gs://$PROJECT/test –temp_location gs://$PROJECT/test –input gs://$PROJECT/data_files/usa_names.csv –save_main_session
It will take some time to assign the workers and to finish the job assigned.

Open the console and click Menu > Dataflow > Jobs
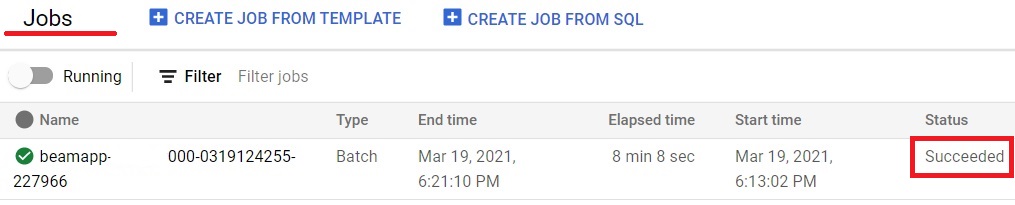
In Jobs, Check the status. It will show Succeeded after completion. It will show running if the work is not fully assigned.
Big Query > SQL Workspace
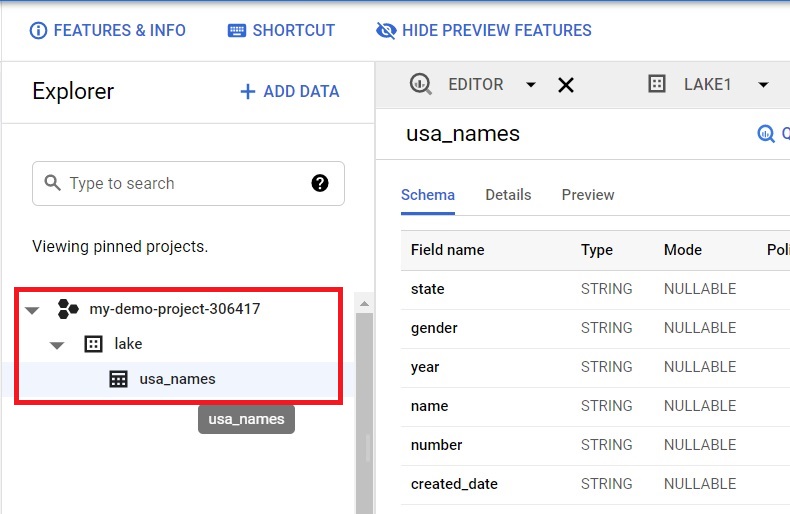
It will show the usa_names table under the lake dataset.
Here we’ll run the Dataflow pipeline saved in data_transformation.py file. It will add the workers which is required, and shut it down when complete.
python dataflow_python_examples/data_transformation.py –project=$PROJECT –region=us-central1 –runner=DataflowRunner –staging_location=gs://$PROJECT/test –temp_location gs://$PROJECT/test –input gs://$PROJECT/data_files/head_usa_names.csv –save_main_session

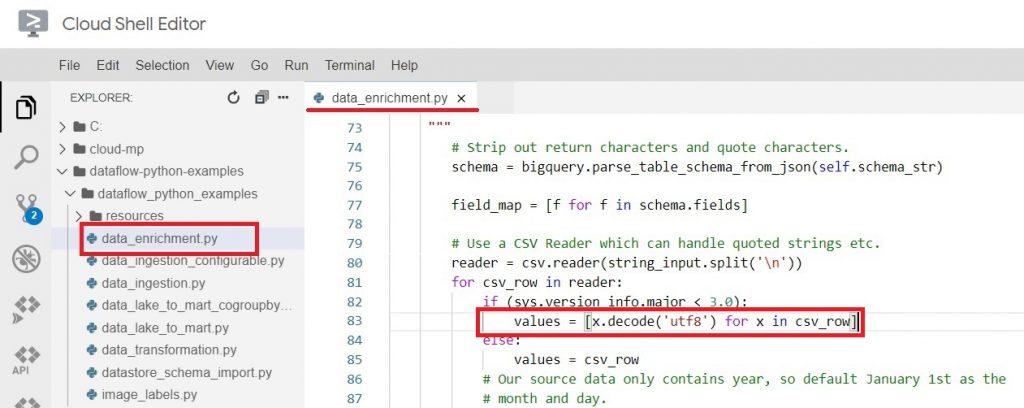
Cloud Shell Editor, open dataflow-python-examples > dataflow_python_examples > data_enrichment.py
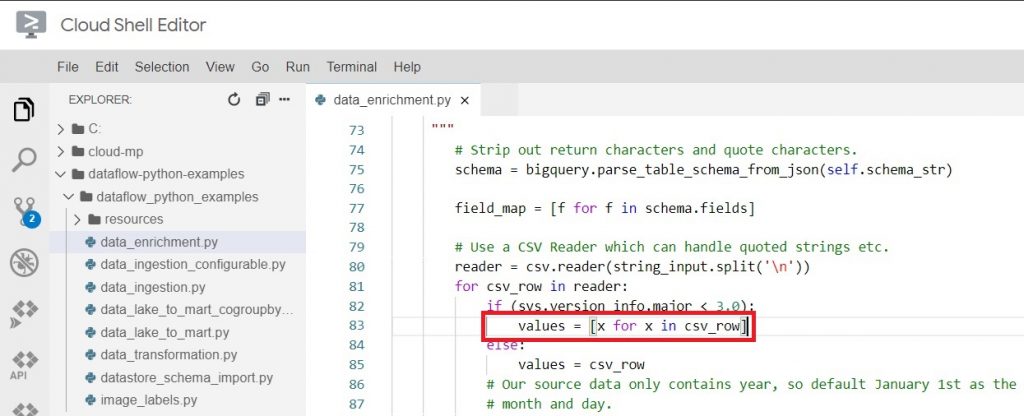
In Line 83 replace
values = [x.decode(‘utf8’) for x in csv_row]
With $ values = [x for x in csv_row]
This code will populate the data in BigQuery.
Now again we’ll run the Dataflow pipeline saved in data_enrichment.py. It will add the workers, and shut down when finished.
python dataflow_python_examples/data_enrichment.py –project=$PROJECT –region=us-central1 –runner=DataflowRunner –staging_location=gs://$PROJECT/test –temp_location gs://$PROJECT/test –input gs://$PROJECT/data_files/head_usa_names.csv –save_main_session

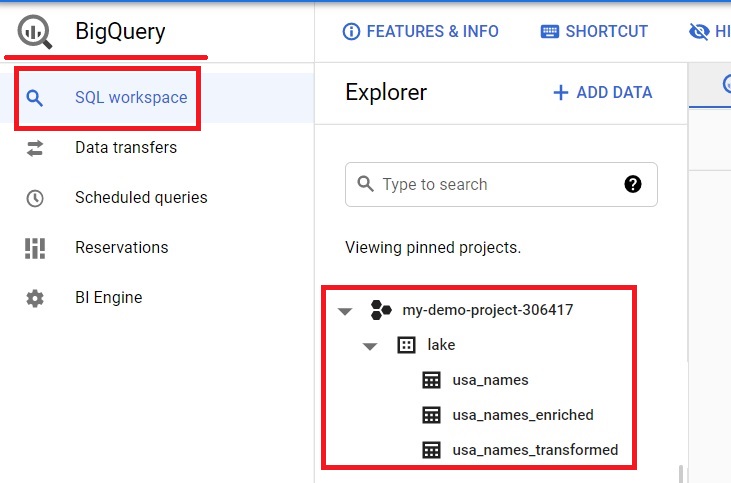
Open Menu > Big Query > SQL Workspace
It will show the populated dataset in lake.
Dataflow > Jobs.
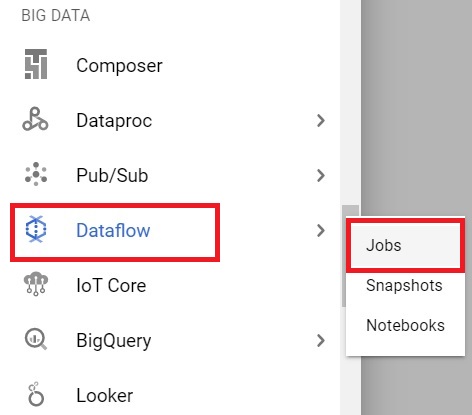
Click on the job which you have done.
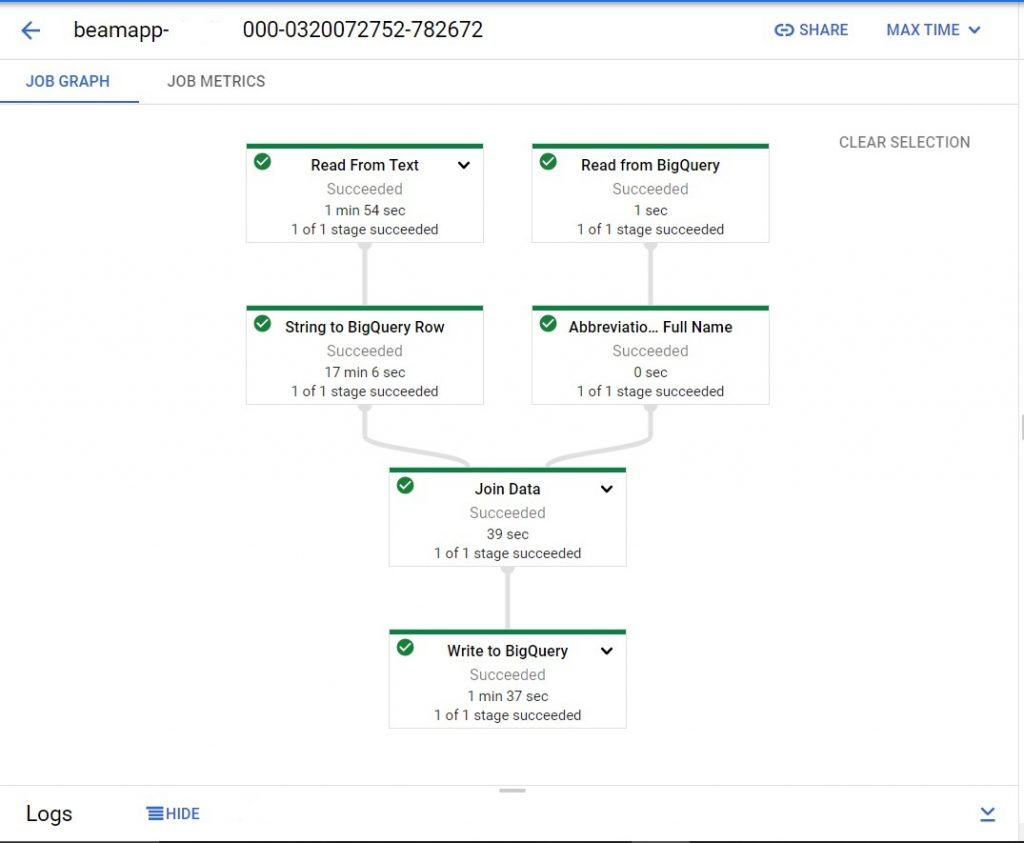
It will show the Data Flow pipeline of the work.
Dataflow and BigQuery for ETL on Google Cloud






