Ensemble Methods Tutorial
Ensemble Methods Tutorial
Ensemble Methods Tutorial, Are you the one who is looking forward to knowing about ensemble methods introduction in Machine Learning? Or the one who is looking forward to knowing the types of ensemble methods or Are you dreaming to become to certified Pro Machine Learning Engineer or Data Scientist then stops just dreaming, get your Data Science certification course with Machine Learning from India’s Leading Data Science training institute.
When you want to buy a replacement car, will you walk up to the primary car shop and buy one supported the recommendation of the dealer? It’s highly unlikely. You would likely browse in search engines where people have posted their reviews and compare different car models, checking for his or her features and costs. you’ll also probably ask your friends and colleagues for his or her opinion. In short, you wouldn’t directly reach a conclusion, but will instead make a choice considering the opinions of people additionally.
Ensemble methods in Machine Learning are used in a similar area. In this blog, we will learn ensemble methods introduction and types of ensemble methods. Follow the below-mentioned ensemble methods tutorial from Prwatech and take advanced Data Science training with Machine Learning like a pro from today itself under 10+ Years of hands-on experienced Professionals.
Ensemble Methods Introduction
Let’s consider we want to buy mobile online. What is the section we have to visit before confirming any mobile model? It’s a review of that product. Initially, you prefer to compare different mobiles, checking for their cost and features. You will also probably ask people in a circle of influence for their opinion. And then you go through the reviews about that product. In short, you don’t directly reach a decision but will decide to consider the opinions of others. Ensemble methods are meta-algorithms that associate a variety of machine learning methods into a single predictive model to decrease variance by means of bagging, decrease bias by means of boosting, or improve predictions by means of stacking.
Similarly, an Ensemble Method is a technique that associates the predictions from multiple machine learning algorithms to get more accurate predictions than any distinct model. The results of machine learning models can be improved by combining the results of different models under concept Ensemble methods.
We can categories the ensemble methods as Simple ensemble methods and Advanced ensemble methods
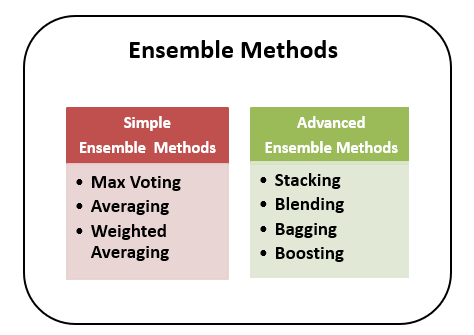
Types of Ensemble Methods
Max Voting:
This method is generally used to solve classification problems. Multiple models can be used to make predictions for individual data points. The forecasts by every model are taken as a ‘vote’. The final prediction will be prediction got from the majority of models.
Averaging:
Here also multiple predictions are done for every data point in the dataset. In this method, the average of predictions from all the models is taken and it is used to make the final prediction.
Weighted Average:
It is nothing but a modified averaging method only. Based on the prediction of each model, the corresponding weights are assigned to that model.
Advanced Ensemble Techniques
Stacking:
It is one of the advanced ensemble learning methods that use predictions from multiple models. Models can be a decision tree, svm, knn, etc. It builds a new model that is used for making predictions on the test set. This method works as follows:
The train set is split into N parts
The base model is fitted on N-1 parts of the dataset and Nth part prediction is done on that basis.
After this, the base model is fitted on the whole train dataset.
Predictions for the test data set are done.
The above procedure is repeated for the next model also. It will generate a new set for train and test data.
The predictions from the train set now act as features to build a new model.
And now this model is used for final prediction.
Blending:
The method follows the same way as stacking. The difference between stacking and blending is that blending uses a validation set only, to make predictions. The validation set and the forecasts are used to build a model that is run on the test set. It works as follows:
The training dataset is divided into training and validation data.
The training dataset is fitted to the model.
Predictions on tests and validations sets are made.
The validation set and its forecasts act new features of a new model.
This model is used for final predictions on the test set.
Bagging:
The bagging method involves combining of various models to get a generalized result. In the case of running models parallel, what will happen if all models are created on the same set of data? They will give almost the same output, as they are getting the same input. So, it will affect the overall accuracy and performance of the model.
This problem can be solved by this technique which is ‘bagging’. It is also called ‘bootstrapping’. Bootstrapping is a sampling technique in which subsets of observations from the original dataset are generated. Bagging, which is also called as Bootstrap Aggregating, uses these subsets (bags) to get a fair idea of the distribution (complete set). The subsets created for bagging may be small compared to the original set.
The original data set is divided into multiple datasets, by selecting observations with replacement.
A base model is created on each of these subsets, which is also called a weak model.
The models are independent of each other. They run in parallel.
The final predictions are the result of joining the forecasts from all the models.
Boosting:
Consider a case where the first model in a set of models predicts any data point incorrectly and then the next model will also predict incorrectly, likewise other models too. So, will joining these predictions ensure better results? Such situations are handled by boosting techniques.
Boosting is a consecutive process, where each succeeding model attempts to correct the errors of the preceding model. The steps followed by the Boosting technique are:
A subset is taken from the main dataset.
Initially, equal weights are assigned to all data points and a base model is created on this subset.
Based on this model predictions for the whole dataset are done. From actual values and predicted values, errors are calculated.
Higher weight is now assigned to the observations which are incorrectly predicted.
Another model is created and is used for the prediction of the dataset.
In this way, multiple models are created. Each model will correct the errors of the previous model.
The final model i.e. strong model is the weighted mean of all the weak models.
In short, the boosting algorithm combines a number of weak models to form a strong learner. Thus, each model boosts the performance of the ensemble, so the overall performance of prediction improves.
We hope you understand the ensemble methods tutorial. Get success in your career as a Data Scientist by being a part of the Prwatech, India’s leading Data Science training institute in Bangalore.






