Working with Dataproc
Prerequisites
GCP account
Open Cloud Console.
Open Menu > Dataproc > Clusters
Click the Cluster.
Click on VM Instances

Click on SSH of master node
Check whether the components is already installed.
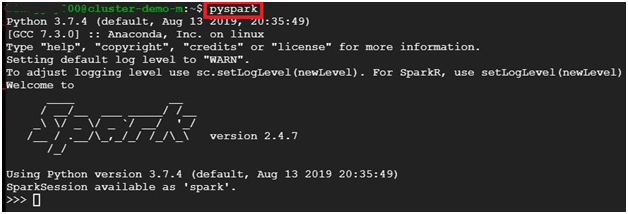
$ pyspark #opens pyspark
To exit press ctrl +d
$ hive #To check hive is available or not
To exit press ctrl +d

$ python –V #to check python version

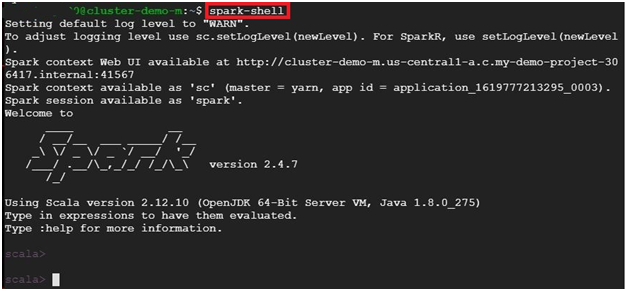
$ spark-shell # opens spark shell
To exit press ctrl +d
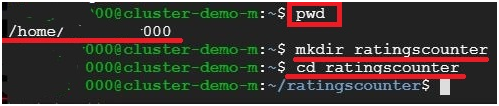
$ pwd #To get path
$ mkdir ratingscounter #making directory named ratingscounter
$ cd ratingscounter #Change the directory into ratingscounter
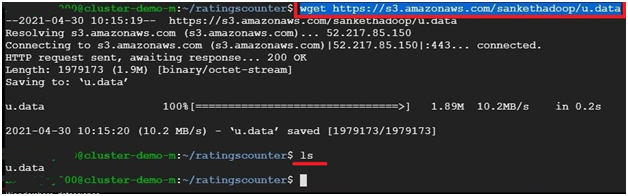
$ wget https://s3.amazonaws.com/sankethadoop/u.data #To get the data for dataproc
$ ls #Display the contents in the directory
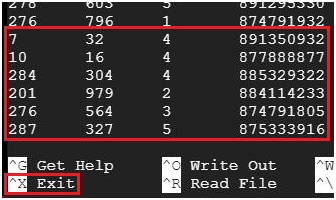
$ nano u.data #open the u.data file.

It will display the content in u.data
To exit press ctrl + x
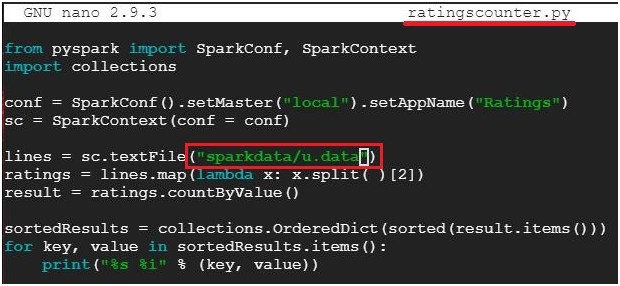
$ nano ratingscounter.py #Creates and opens file ratingscounter.py

Paste the below code into ratingscounter.py file
from pyspark import SparkConf, SparkContext
import collections
conf = SparkConf().setMaster(“local”).setAppName(“Ratings”)
sc = SparkContext(conf = conf)
lines = sc.textFile(“sparkdata/u.data”)
ratings = lines.map(lambda x: x.split( )[2])
result = ratings.countByValue()
sortedResults = collections.OrderedDict(sorted(result.items()))
for key, value in sortedResults.items():
print(“%s %i” % (key, value))
This code is to count the films in each ratings.
NB : if you are changing the name of directory or file, you may have to change it in the file lolcation also.
To exit press ‘ctrl + x’ then press ‘y’ to confirm then ‘Enter’
Create Schema structure
$ hadoop fs -mkdir /user/<userid>/sparkdata #To create directory named sparkdata
$ hadoop fs -put u.data sparkdata #To copy u.data file into sparkdata
$ hadoop fs -ls sparkdata # to check the file is saved or not

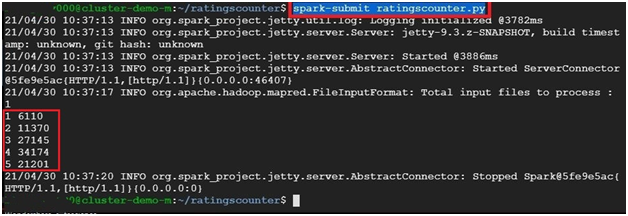
$ spark-submit ratingscounter.py #execute the ratingscounter.py file
It will display the result.
$ cd #change directory
$ mkdir totalspendbycustomer #make directory
$ cd totalspendbycustomer #change directory to totalspendbycustomer

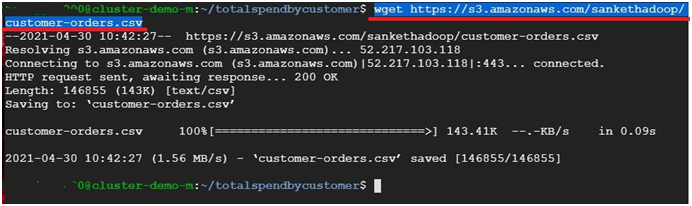
$ wget https://s3.amazonaws.com/sankethadoop/customer-orders.csv #To copy file to disk
$ ls #list the contents in the directory
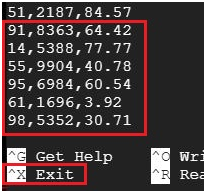
$ nano customer-orders.csv #Open the file customer-orders.csv

Opens the file.
To exit press ctrl +x
$ pwd #Displays the path

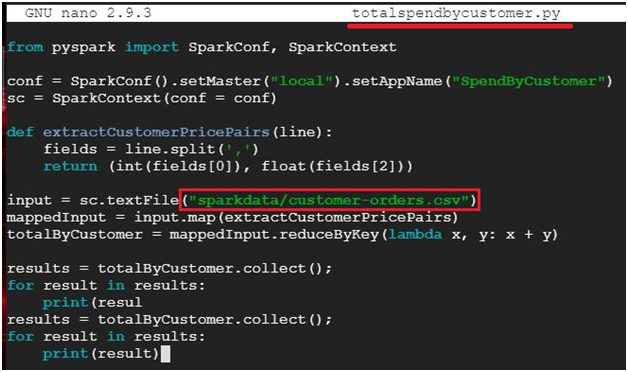
$ nano totalspendbycustomer.py #creates and opens file totalspendbycustomer.py

paste the below code
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster(“local”).setAppName(“SpendByCustomer”)
sc = SparkContext(conf = conf)
def extractCustomerPricePairs(line):
fields = line.split(‘,’)
return (int(fields[0]), float(fields[2]))
input = sc.textFile(“sparkdata/customer-orders.csv”)
mappedInput = input.map(extractCustomerPricePairs)
totalByCustomer = mappedInput.reduceByKey(lambda x, y: x + y)
results = totalByCustomer.collect();
for result in results:
print(result)
This code is to get the amount spent by the customers for movie
NB : if you are changing the name of directory or file, you may have to change it in the file lolcation also.
To exit press ‘ctrl + x’ then press ‘y’ to confirm then ‘Enter’
$ hadoop fs -put customer-orders.csv sparkdata #moves file customer-orders.csv into sparkdata
$ hadoop fs -ls sparkdata # to check the file is saved or not
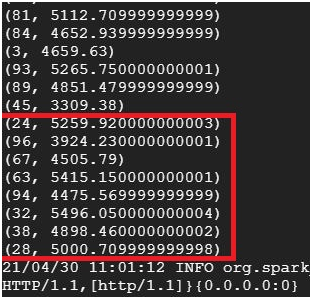
$ spark-submit totalspendbycustomer.py #Execute the file totalspendbycustomer.py

It will display the customer ID and total amount spend by customer
To find popular movies
$ cd #To Change Directory
$ mkdir popularmovies #Make directory named popularmovies
$ cd popularmovies #To change directory into popularmovies

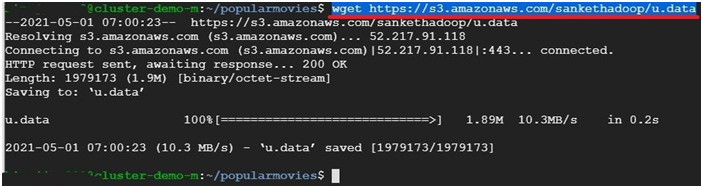
$ wget https://s3.amazonaws.com/sankethadoop/u.data #To copy file to disk
$ nano popularmovies.py #Open file popularmovies.py

In the python file paste the below code.
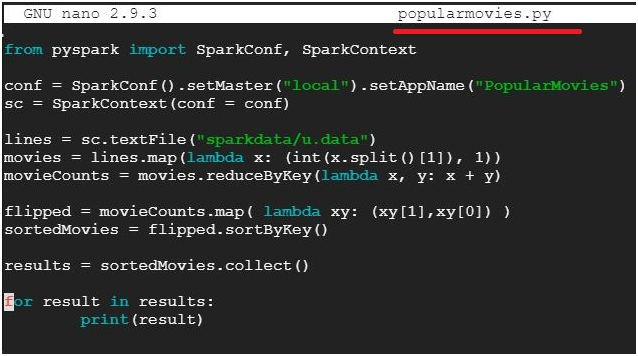
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster(“local”).setAppName(“PopularMovies”)
sc = SparkContext(conf = conf)
lines = sc.textFile(“sparkdata/u.data”)
movies = lines.map(lambda x: (int(x.split()[1]), 1))
movieCounts = movies.reduceByKey(lambda x, y: x + y)
flipped = movieCounts.map( lambda xy: (xy[1],xy[0]) )
sortedMovies = flipped.sortByKey()
results = sortedMovies.collect()
for result in results:
print(result)
To save and exit, Press ‘Ctrl + x’ then ‘y’ then ‘Enter’
$ hadoop fs -put u.data sparkdata #To copy u.data file into sparkdata
$ spark-submit popularmovies.py # To execute popularmovies.py
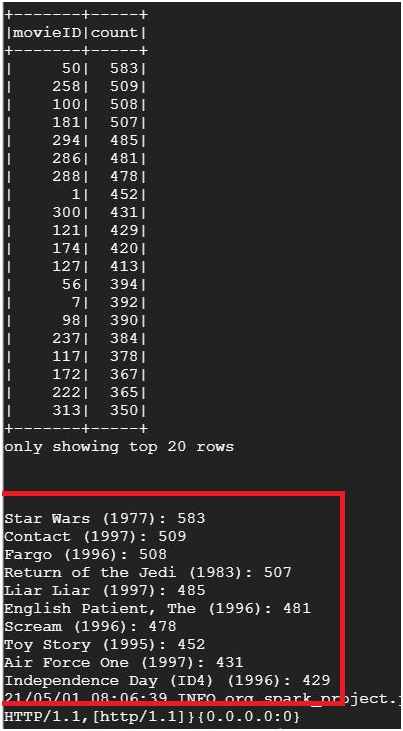
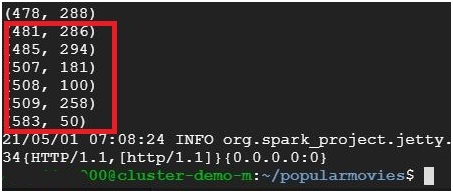
It will show the most popular movie ID and most number of votes.
To find most 10 popular movies
$ cd #To Change Directory
$ mkdir 10popularmovies #Make directory named popularmovies
$ cd 10popularmovies #To change directory into popularmovies

$ wget https://s3.amazonaws.com/sankethadoop/u.item
$ wget https://s3.amazonaws.com/sankethadoop/u.data
It will copy the file into disk.
$ nano u.item #To open the file content

To exit press ctrl+ x
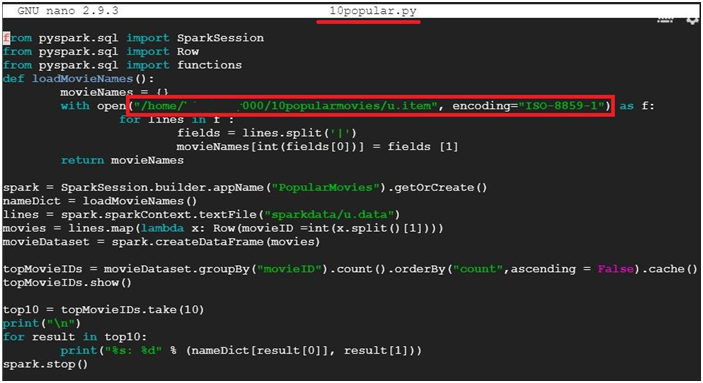
$ nano 10popular.py Create and open the file 10popular.py
Paste the below code.
from pyspark.sql import SparkSession
from pyspark.sql import Row
from pyspark.sql import functions
def loadMovieNames():
movieNames = {}
with open(“/home/<userid>/10popularmovies/u.item“, encoding=”ISO-8859-1”) as f:
for line in f:
fields = line.split(‘|’)
movieNames[int(fields[0])] = fields [1]
return movieNames
spark = SparkSession.builder.appName(“PopularMovies”).getOrCreate()
nameDict = loadMovieNames()
lines = spark.sparkContext.textFile(“sparkdata/u.data”)
movies = lines.map(lambda x: Row(movieID =int(x.split()[1])))
movieDataset = spark.createDataFrame(movies)
topMovieIDs = movieDataset.groupBy(“movieID”).count().orderBy(“count”,ascending = False).cache()
topMovieIDs.show()
top10 = topMovieIDs.take(10)
print(“\n”)
for result in top10:
print(“%s: %d” % (nameDict[result[0]], result[1]))
spark.stop()
Change the highlighted area as your directory
$ hadoop fs -put u.data sparkdata #To copy u.data file into sparkdata
$ hadoop fs -ls sparkdata #To display the content
$ spark-submit 10popular.py #To execute the 10popular.py file

It will display the most popular 10 movies.