Working With Dataflow using BigQuery
Cloud Dataflow: Building Data Processing Pipelines
Cloud Dataflow offers a powerful platform for building scalable and reliable data processing pipelines within Google Cloud. These pipelines enable organizations to ingest, transform, and analyze large volumes of data in real-time, providing valuable insights and driving informed decision-making.
At its core, Cloud Dataflow simplifies the development and management of data pipelines by abstracting away the complexities of distributed computing infrastructure. Developers can focus on defining the data processing logic using familiar programming languages and libraries, while Dataflow handles the underlying infrastructure provisioning, scaling, and optimization.
Prerequisites
GCP account
Open Console.
Open Menu > BigQuery
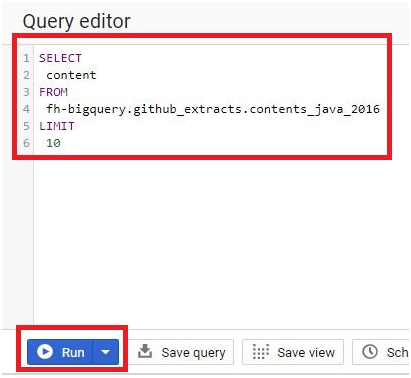
In Query Editor, Paste the below query.
SELECT
content
FROM
fh-bigquery.github_extracts.contents_java_2016
LIMIT
10
Click Run.
It will display the results.
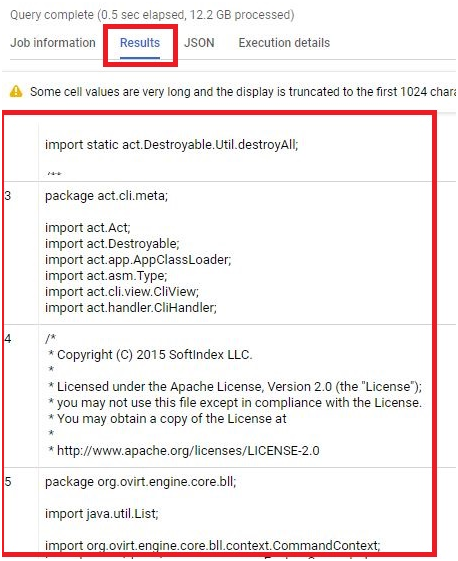
Paste the below query.
SELECT
COUNT(*)
FROM
fh-bigquery.github_extracts.contents_java_2016
Click Run.
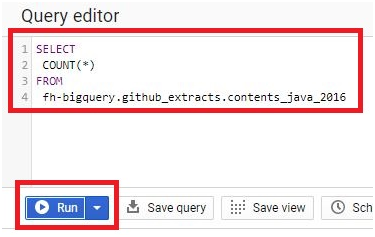
It will give the query result.
Click on activate cloud shell
git clone https://github.com/GoogleCloudPlatform/training-data-analyst

ls

Create bucket in console. Give bucket name as same as the project ID
In shell, execute the below command
BUCKET=”<bucket-name>”
echo $BUCKET

cd training-data-analyst/courses/data_analysis/lab2/python
ls
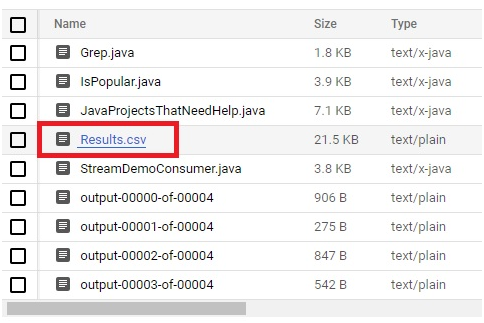
The files will be displayed

nano JavaProjectsThatNeedHelp.py

It will open the file. Ctrl + x to exit
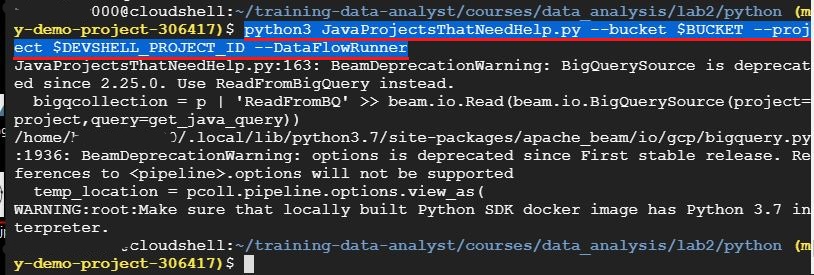
python3 JavaProjectsThatNeedHelp.py –bucket $BUCKET –project $DEVSHELL_PROJECT_ID –DataFlowRunner
Go to DataFlow > Jobs The jobs will be running
Open the running job
See the dataflow running
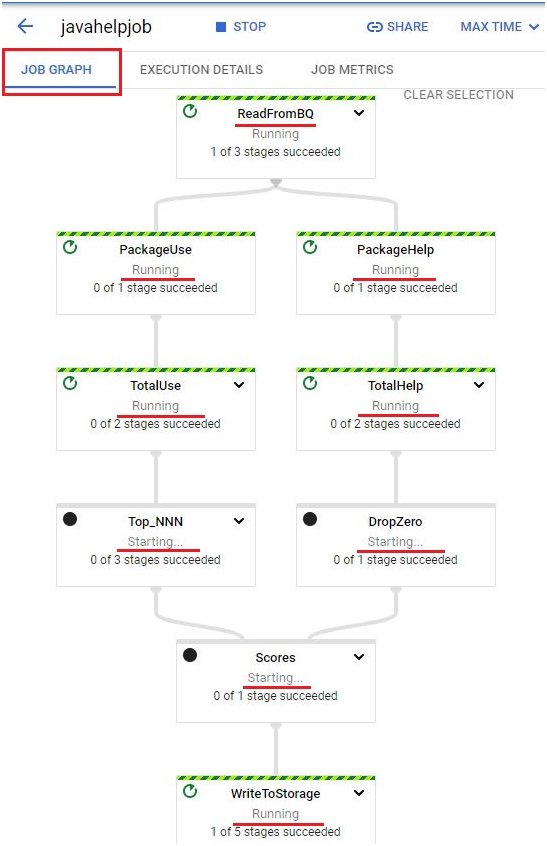
After running, It will shown as succeeded

After execution, Go to bucket.

Open javahelp/ folder
The Result will be stored in it.